- The paper introduces a novel dialogue-style framework that converts MARL trajectories into language prompts for unified, multi-task decision making.
- The paper details a two-phase training pipeline combining supervised fine-tuning and GRPO to align preferences and effectively reduce OOD action risks.
- The paper demonstrates that a single DLM instance achieves performance parity or superiority over state-of-the-art value-based offline MARL methods, ensuring robust and efficient generalization.
Decision LLMs for Offline Multi-Agent Sequential Decision Making: An Expert Synthesis
Introduction and Motivation
Offline Multi-Agent Reinforcement Learning (MARL) contends with several core obstacles: rigid policy architectures that tightly couple observation and action representations with ground-truth task-specific schemas, poor scalability to heterogeneous input/output spaces, limited generalization in multi-task settings, and exacerbated out-of-distribution (OOD) action risks, especially under centralized training with decentralized execution (CTDE) protocols. Recent progress in LLMs has shown that sequence modeling can bridge varied data modalities, yet direct LLM application to sequential decision-making has previously suffered from goal misalignment and inability to encode environment dynamics. "DLM: Unified Decision LLMs for Offline Multi-Agent Sequential Decision Making" (2604.23557) directly addresses these limitations by designing a Dialogue-style LLM (DLM) that casts MARL as multi-turn dialogue prediction, with a two-stage offline pipeline for robust preference alignment and OOD mitigation.
DLM Pipeline Overview
DLM's core innovation is to model multi-agent decision processes as language—verbalizing observation-action trajectories into a format compatible with LLM tokenization, enabling flexible parameter sharing across task and agent heterogeneities. Training proceeds in two offline phases, detailed as follows:
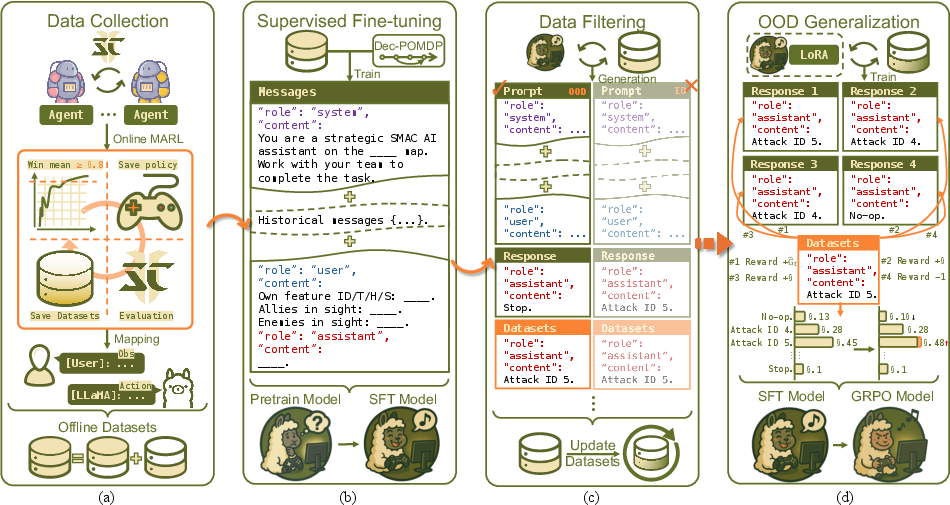
Figure 1: A four-step DLM training pipeline: offline MARL trajectories are mapped into language dialogues and split for SFT and GRPO; fine-tuning yields DLM-SFT, which is further trained with OOD-focused executability rewards, producing DLM-GRPO.
- Data Preparation and Dialogue Representation: Observations and actions are transformed into structured dialogue-style prompts, yielding a dataset (ChatSMAC format) that encodes both agent-centric and inter-agent context as text. This mapping naturally abstracts SMAC's multivariate features, as shown in Figure 2.
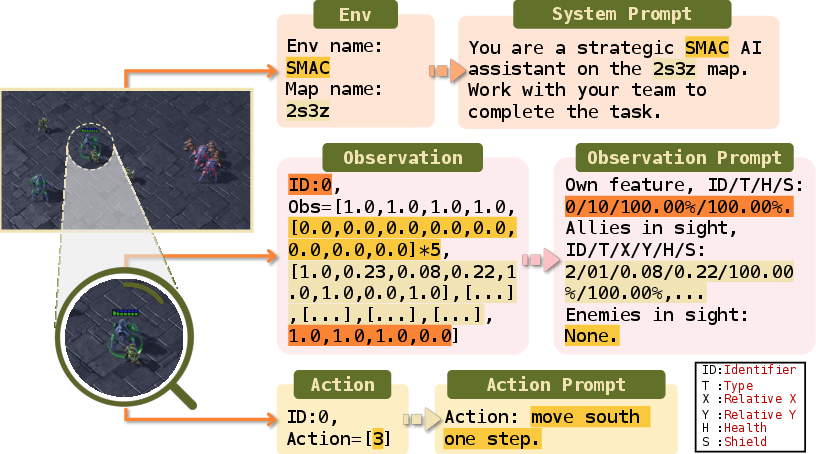
Figure 2: Mapping from raw SMAC observations/actions to dialogue-style prompts, highlighting the correspondence between environment states and natural language representations.
- Supervised Fine-Tuning (SFT): A pre-trained LLaMA-3.2-1B model is fine-tuned on half of the dialogue-encoded offline dataset, aligning the base LLM with the decision domain without explicit value function targets.
- OOD Filtering: The SFT-tuned model (DLM-SFT) is rolled out on the remaining data; samples where DLM-SFT proposes actions differing from the dataset (or which violate executability constraints) are flagged as OOD-prone.
- Preference-Based Alignment (GRPO): GRPO is applied on the filtered subset, using a reward signal built from normalized return-to-go, executability constraints, and trajectory-level preferences, driving the model towards feasible, robust policies without environment interactions.
Centralized Training, Decentralized Execution, and Dialogue-Style Modeling
The DLM architecture encodes full agent histories as chat-based sequences during training—exposing inter-agent dependencies and facilitating trajectory-level temporal modeling. At inference, agents operate with only their local dialogue histories, supporting strict decentralization (Figure 3).
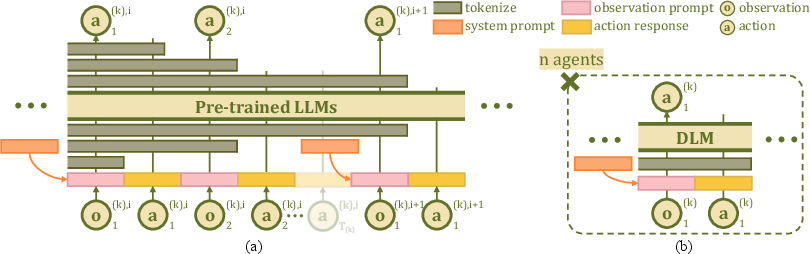
Figure 3: (a) Centralized DLM training on full dialogue-style trajectories with inter-agent information, (b) decentralized inference where each agent acts from its own local trajectory without global knowledge.
This design explicitly solves several critical problems seen in conventional BC and sequence-modeling-based MARL:
- Representation mismatch is mitigated as heterogeneous features are canonicalized in text, avoiding scenario-specific embeddings.
- Temporal credit assignment is strengthened by autoregressive modeling, capturing dependencies across long action-observation histories.
- CTDE compatibility is ensured—the model learns with global context but samples actions using only locally-available information.
DLM was benchmarked on a comprehensive suite of tasks from SMAC, SMACv2, and Level-Based Foraging (LBF). The two-stage DLM exhibits consistent win-rate superiority or parity with state-of-the-art value-based offline MARL algorithms—such as CFCQL, OMIGA, MACQL, and TD3+BC—and clearly surpasses other LLM sequence models, including Gato, MADT, and SayCan. Only a single DLM instance is trained for all tasks, demonstrating unified generalization.
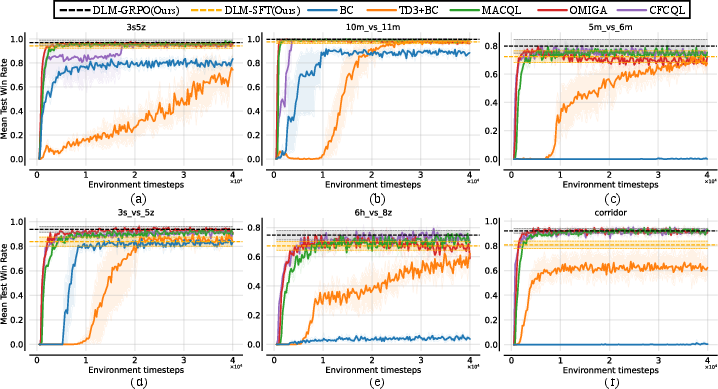
Figure 4: Task-wise win-rate comparison on selected SMAC environments (easy to super hard), where DLM-GRPO matches or exceeds value-based offline MARL baselines.
The preference optimization stage (GRPO) yields pronounced reductions in OOD rates across all tasks, as quantified by the frequency of invalid/executable action samples (Figure 5).
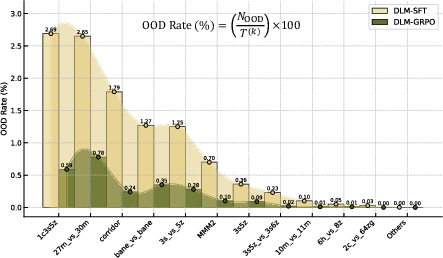
Figure 5: DLM-GRPO sharply decreases OOD action rates after preference optimization, especially in difficult scenarios where the space of feasible behaviors is sparse.
Further experiments confirmed:
- Dialogue-style sequence modeling affords enhanced zero-shot generalization to entirely unseen task configurations (especially outpacing Gato and MADT on communication- and composition-heavy MARL tasks).
- The computational footprint of DLM is lower than per-task value-based MARL: a single run efficiently covers all tasks, in contrast to baselines that require independent runs/per-task optimization.
- Detailed ablations show that simply increasing dataset size (doubling SFT trajectories) fails to resolve OOD errors or match the gains from preference alignment.
Theoretical and Practical Implications
The DLM architecture achieves several notable theoretical and practical properties:
- Unified parametrization: Heterogeneous agents and tasks are integrated via natural language encoding, sidestepping the limits of hard-coded feature extraction or task-specific models.
- Robust OOD generalization: Preference-based refinement on filtered dialogue samples improves action feasibility without online rollouts.
- Transfer and scalability: The model supports zero-shot adaptation to structurally novel MARL scenarios, a necessary criterion for practical deployment in real-world multi-agent systems.
- Training efficiency: DLM is more resource-efficient than value-based MARL methods when scaling across many tasks, thus lowering the barrier to large-scale sequential decision research.
Limitations and Future Directions
Current DLM experiments operate within the confines of simulated environments (SMAC, SMACv2, LBF). Further scaling to real-world applications (e.g., robotics, autonomous vehicle fleets) will require:
- Enhanced computational scaling (LLMs with higher capacity, efficient fine-tuning strategies).
- Further robustness to extreme OOD states (e.g., adversarial perturbations or highly nonstationary environments).
- Potential incorporation of on-policy updates if tight real-world constraints allow, leveraging DLM's flexible text interface.
Promising directions include combinatorial generalization to much larger agent groups, cross-domain adaptation, and integration with explicit reasoning via tool-use or symbolic augmentation.
Conclusion
DLM constitutes a scalable, robust sequence modeling framework for offline multi-agent cooperative sequential decision making. By casting the Dec-POMDP as a natural language dialogue task, DLM achieves high data efficiency, strong robustness under OOD conditions, and seamless multi-task adaptation with a single parameter set. These findings point towards LLM-based dialogue architectures as a central candidate for unifying generalization and coordination in MARL going forward.