- The paper demonstrates that activation patching of hidden states can recover reasoning signals even when the overall chain-of-thought output is incorrect.
- It quantifies the causal impact of individual tokens, revealing that mid-to-late layers and earlier tokens densely encode answer-relevant information.
- The study highlights that language tokens, rather than numerical ones, are pivotal in steering correct arithmetic reasoning in LLMs.
Mechanistic Causal Analysis of Chain-of-Thought Failures in LLMs
Introduction and Motivation
The paper "When Chain-of-Thought Fails, the Solution Hides in the Hidden States" (2604.23351) presents a mechanistic, intervention-based analysis of the information encoded by chain-of-thought (CoT) generations in LLMs applied to arithmetic reasoning tasks. Unlike prior work that focuses primarily on model outputs or interprets reasoning traces as explanations, this study reverses the perspective by directly probing the hidden states underlying individual CoT tokens and quantifying their causal contribution to task-solving, even when the final generated answer is incorrect. The core question is whether intermediate reasoning is computationally useful or merely decorative, and where in the reasoning trace recoverable, answer-relevant information actually resides.
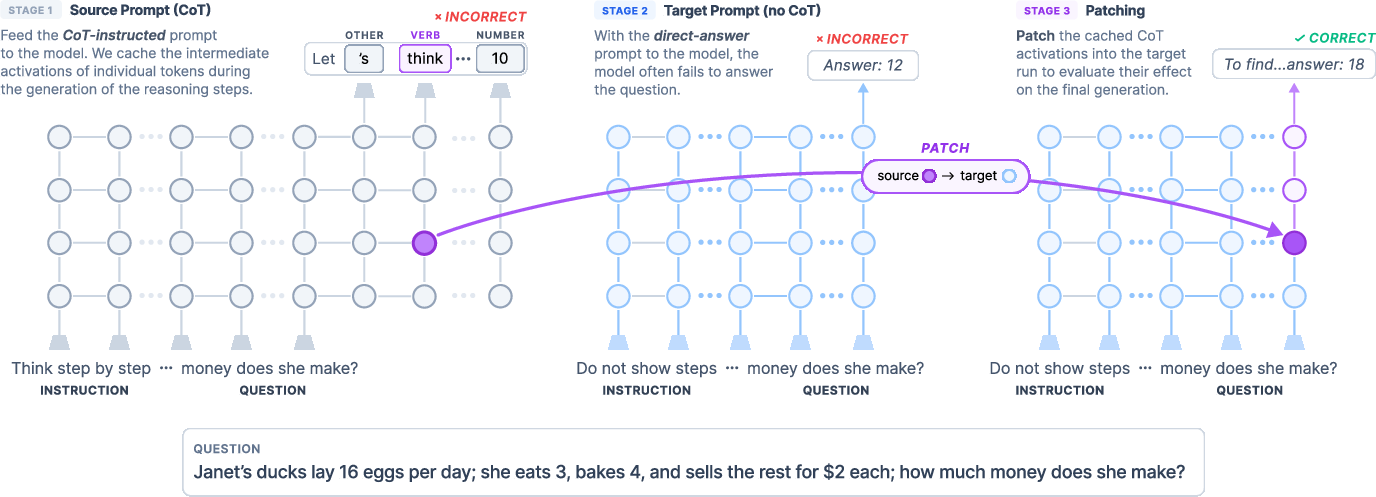
Figure 1: Schematic of the patching framework, transferring hidden states from CoT tokens to the final position of a direct-answer run to quantify their causal contribution to downstream accuracy.
Methodology: Activation Patching as Causal Intervention
The study employs a token-level activation patching paradigm, systematically transferring hidden states from each CoT token at a chosen layer into the final position of a direct-answer run on the same question. The target prompt is deliberately set to only request a numeric answer, which typically yields poor accuracy, ensuring any improvement is attributable to the information transferred. By measuring the change in final-answer accuracy following each intervention, the authors quantify the causal impact of each token’s internal representation.
The experiments utilize two instruction-tuned LLMs: LLaMA 3.1 8B and Qwen 2.5 7B, evaluated on the GSM8K arithmetic dataset. Hidden states are patched across layers and token positions, and semantic role labels are assigned to CoT tokens to disentangle the contribution of linguistic versus mathematical versus structural components.
Main Findings: Distribution and Recoverability of Task-Relevant Information
Patching Surpasses Original CoT Trace Accuracy
The most salient result is that patching yields substantially higher accuracy than both direct-answer prompting and the original CoT trace. For LLaMA 3.1 8B, patching achieves 99.5% accuracy compared to 84.6% with CoT and just 8.7% direct-answer; analogous gains are observed for Qwen 2.5 7B. Critically, this accuracy often exceeds the model's own CoT result even when the original chain is incorrect, evidencing that the requisite information can be embedded in hidden states, dormant or overridden during normal generation.
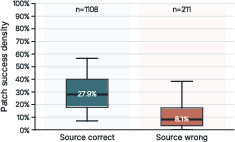
Figure 2: Patch success density across layer groups, highlighting broader and denser interventions in correct CoT runs versus sparse, inconsistent signals in incorrect traces.
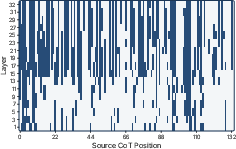
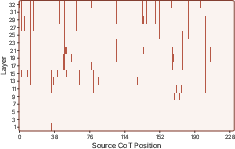
Figure 3: Example heatmap showing broad distribution of successful patches for a correct CoT instance.
Task-Relevant Signal is Uneven and Localized
Analysis of patch success density reveals that correct CoT runs have denser and more consistent recoverable signal across both token positions and layers. Incorrect runs, by contrast, exhibit sparser, irregular encoding of answer-relevant information, suggesting reasoning failures often result from propagation deficiencies rather than absolute absence.
Task-relevant information is preferentially concentrated in mid-to-late transformer layers and earlier tokens within the reasoning trace. This aligns with emergent depth specialization observations in LLMs, where intermediate layers accumulate richer semantic abstractions and later layers consolidate task-specific features.
Role-Type and Position Analysis
Semantic role annotation shows that language tokens—notably verbs and entities—carry disproportionately high task-solving signal, eliciting reasoning processes when patched and attaining patch success rates above 40%. In contrast, mathematical tokens (numbers, operands, operators) encode answer-proximal but less reliable content, predominantly yielding short, direct outputs ("Final Only") with much lower patch success rates.
Patch success is also highest in early CoT positions, declining monotonically through the chain. Earlier tokens tend to elicit more complex, multi-step generations (Full CoT, Equation Only), with higher likelihood of correct answers, whereas later tokens concentrate on answer computation.
Analysis of Generation Behavior and Patch Effect
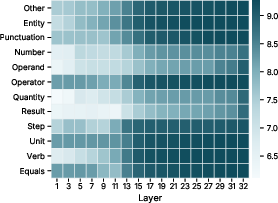
Figure 4: Log patch effect across entity types and layers, evidencing strongest causal influence in mid-to-late model layers.
The patch effect, quantified as the reduction in the original answer token's probability following intervention, confirms maximal causal sensitivity at the final target position and again highlights mid-to-late layers as crucial for redirecting output. Numeric tokens only weakly influence output, whereas linguistic entities trigger significant shifts.
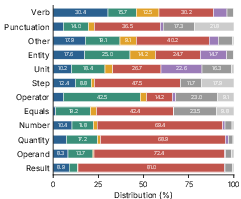
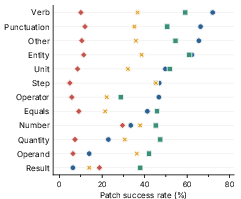
Figure 5: Distribution of output types per token role, highlighting prevalence of reasoning-oriented generations from language tokens.
Patch-induced generations vary by both token role and chain position. Language tokens frequently initiate reasoning-based outputs (Full CoT, Equation Only), while mathematical and structural tokens rarely do. Notably, successful recovery does not always require full reasoning traces: patched outputs are often much shorter yet exceed the accuracy of the original CoT, suggesting that intermediate representations suffice without explicit, verbose step-by-step reasoning.
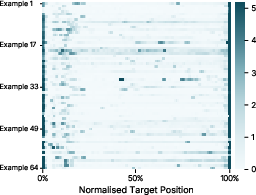
Figure 6: Log patch effect across normalized target positions for sampled GSM8K questions, further characterizing the locus of causal influence.
Implications
Practical Implications
This causal patching framework provides actionable diagnostics for model failure and repair, allowing targeted extraction of task-relevant internal states even in failed reasoning runs. The evidence supports the development of methods that bypass the need for full CoT traces, potentially accelerating inference and improving reliability in downstream tasks. Furthermore, linguistic tokens emerge as pivotal for reasoning facilitation in arithmetic tasks, guiding future prompt engineering and model specialization strategies.
Theoretical Implications and Future Directions
These findings challenge the assumption that explicit CoT traces are strictly necessary for computation and reaffirm that surface-level explanations can diverge from the internal computational substrate. Mechanistic intervention exposes causal heterogeneity in information propagation and elucidates where and how reasoning breaks down.
The work motivates extensions to other domains (logical, commonsense, symbolic reasoning), cross-model generalization, deeper analysis of monosemantic feature consolidation, and refined granular role labeling. Further research may leverage these insights for enhanced interpretability, representation repair, and foundational studies in reasoning emergence and circuit discovery.
Conclusion
This paper demonstrates that chain-of-thought generations encode recoverable, token-level problem-solving information within model hidden states, exceeding surface-level CoT performance when directly intervened upon. Task-relevant information is densely and unevenly distributed, with language tokens playing a central role in steering reasoning processes. These results advance the mechanistic understanding of reasoning in LLMs and lay groundwork for both more effective model debugging and efficient reasoning strategies that disentangle explanation from computation.

