- The paper demonstrates that latent causal variables and DAGs can be identified under nonparametric mixing without requiring explicit intervention knowledge.
- It leverages third-order derivative properties of the log-likelihood to uniquely orient DAG structures, surpassing limitations of second-order methods.
- A practical variational inference algorithm using a VAE framework validates the theory through simulation studies across complex, realistic environments.
Causal Representation Learning from General Environments under Nonparametric Mixing
Overview
The paper "Causal Representation Learning from General Environments under Nonparametric Mixing" (2604.23800) investigates the identifiability of latent causal variables and their underlying directed acyclic graph (DAG) structure from observed variables subjected to an unknown, nonparametric, and potentially highly nonlinear mixing function. The study critiques the limitations of prevailing approaches that rely on strong assumptions about the type of interventions, the coupling patterns of interventions, and linearity constraints on the causal or mixing models. It provides a comprehensive identifiability theory for settings far broader than those captured by previous works, introduces new mathematical tools leveraging higher-order derivatives, and proposes a practical variational inference method to recover both the latent variables and the DAG structure.
Problem Setting and Desiderata
The core objective of causal representation learning (CRL) is to discover latent variables Z and their causal structure GZ—often a DAG—from raw observations X linked via an unknown mixing function g. Conventional approaches make strong assumptions about either the intervention scheme (such as only single-node or hard interventions) or the mixing function (e.g., linearity). However, these are frequently violated in realistic data regimes, where interventions may be soft, targets may be unknown, and environments exhibit complex, multi-node shifts.
This work posits three critical desiderata for practical CRL:
- No restriction to hard interventions: Both soft and hard interventions should be included.
- No requirement for intervention target knowledge: The intervention targets and their coupling are not assumed to be known.
- No restriction to single-node interventions: Multi-node and single-node interventions are both admissible.
By formalizing these desiderata, the study defines a general environment scenario, suitable for numerous real-world contexts such as genomics and robotics, where explicit knowledge or control of intervention targets is often unavailable.
Theoretical Results: Identifiability Under General Environments
The central theoretical advance is demonstrating identifiability of the latent DAG and the causal representations under a substantially relaxed set of assumptions. Specifically, the work considers a SEM over latent Z with either additive noise models (ANMs) or heteroscedastic noise models (HNMs), coupled with a nonparametric mixing g. Observed data is available from multiple environments, each inducing changes in causal mechanisms (i.e., interventions), but with no restriction on the exact nature or targets of these interventions.
A crucial insight is that prior efforts using only second-order derivatives (e.g., for conditional independence testing in a Markov network framework) are inherently insufficient to fully orient the DAG structure. Instead, the paper leverages properties of third-order derivatives of the log-likelihood of the latent distribution—enabled by variation across multiple environments—to distinguish causal directions and uniquely identify sink nodes in the DAG.
The identifiability result shows that, under reasonable sufficient change conditions (expressed as linear independence constraints over derivatives up to third order) and standard faithfulness and regularity conditions, it is possible to recover:
- The latent DAG GZ up to node permutation, with full orientational fidelity.
- Each latent variable Zi up to mixing with its "surrounding parents" but not arbitrary mixing with all latent variables.
These results match or extend previous identifiability theorems that required more restrictive assumptions, especially regarding prior knowledge of intervention targets or linearity of mixing.
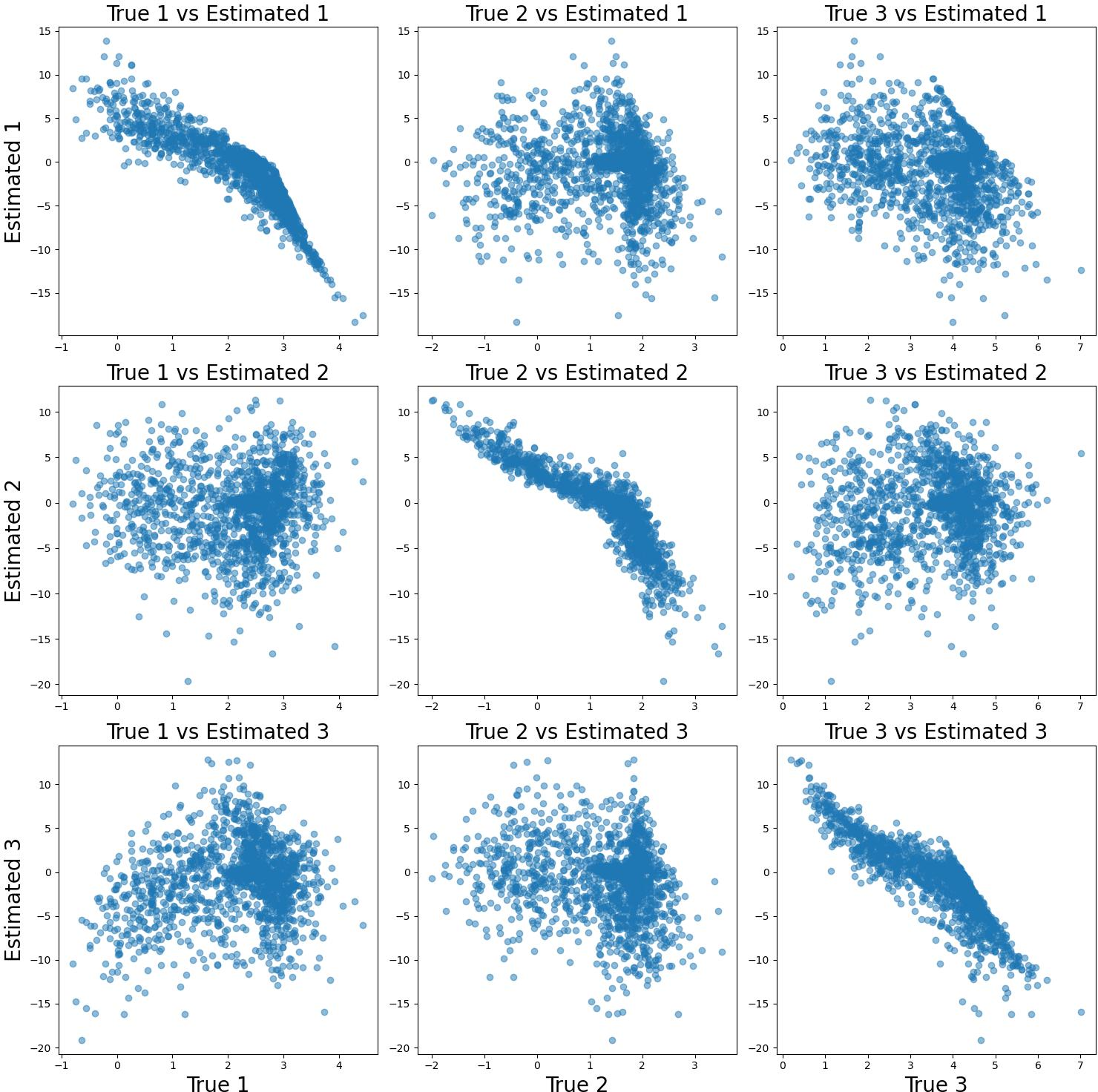
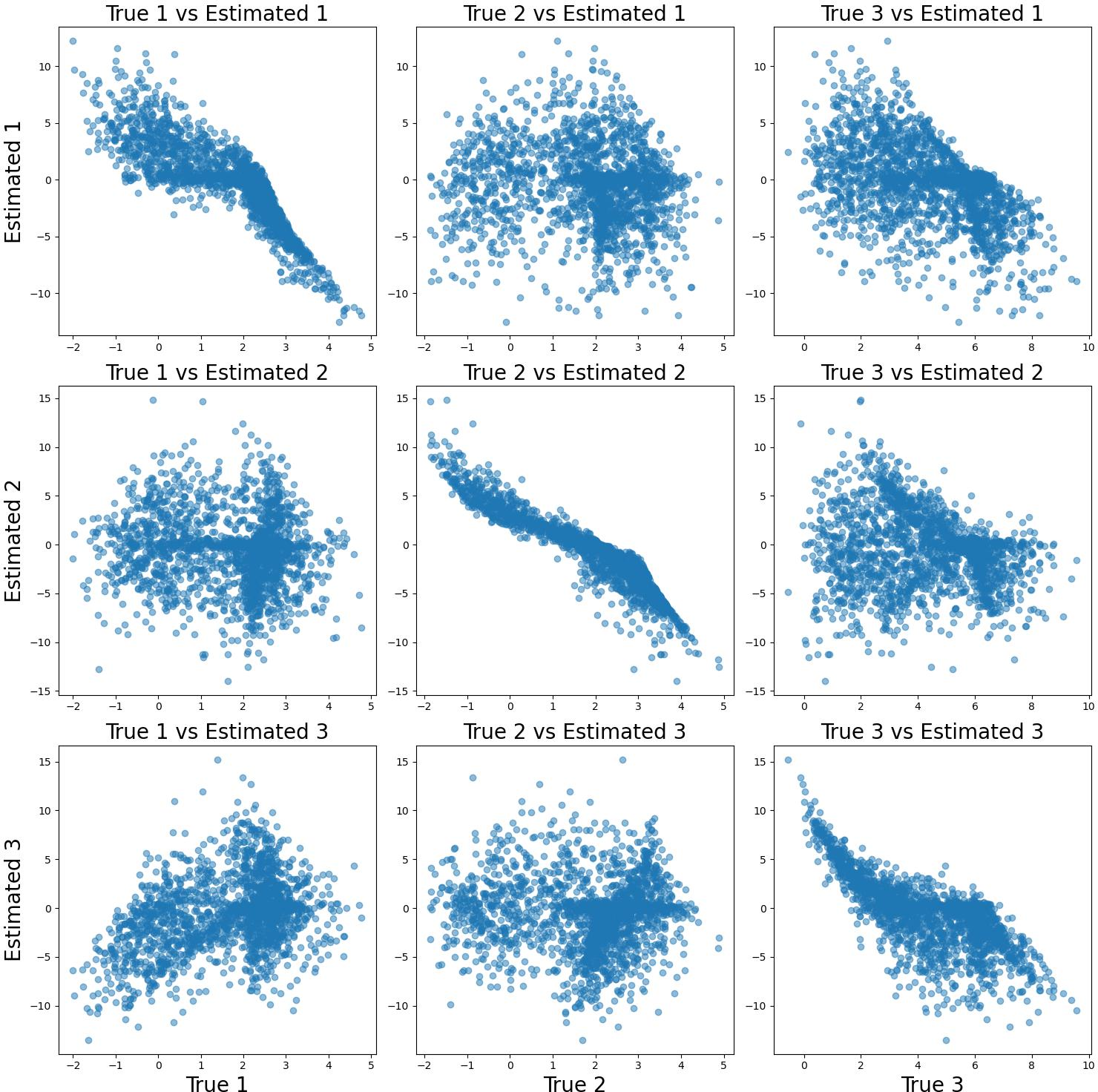
Figure 1: The recovered latent variables Z^ contrasted with the ground-truth latents Z in two scenarios, illustrating successful recovery up to confounding sets permitted by the theory.
Role of Third-Order Derivatives
The technical advance is leveraging the vanishing third mixed partial derivatives of the log-likelihood for sink nodes, which are derived to be zero under the ANM/HNM assumptions. This provides an inductive handle to order and orient the nodes of the DAG during iterative estimation, a capability not possible with purely second-order information, which remains ambiguous due to symmetry.
Practical Estimation Algorithm
The paper translates its identifiability theory into a practical estimation framework based on a variational autoencoder (VAE) employing a mixture of MLP-based encoder/decoder structures and a DAG-structured prior. The estimation is conducted in an iterative manner: at each step, the estimated adjacency matrix identifies sink nodes and their parents based on the network structure discovered in previous rounds, subject to constraints that enforce DAG invariance and edge sparsity.
- The ELBO is used as the principal objective, supplemented with sparsity and regularity penalties on the adjacency matrix.
- Model selection for the number of latent variables is performed by comparing ELBO values.
- The approach accommodates nonparametric latent mapping and can flexibly handle both ANM and HNM-structured priors.
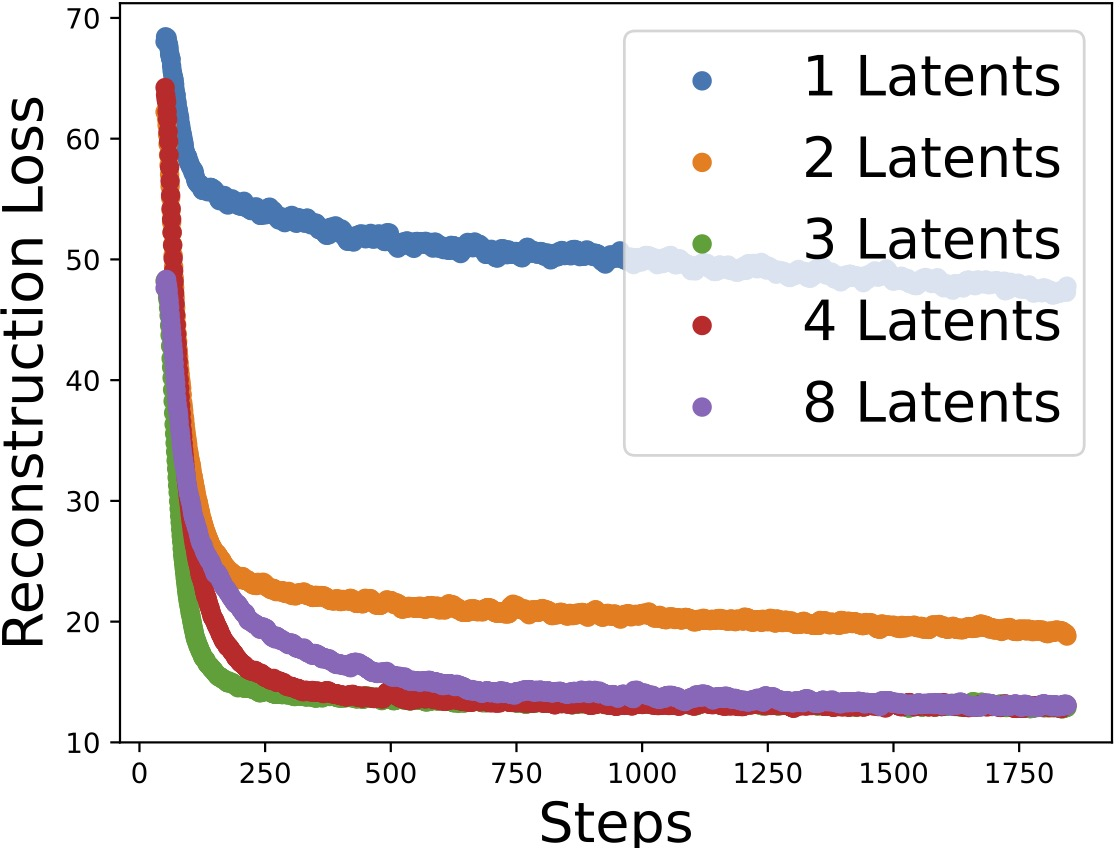
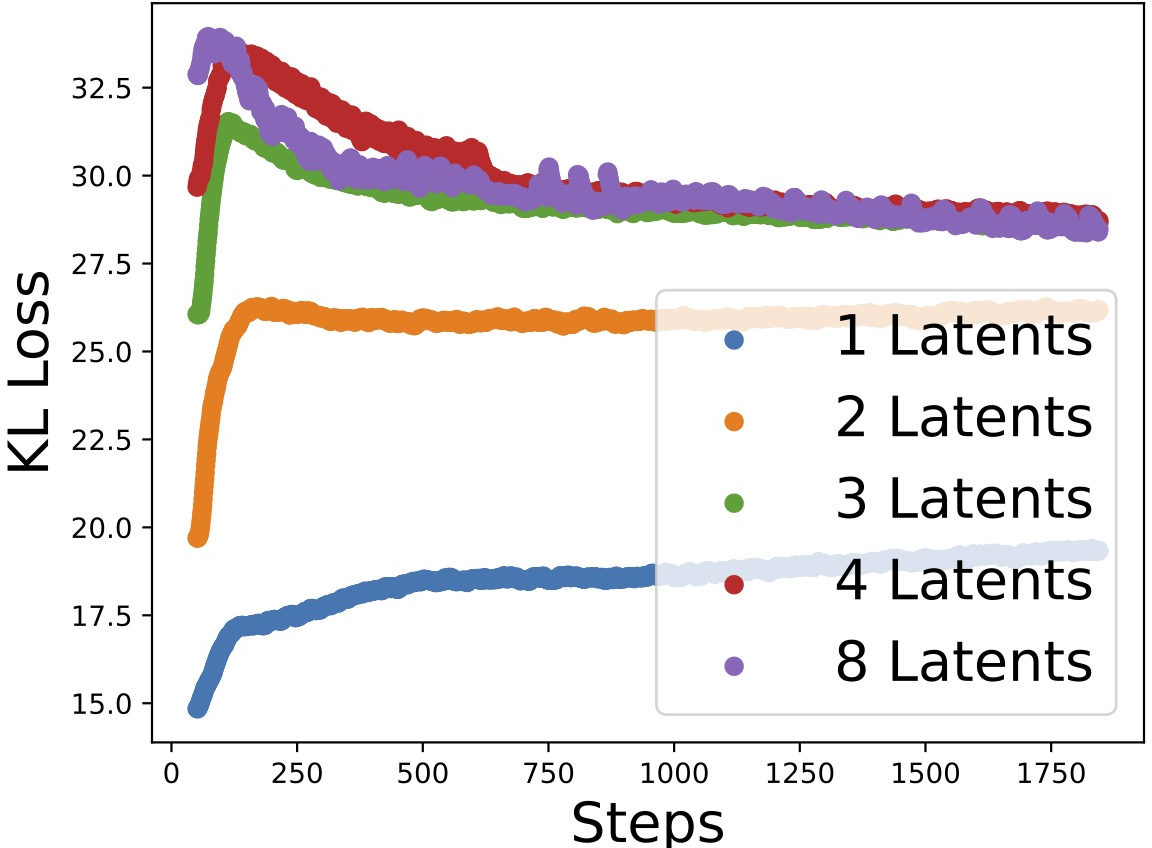
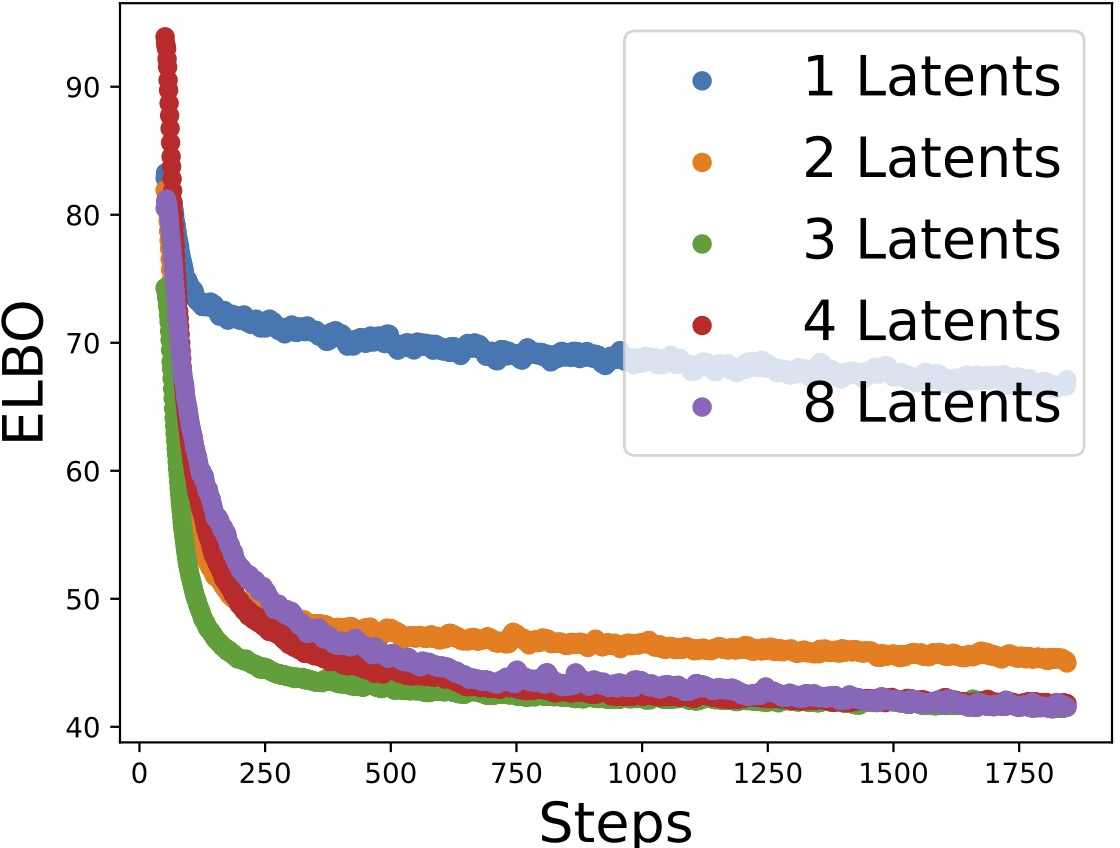
Figure 2: Losses versus training steps as the number of estimated latent variables varies, demonstrating that correct model selection is achievable via the ELBO.
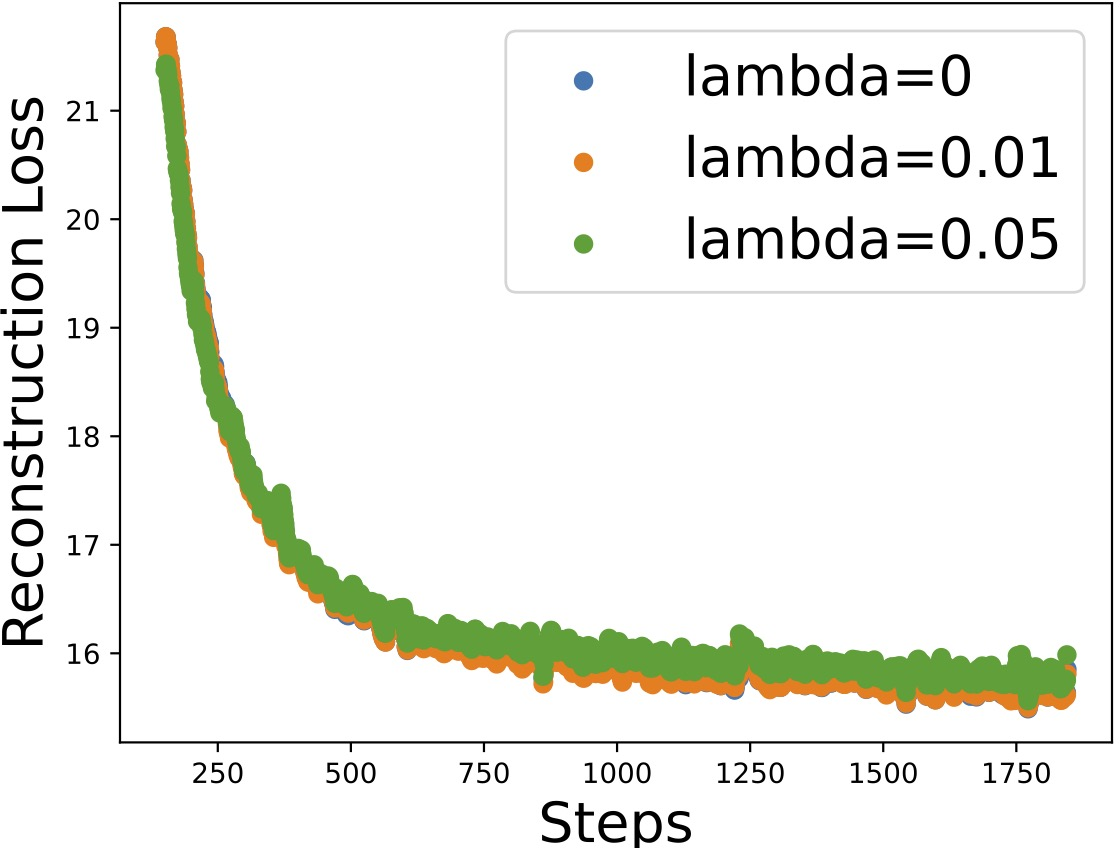
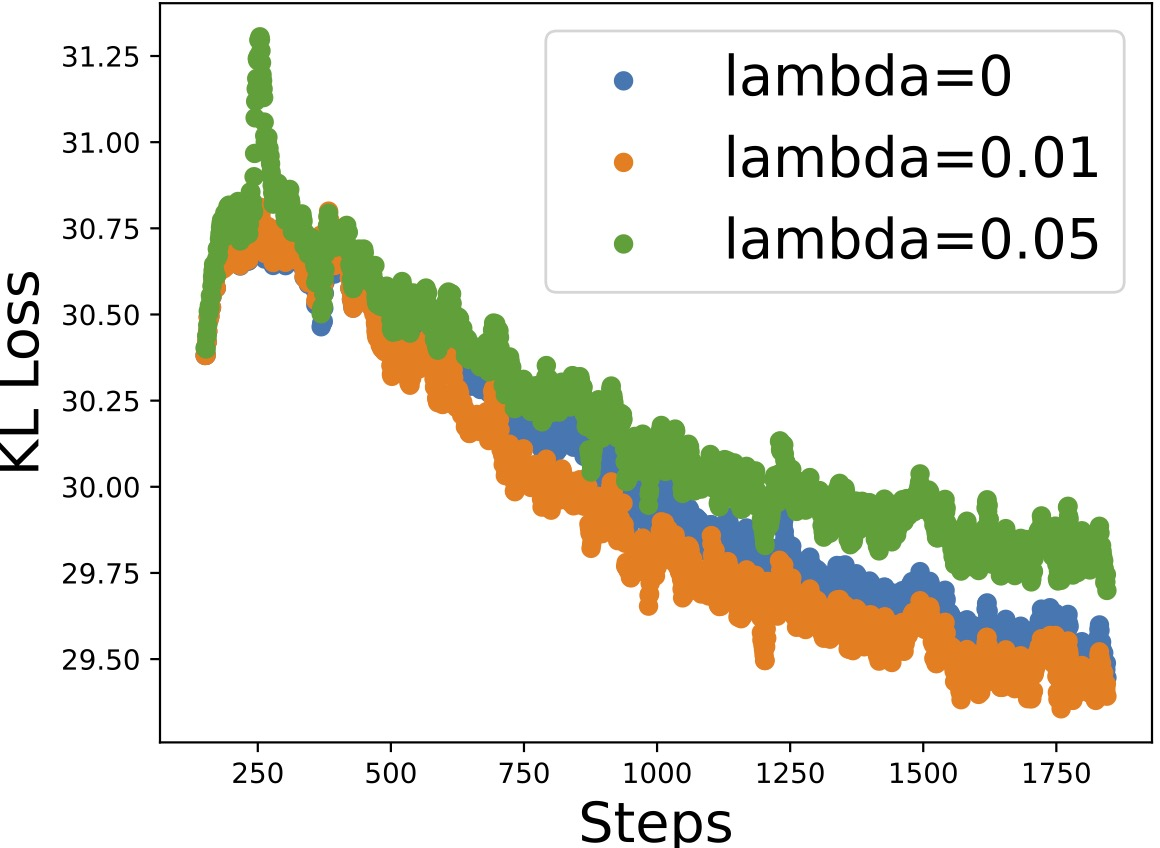
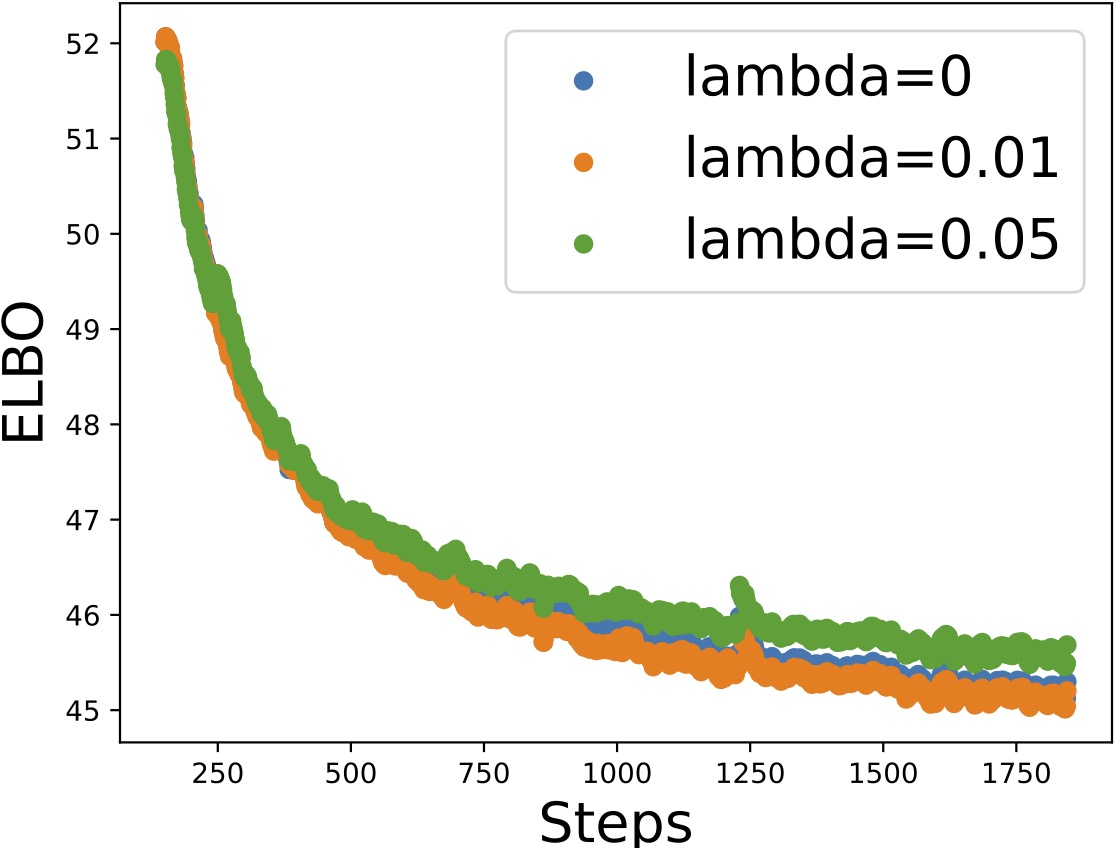
Figure 3: ELBO and related losses for different values of the regularization parameter GZ0, showing that appropriate selection enables the recovery of sparse, faithful graphs without overfitting.
Empirical Evaluation
The method is validated through simulation studies in which the true latent models are known and observed variables are generated via nonparametric MLP-based mixing. Results validate several key points:
- The latent variables are recovered up to the theoretically permitted indeterminacies.
- The causal graph over latents is correctly oriented and structurally faithful.
- Numerical results align with the inductive logic of the identifiability theory (see Figure 1).
Implications and Future Directions
Practical Implications
This research significantly expands the field of practical applicability for CRL in complex, uncontrolled, or poorly characterized environments. It enables causal discovery from raw data in settings well beyond the reach of approaches reliant on restrictive interventions, knowledge of latent manipulation targets, or linearity. This has direct relevance in genomics, neuroscience, robotics, and any domain where interventions are soft or latent and direct manipulation is infeasible.
Theoretical Implications
By introducing the use of third-order derivative information, the paper highlights a new methodological toolkit for identifying causal DAGs under severe observational bottlenecks. The results suggest that further exploration of higher-order statistical properties—facilitated by environmental diversity—may powerfully enhance both identifiability and estimation in latent variable causal models.
Potential Future Work
Future research directions include:
- Extending the methodology to settings with non-Gaussian or heavy-tailed latent noise, further relaxing the current Gaussian assumption.
- Application to high-dimensional real-world data where the number of latents may be large and environmental variability subtle.
- Integrating more explicit model selection strategies, automatic hyperparameter optimization, and scalability enhancements for deep structure discovery.
Conclusion
This study establishes, for the first time, the identifiability of full latent DAGs in general environments with nonparametric mixing and nonlinear noise models without requiring strong intervention assumptions or knowledge of intervention targets. This is enabled by a novel use of higher-order partial derivatives and implemented via variational inference. The work closes a key theoretical gap in causal representation learning and presents a practical approach for structure discovery in complex, realistic data regimes.

