- The paper introduces a two-stage, LLM-guided pipeline that emulates human scholarly reading to extract content-grounded answers from full research texts.
- It leverages structural hierarchy and iterative reading with sufficiency checks to mitigate hallucinations and enhance retrieval precision.
- Empirical results demonstrate significant gains over RAG baselines, establishing new benchmarks with diverse LLM backbones across multiple disciplines.
IntrAgent: An LLM Agent for Content-Grounded Information Retrieval through Literature Review
Introduction and Motivation
Automated information retrieval from scientific literature is a foundational but persistently challenging task in research workflows due to the domain complexity and substantial contextual dependencies inherent in scientific papers. The "IntrAgent" paper (2604.22861) introduces a new problem formulation—Information reTRieval through literAture reVIEW (IntraView)—which operationalizes the extraction of fine-grained, content-grounded answers to research-driven queries from the entirety of a given scientific document. The motivation is rooted in raising the fidelity, efficiency, and faithfulness of such IR systems beyond what is achievable with existing retrieval-augmented generation (RAG) pipelines or general-purpose LLM-based agents, which struggle with noisy context, hallucinations, or superficial semantic matching.
Architecture and Methodology
Two-Stage Pipeline
The core contribution is the IntrAgent agent, which explicitly mimics the human approach to scholarly reading and information extraction via a structured, LLM-guided two-stage pipeline (Figure 1):
- Stage 1: Section Ranking
Leveraging structural knowledge, the agent parses and hierarchically reconstructs section headings from the input document, using LLM-driven reasoning to produce a relevance-ordered list of sections tailored to the incoming research question.
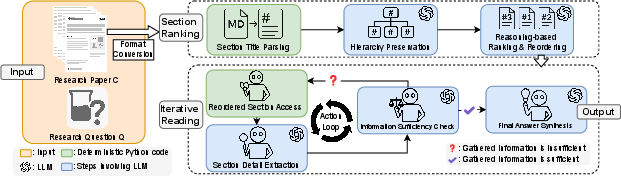
Figure 1: Overview of the IntrAgent pipeline containing two stages: Section Ranking (top) reorders the paper’s sections by relevance to the Research Question Q, while Iterative Reading (bottom) steps through ranked sections, extracting information until gathered information is sufficient.
- Stage 2: Iterative Reading
This stage processes the reordered sections sequentially, performing targeted detail extraction per section with domain-tailored prompt engineering. At each step, an LLM-based sufficiency check determines if the accumulated evidence is adequate for answer synthesis, thus preventing premature termination and mitigating hallucinations by ensuring all claims are substantiated by the text.
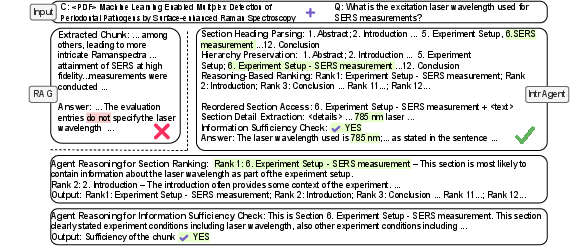
Figure 2: Example contrasting IntrAgent and RAG on a real instance, depicting section ranking, detail extraction, and the sufficiency check leading to correct answer selection.
Design Mechanisms
Key technical mechanisms include:
- Hierarchy Preservation: Unlike chunk-based methods, the agent reconstructs the tree structure of the document, enabling context-aware section selection and overcoming structural variability.
- LLM-Guided Reasoning: Both ranking and sufficiency assessments are delegated to the backbone LLM, ensuring that domain-specific and cross-section reasoning is possible.
- Confidence-Controlled Iteration: The iterative reading step supports user-configurable aggressiveness for section traversal, balancing context window size and retrieval recall according to inferential confidence needs.
IntrAgent Benchmarking: IntraBench
To rigorously calibrate progress on IntraView, the authors introduce IntraBench, a new expert-constructed benchmark of 315 question-paper pairs covering physics, earth science, public health, engineering, and material science. Each instance involves expert-authored queries and multiple-choice labeling to facilitate automatic but semantically robust evaluation.
Evaluation Method
System outputs are mapped post-hoc by an LLM (defaulting to GPT-4.1) onto the multiple-choice ground truths, addressing challenges in scientific terminology variation, answer synonymy, and factual correctness. This protocol also enables comprehensive comparison with various RAG baselines and literature agents.
Empirical Results and Analysis
IntrAgent demonstrates consistent, large-magnitude improvements in cross-domain accuracy across all tested backbone LLMs on IntraBench (Table in the paper; summary below):
| Backbone |
Best Baseline (%) |
IntrAgent (%) |
Delta (%) |
| GPT-4o |
62.1 |
70.0 |
+7.9 |
| GPT-4.1 |
64.7 |
75.8 |
+11.6 |
| DeepSeek-R1 |
65.5 |
74.4 |
+8.9 |
| o3 |
57.5 |
73.4 |
+18.2 |
| o4-mini |
58.3 |
73.8 |
+17.4 |
| Gemini 2.5 Pro |
61.8 |
75.9 |
+21.0 |
| Llama-3.1-70B |
61.4 |
68.8 |
+7.4 |
Nationally, performance gains are ascribed to targeted, hierarchical evidence selection and explicit hallucination control, rather than simply scaling model context length.
Radar Plot Analysis
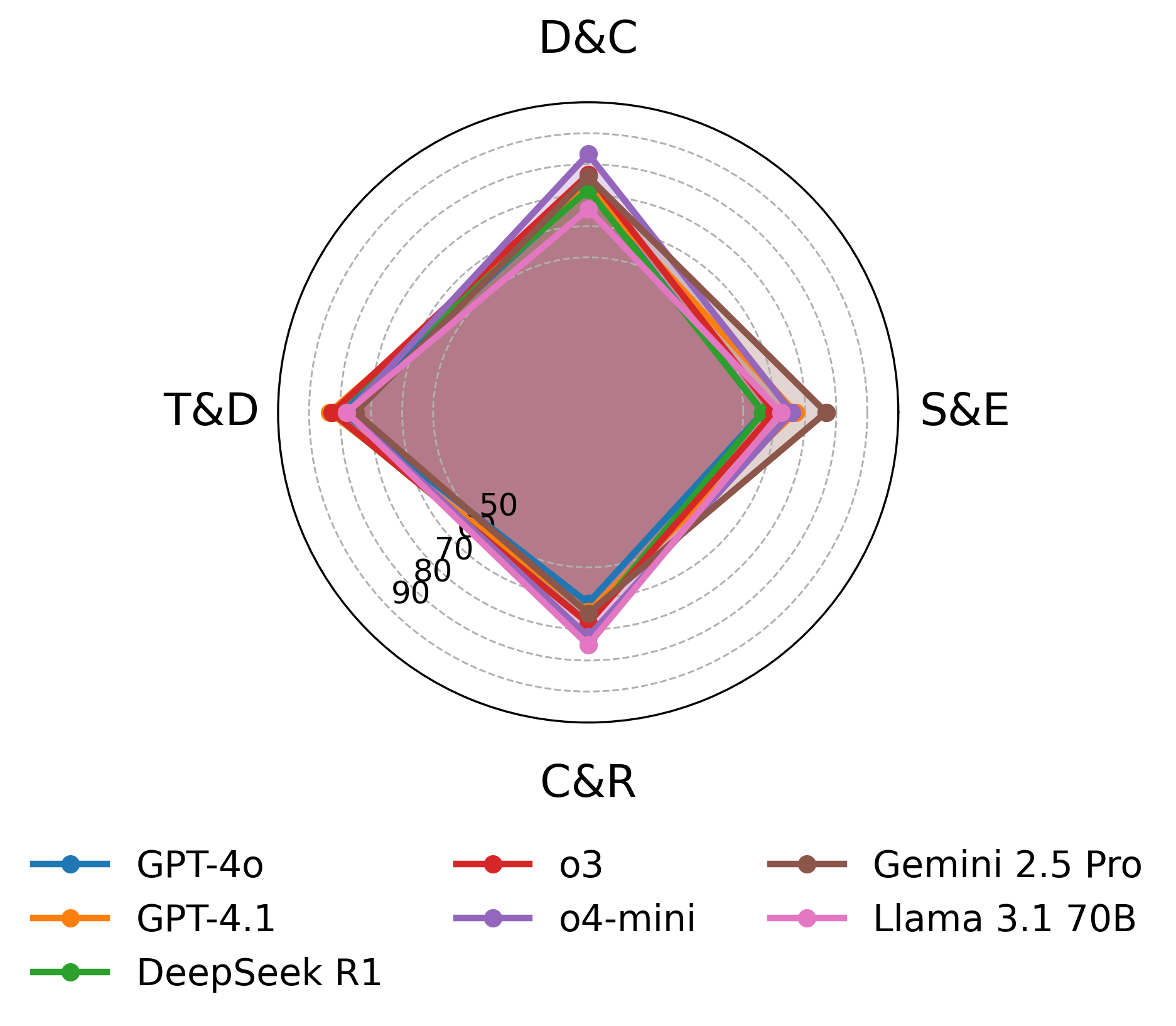
Figure 3: Performance comparison across seven models and four research-question categories, highlighting consistent robustness of IntrAgent and domain-specific model strengths.
The category-wise breakdown shows that IntrAgent delivers robust, well-balanced gains across diverse question types, outperforming domain-oriented and generalist baselines, including SOTA literature agents and RAG extensions.
Ablation and Robustness
- Hierarchy Preservation: Removing the hierarchy-aware section tree reduces accuracy by 4–5% on aggregate, confirming the need for structural priors in scientific IR.
- Sufficiency Check: Skipping this step catastrophically degrades physics accuracy from 75.4% to 32.2%, primarily due to incomplete, cross-section distributed evidence and increased hallucinations.
- Confidence Control: Conservative readout (more context) paradoxically decreases accuracy, consistent with degradation at excessive sequence lengths—a finding echoing observations in recent long-context LLM work [jiang2024longragenhancingretrieval].
- Noisy Headings: IntrAgent remains robust to nonstandard or noisy section headings, sustaining >84% performance on adversarial variants.
Theoretical Implications and Practical Impact
The proposed agent framework moves beyond conventional RAG and static QA paradigms by instantiating a tightly-coupled plan-act-check loop explicitly modeled after expert human reading. This demonstrates that faithful, precise retrieval in voluminous, highly-structured scientific texts is only tractable via hierarchical and context-aware inference, aligned with document structure and semantic content.
In practical terms, IntrAgent sets a blueprint for LLM-powered scholarly assistants with high precision and low hallucination. The benchmark protocol and agent architecture are extensible to other domains requiring grounded cross-reference, and signal new research opportunities for integrating multimodal (text + figures/tables), multi-document, and fact-verification capabilities.
From a methodological standpoint, IntrAgent’s approach bridges the gap between naive chunk-based IR and sophisticated agentive reasoning, with a pipeline readily applicable to scientific domains spanning biomedical, engineering, and physical sciences.
Future Developments
Outstanding directions include extending the agent and benchmark to visual modalities (figures, tables, spectral plots) ubiquitous in scientific publications, scaling benchmarking coverage to review articles and broader document types, and incorporating improved evaluation harnesses for nuanced answer verification. The pipeline’s prompt-driven modularity makes it a prime candidate for generalization to other complex, multi-stage research tasks, including automatic survey generation, literature mapping, and science-of-science analytics.
Conclusion
IntrAgent demonstrates that structurally-aware, reasoning-centric LLM agents can far surpass existing RAG- and agent-based baselines for information retrieval from scientific papers. Its hierarchical section ranking, iterative extraction with sufficiency checks, and domain-agnostic design drive superior fidelity and faithfulness in content-grounded task completion. The introduction of IntraBench as a challenging multi-domain evaluation benchmark catalyzes further innovation and enables reliable progress measurement for agents operating over scientific literature.
IntrAgent thus establishes both a technical paradigm and an evaluation standard for next-generation, agentic IR systems in science.
References
- "IntrAgent: An LLM Agent for Content-Grounded Information Retrieval through Literature Review" (2604.22861).