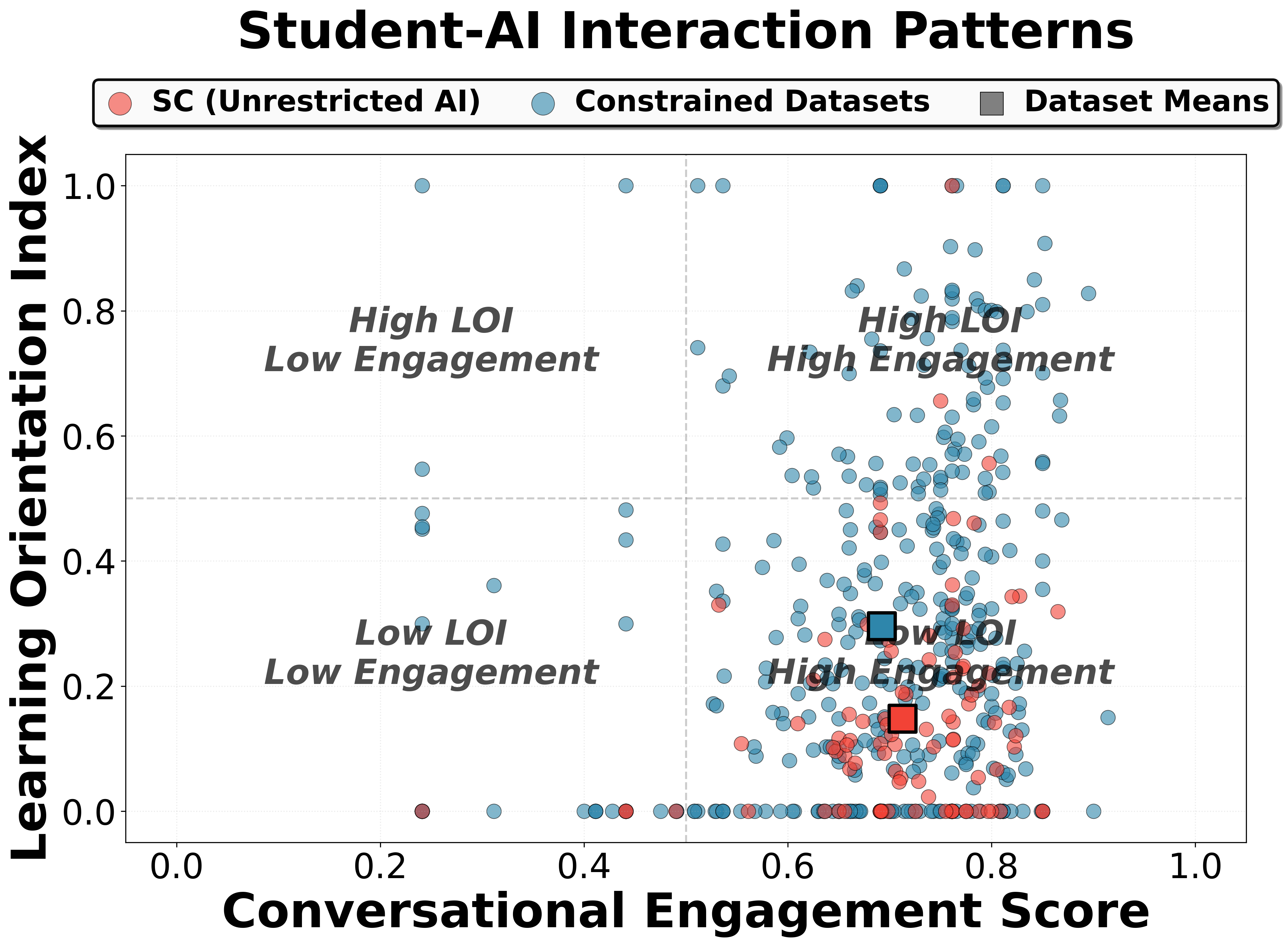
- The paper introduces six novel metrics (CES, LOI, SRS, ADR, CMI, UCI) for quantitatively evaluating student–AI dialogues' pedagogical alignment.
- Results from 12,650 messages reveal that free-access platforms drive answer-extraction, while constrained deployments trigger crisis-driven, deadline-focused use.
- Implications stress that deployment context, rather than LLM design, determines student behavior, urging adaptive, context-aware strategies for educational AI.
Quantifying Pedagogical Misalignment in Student–AI Dialogue: Insights from “Your Students Don't Use LLMs Like You Wish They Did”
Introduction
The paper “Your Students Don't Use LLMs Like You Wish They Did” (2604.23486) presents a computational analysis of student interactions with educational LLM-based systems, systematically dissecting the gap between intended pedagogical use and actual student behavior. The authors develop and validate six interpretable metrics for behavioral evaluation in student–AI dialogues, spanning aspects such as engagement, learning orientation, scaffolding resistance, assignment dependency, crisis-mode behaviors, and usage concentration. Empirical findings—derived from 12,650 messages across 500 conversations in multiple STEM courses—demonstrate that deployment context overwhelmingly determines student use, with free access promoting answer-extraction and constrained/optional deployments resulting in deadline-driven, crisis-oriented interaction.
Metrics for Behavioral Evaluation in Student–AI Dialogue
A primary contribution of this work is the introduction of six computational metrics, all designed for automated, scalable, cross-system behavioral evaluation:
- Conversational Engagement Score (CES): Captures dialogue depth and continuity by weighting turn count, follow-up, contextual reference, and acknowledgment rates.
- Learning Orientation Index (LOI): Classifies turns as exploratory or solution-seeking, quantifying progression from productive inquiry to transactional answer-extraction.
- Scaffolding Resistance Score (SRS): Measures how often students bypass or resist pedagogical scaffolding, including Socratic dialogue or hints.
- Assignment Dependency Ratio (ADR): Detects assignment-driven usage using both heuristics and LLM prompting to identify copy–paste and problem-set patterns.
- Crisis Mode Indicator (CMI): Tracks behavioral shifts around assessment deadlines using temporal and linguistic features associated with panic and minimal engagement.
- Usage Concentration Index (UCI): Quantifies crisis-driven platform usage through Gini-based measures of temporal clustering.
Metric validation compares zero-shot LLM classifications (GPT-4.1-mini and GPT-5) with expert human annotation. Turn-by-turn analysis via GPT-5 shows correlations with human ratings (r=0.59–$0.72$ for core behavioral metrics), approaching human inter-rater agreement.
Behavioral Patterns Revealed by the Metrics
A core empirical finding is the systematic misalignment between intended system design (conversational pedagogical support) and actual usage:
Temporal Dynamics: Crisis-Driven Use
Temporal analysis further illuminates the misalignment between institutional hopes and student reality:
- High Concentration Around Deadlines: Optional pedagogical tools (e.g., DrMattTabolism, DrNucleicAlice, MEDS2004, OLiMent) see a mean UCI of 0.681, with the majority of usage tightly clustered around exam periods.
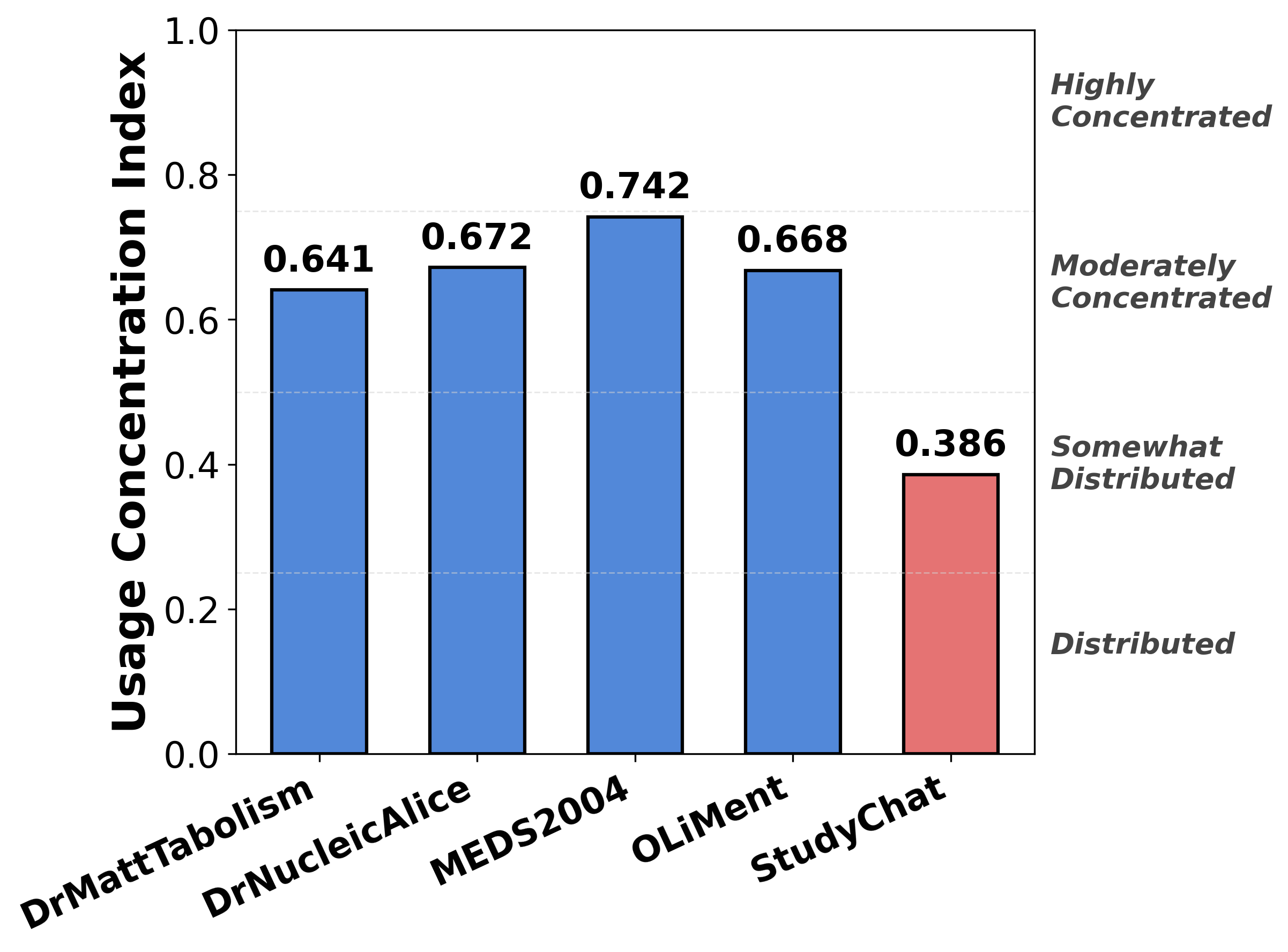
Figure 2: Usage concentration across constrained platforms (blue) vs. the StudyChat dataset (red), with constrained data showing substantially higher concentration.
- Crisis Mode Behavior: CMI captures large drops in engagement and surge in urgent requests during deadlines. Up to 59% of semester-long interactions can occur in a single exam week.
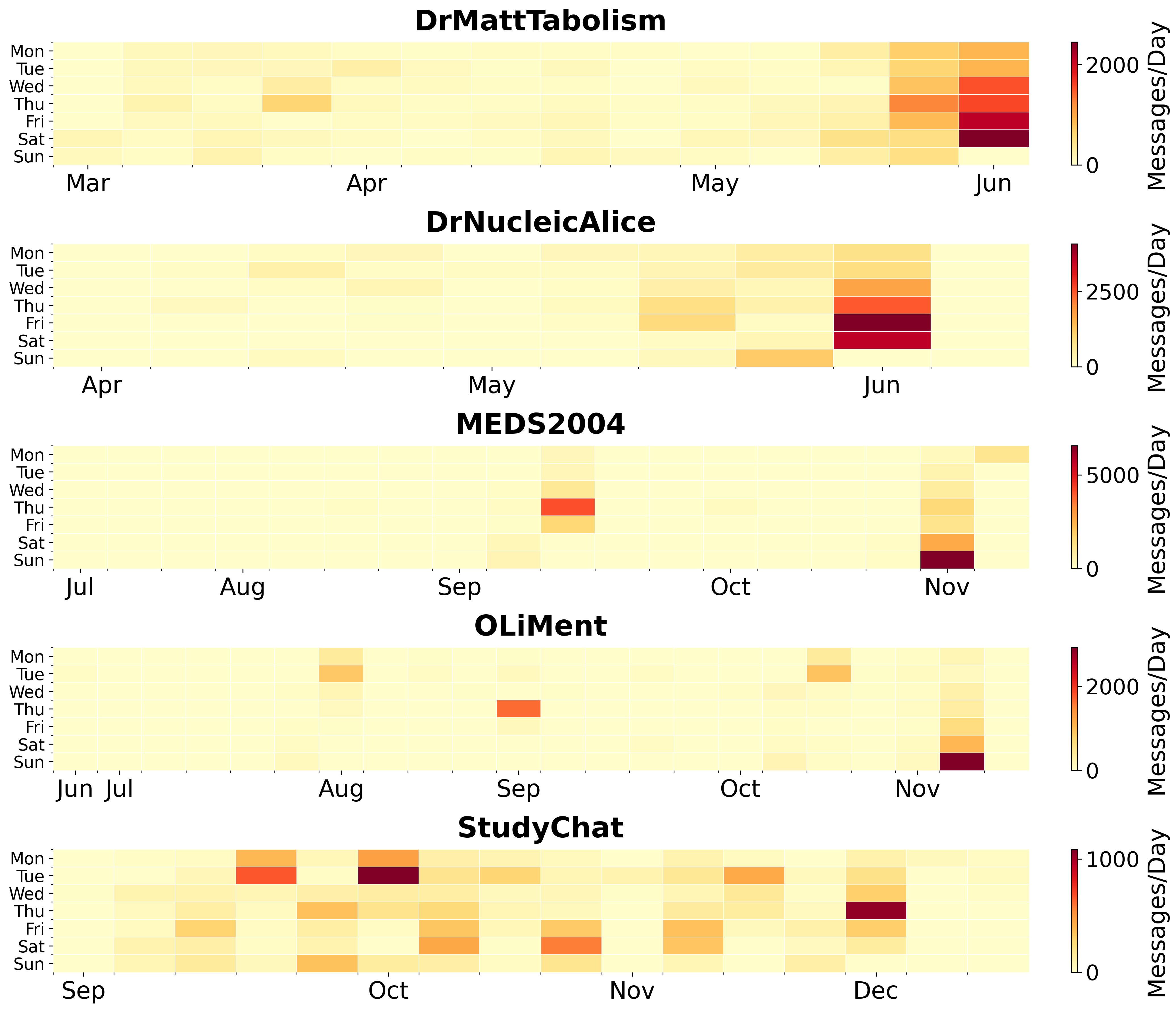
Figure 3: Temporal heatmap highlights stark usage clustering during end-of-semester periods for optional tools, in contrast to distributed StudyChat usage integrated into coursework.
Theoretical Implications
The findings integrate with established educational psychology—demonstrating that:
- Student Satisfaction Is Decoupled from Learning: There is no statistically significant correlation between computational metrics for learning orientation and engagement, and student-reported satisfaction (as confirmed on external benchmarks).
- Metacognitive Biases Drive “Satisfaction–Effectiveness Inversion”: Ease of use and “fluency” in interaction generate positive affect and satisfaction but can mask unproductive or shallow engagement, as suggested by prior illusions-of-fluency literature.
- Implementation and Context Outweigh System Design: Constrained platforms, free-form AI assistants, and required-vs-optional deployments yield profoundly different patterns; consistent system design and LLM prompting are secondary to systemic pressures and context.
Implications for Educational AI System Design and the Field
Practically, the research argues that standardized engagement and satisfaction metrics are insufficient and may be actively misleading; tools reporting high engagement can facilitate unproductive answer-extraction and gaming, not exploration or conceptual understanding. The authors’ multivariate, turn-by-turn behavioral analysis avoids this pitfall by directly quantifying pedagogically meaningful behaviors.
The findings emphasize that:
- Deployment context is decisive: Integration into assessment or coursework redistributes answer-extraction behavior throughout the semester, while optional tools serve as on-demand “emergency services” with low pedagogical value.
- Automated assignment–copying detection is unsolved: Even the strongest LLMs exhibit false positives/negatives in ADR, arguing against naive deployment for academic integrity monitoring.
- Temporal analysis is essential: Surface-level engagement and summary statistics obscure “crisis mode” patterns and student behavioral adaptation to task environment.
Limitations and Future Directions
The discussed framework is validated on STEM and EFL datasets and achieves robust inter-annotator agreement, but there are domain and discipline-specific aspects of answer-extraction to consider (especially in the humanities). The authors point to the need for discipline-adapted detection criteria, external and longitudinal validation, analysis of demographic equity, and caution against dual-use risks (e.g., inappropriate surveillance).
Future development could involve:
- Fine-tuned, domain-adaptive classifiers: Especially for ADR and more nuanced decompositions of crisis behavior
- Integration with outcome-based assessment: Testing alignment between detected behavioral shifts and measured learning gains
- Personalized and adaptive scaffolding: Using real-time behavioral monitoring to adjust AI interventions to discourage unproductive patterns
- Ethical, equitable deployment: Ensuring that interventions do not penalize at-risk or marginalized students
Conclusion
This work reframes the evaluation of educational NLP and LLM-based dialogue systems, arguing for and demonstrating interpretable, automated, behavioral metrics that expose the pedagogical realities of student–AI interaction. The results: most students systematically pursue answer-extraction strategies, with engagement metrics obfuscating rather than elucidating true learning, and deployment context driving behaviors more than any model-level variable. This metric suite constitutes a critical foundation for future evidence-based research, adaptive AI design, and policy-making with respect to educational LLM deployment.