- The paper introduces a neurosymbolic operational intelligence system that reframes industrial QA as a cognitive loop integrating perception, reasoning, prediction, and decision steps.
- It employs a structured FMEA knowledge graph, episodic memory, and a risk simulator to ensure telemetry grounding, evidence-based explanations, and counterfactual accuracy.
- Experimental results demonstrate significant gains in structural validity, evidence grounding, and reduced overclaims, confirming the system’s reliability in safety-critical maintenance.
Neurosymbolic Embodied QA for Industrial Asset Maintenance: An Analysis of IndustryAssetEQA
Industrial QA as an Embodied Cognitive Loop
IndustryAssetEQA introduces a neurosymbolic operational intelligence system for embodied question answering (EQA) in safety- and cost-critical industrial asset maintenance. The work reframes industrial QA away from LLM-centric text generation and instead models it as a sequence of perception, reasoning, prediction, and actionable decision steps. The taxonomy of maintenance questions is structurally mapped onto this cognitive loop, imposing strict requirements on time-situatedness, evidence grounding, explicit risk modeling, and knowledge alignment with domain constraints.
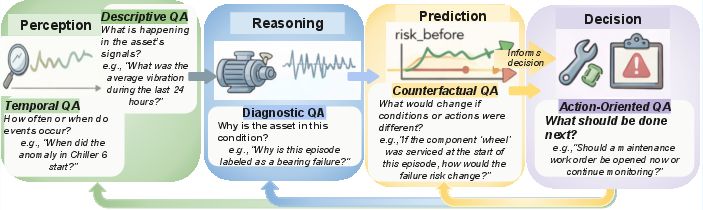
Figure 1: QA taxonomy mapped to the perception–reasoning–prediction–decision loop, highlighting dependencies and the embodied interaction cycle.
This taxonomy establishes a principled architecture for deployable industrial reasoning assistants, exposing the inadequacy of LLM-only approaches that, despite fluency, systematically fail to ground explanations in true telemetry, cite auditable provenance, or perform testable counterfactual and decision-oriented reasoning.
System Architecture: Neurosymbolic Fusion and Episodic Grounding
The system integrates the following primary components:
- FMEA-KG: A domain-level Failure Mode and Effects Analysis Knowledge Graph encoding 63 failure modes, 210 entities, and 1004 relations, providing machine-interpretable symbolic grounding from ISO-style specifications (asset hierarchies, failure semantics, sensor–fault relationships, maintenance actions).
- Structured Fact Extractor: Deterministically transforms heterogeneous time series telemetry, logs, and maintenance records into episode-centric features representative of pre-failure and healthy operation, with explicit time-windowing and engineered diagnostics.
- Episodic Store: A persistent, queryable layer supporting deterministic fact retrieval, efficient feature-level numeric search, and traceable provenance that underlie prompt construction, verification, and human audit.
- Risk Simulator: Implements a parametric, data-driven surrogate counterfactual estimator using simple intervention-style risk modeling (multinomial logistic regression and feature substitution). This module computes pre/post-intervention risk estimates and simulates the "what-if" impact of maintenance actions.
- Prompt Builder, Verifier, and Safety Gate: Renders task-scoped prompts enforcing evidenced reasoning and machine-verifiable output contracts (JSON). The Verifier and Safety Gate guarantee that only structurally valid, provenance-supported, and risk-aligned recommendations propagate to maintenance channels, with low-confidence or non-auditable answers escalated for human review.
This neurosymbolic framework (neural LMs tightly fused with symbolic, provenance-rich KG reasoning) yields structured, auditable answers directly aligned to telemetry-supported system state and codified domain constraints.
Datasets, Task Types, and QA Operationalization
Evaluation is conducted across four open industrial datasets (rotating machinery, turbofan engines, hydraulic test rigs, and cyber-physical systems) covering descriptive, temporal, diagnostic, counterfactual, and action-oriented QA. All query instances are episode-centric, evaluated under a closed-world assumption using SME-validated ground truth for final-answer correctness and structured explanations.
Experimental Results: Reliability and Explanation Faithfulness
IndustryAssetEQA yields substantial gains across the operational reliability metrics relevant for industrial deployment:
- Structural validity: Up to +0.51 improvement over LLM-only QA.
- Evidence grounding: Up to +0.47 improvement.
- Explanation entailment: Up to +0.64 improvement.
- Counterfactual accuracy: Increases from chance (≈0.45) to $0.88$ (GPT-4o-mini) and $0.91$ (Claude Sonnet 4).
- Severe overclaims: Reduced from 28% (LLM-only) to 2% (IndustryAssetEQA), a 93% reduction.
- Full pass rate: $0.89$–$0.90$ with complete pipeline components.
Ablation studies show irreducible performance degradation when removal of the episodic memory, provenance enforcement, FMEA-KG context, or the risk simulator are enacted—each module is complementary and necessary for the overall reliability of operational QA.
Expert evaluation corroborates the automated metrics, showing higher answerability (97% vs. 46%) and higher mean data-grounding scores compared to LLM-only baselines. Overclaims and unsupported answers, a critical safety concern, are nearly eliminated.

Figure 3: Qualitative comparison – LLM-only baseline produces unsupported, ungrounded explanations; AssetEQA grounds its answer in specific telemetry, provides verifiable evidence, and produces calibrated counterfactual estimates.
FMEA Knowledge Graph Quality
Triple-level validation against ISO specifications shows high precision in knowledge graph construction: 96% validity among 1004 candidate relations, with some degradation in structurally weak links but strong consistency where domain semantics directly inform QA.
Implications and Future Directions
IndustryAssetEQA reestablishes industrial QA as a closed-loop, embodied, and deterministically verifiable intelligence system. By requiring episode-centric, provenance-anchored evidence, explicit symbolic alignment, and risk-model-consistent counterfactual reasoning, it addresses structural deficiencies of LLM-based systems in high-stakes maintenance environments.
Key implications and avenues for future work include:
- Integration of Structural Causal Models: Counterfactual modeling currently relies on parametric intervention estimators; to further enhance safety, identified causal models should be integrated, expanding beyond correlational extrapolation.
- Extending KG Scope and Adaptive Episodic Windows: The current FMEA-KG is domain-level and may require expansion to accommodate asset-specific and rare failure scenarios. Adaptive windowing could be incorporated to detect precursors outside fixed windows.
- Operational Deployment and Human–AI Collaboration: The approach is well-suited for real-world deployment, with integration into asset management workflows and enterprise agents anticipated. Metrics such as real-time latency, escalation rates, and operator trust will require live study.
- Generalization to Other Safety-Critical Domains: The methodological paradigm—explicit state grounding, symbolic fusion, provenance enforcement, and human oversight—is applicable in other critical infrastructure, process industries, and potentially complex autonomous robotics domains.
Conclusion
IndustryAssetEQA advances operational intelligence for industrial assets beyond surface-level language modeling to a rigorous, embodied, and deployable QA architecture. Its neurosymbolic design, provenance protocols, and risk-grounded decision support establish a reproducible standard for reliability and explainability in AI-driven maintenance. The system identifies key failure modes of naive LLM-based methods and demonstrates that trustworthy automation in industrial settings mandates holistic evidence pipelines, symbolic reasoning integration, auditable explanations, and well-calibrated confidence assessment.