- The paper introduces STAND, a framework with three key modules—ITC, DGTD, and SCA—that address ambiguities in remote sensing image change captioning.
- It leverages dual-granularity techniques to fuse global context with local detail, achieving superior results with improved BLEU-4, METEOR, ROUGE_L, and CIDEr scores.
- Ablation studies and visualizations confirm STAND’s robustness in distinguishing true changes from visual confounders, enhancing both semantic precision and reliability.
Semantic Anchoring Constraint with Dual-Granularity Disambiguation for Remote Sensing Image Change Captioning
Motivation and Problem Setting
Remote sensing image change captioning (RSICC) entails automated generation of fine-grained textual descriptions of changes between two temporally separated remote sensing (RS) images. The modality’s inherent challenges arise from ambiguities due to (1) top-down viewpoint similarity, (2) spatial scale disparity with most changes occupying small regions, and (3) domain-specific knowledge requirements where visually similar changes may have distinct semantics (Figure 1).

Figure 1: Typical examples of ambiguities in the remote sensing images, attributed to viewpoint, scale, and knowledge.
Conventional RSICC pipelines employ siamese or difference-centric feature extractors, static image encoders, or mask-guided architectures. However, these approaches insufficiently address the fundamental ambiguities inherent in RS imagery, such as genuine change vs. visual confounders, scale inconsistency of change regions, and need for explicit knowledge priors for precise entity identification.
The STAND Architecture
The paper introduces STAND, a Semantic Anchoring Constraint with Dual-Granularity Disambiguation framework, incorporating three synergistic components: (1) Interpretable Transition Constraint (ITC), (2) Dual-Granularity Target Disambiguation (DGTD), and (3) Semantic Concept Anchoring (SCA). The method encodes change scenes as bi-temporal “video” clips, regularizes temporal transitions between 'before', 'mask', and 'after' states, actively resolves scale/viewpoint ambiguity at macro and micro levels, and grounds change descriptions to linguistic/semantic priors.
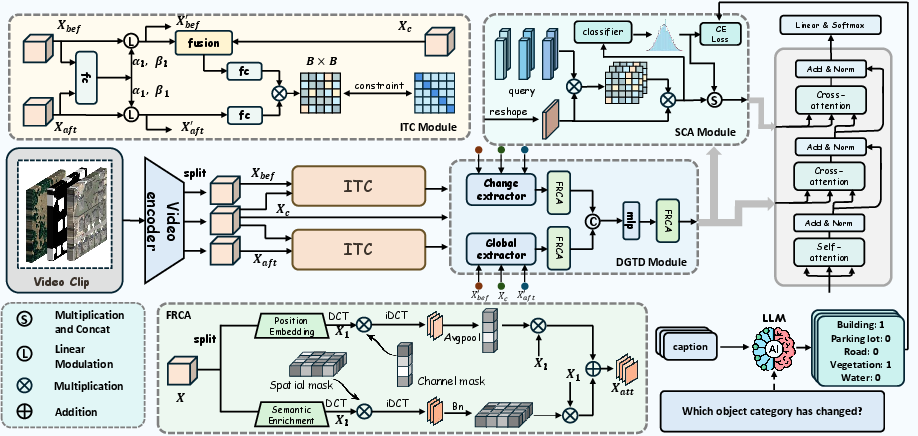
Figure 2: The architecture of STAND comprising ITC, DGTD (with macro/micro disambiguation), and SCA modules.
Interpretable Transition Constraint (ITC)
ITC enforces consistency in the temporal encoding’s intermediate representations, aligning the transition between 'before', 'change', and 'after' via a bidirectional InfoNCE loss. Pseudo-after features are synthesized by merging 'before' and 'change', and contrastive learning is applied to ensure they align with actual 'after' features while repelling mismatched compositions. This constraint stabilizes training and tightly couples encoded transitions to actual temporal change dynamics.
Dual-Granularity Target Disambiguation (DGTD)
- Macro-Level (Context-Aware Viewpoint Disambiguation, CAVD): Multi-head cross-attention fuses local difference features with global scene context, reducing posterior overlap among categories with similar top-down appearances.
- Micro-Level (Frequency-Refocused Complementary Attention, FRCA): Discrete Cosine Transform (DCT)-based modulation filters out low-frequency content and emphasizes high-frequency features—corresponding to small, subtle objects—thereby enhancing the model’s sensitivity to minor spatial changes.
Combining both granularity levels yields complementary improvements, with macro-level conditioning providing semantic context and micro-level refinement boosting local discriminative power.
Semantic Concept Anchoring (SCA)
To tackle knowledge ambiguity, SCA leverages category information extracted via dual-agent LLM verification from training annotations. Learnable category-queries distill object-specific feature vectors, and classification is enforced by cross-entropy loss. During decoding, a prior knowledge-guided architecture fuses difference features and entity representations via cross-attention, biasing generation towards semantically precise and entity-complete captions.
Empirical Results
The method is comprehensively validated on LEVIR-CC and WHU-CDC datasets against state-of-the-art RSICC baselines and modern multi-modal LLMs (MLLMs).
- LEVIR-CC: STAND achieves the best BLEU-4 (67.11), METEOR (41.55), ROUGEL (77.25), and CIDEr (143.39) scores, outperforming the second-best (DGAT) by a margin of +0.57 METEOR, +0.84 ROUGEL, and +2.12 CIDEr.
- WHU-CDC: Despite the diminished impact of object priors, the method still exhibits top performance (BLEU-4: 76.91, METEOR: 49.08, CIDEr: 160.78), indicating robustness to simpler change patterns.
Ablation studies demonstrate that DGTD’s macro and micro submodules are synergistic, and the incorporation of SCA yields the most appreciable performance leap, particularly in semantic completeness and category F1.
Visualization and Qualitative Analysis
STAND demonstrates improved capability in distinguishing confounding changes, localizing small objects, and avoiding hallucinations even under seasonal variation or redundant background artifacts (Figure 3).

Figure 3: Visualization of baseline Change3D and STAND; STAND exhibits improved precision in hard cases with viewpoint and scale ambiguity.
FRCA module visualizations confirm refocusing of attention from low-frequency to meaningful change areas, facilitating detection of hard-to-localize, small-scale modifications (Figure 4).

Figure 4: Visualization of the heatmap, without (left) and with (right) FRCA, showing improved localization of real changes.
Comparison to MLLMs
Fine-tuned MLLMs such as MiniGPT4 and LLaVA variants underperform compared to STAND in both fluency and entity-level precision, despite much larger parameter counts. This exposes the limited domain transferability of generic MLLMs to the RSICC task, emphasizing the necessity for architectures explicitly tailored to RS ambiguity and data curation constraints.
Implications and Future Directions
Theoretical implications of STAND lie in its modular approach to explicit ambiguity decoupling, multi-granular context fusion, and structured semantic anchoring. Practically, the framework exhibits advantages for downstream applications including urban change monitoring, fine-grained environmental assessment, and multi-scale disaster auditing, where precision and semantic completeness are paramount.
The reported architecture’s progressive refinement, joint training, and careful handling of contrastive negatives mitigate common failure modes in RSICC—such as overfitting to pixelwise differences or erroneously equating visual saliency with semantic relevance.
Potential avenues for development include scaling to high-resolution or multi-sensor RS imagery, transferring the disambiguation pipeline to more complex geographies, and tighter coupling with MLLM models while safeguarding RS priors and avoiding catastrophic forgetting of domain specificity.
Conclusion
STAND addresses the substantial challenge of multilevel ambiguity in RS change captioning via an end-to-end architecture incorporating interpretable transition constraints, dual granularity disambiguation, and semantic anchoring. Extensive empirical evidence substantiates that this progressive, linguistically grounded pipeline achieves state-of-the-art performance and improved robustness over both classical and large-model-based baselines, setting a strong methodological precedent for further advances in spatiotemporal vision-language processing in the RS domain (2604.23309).