- The paper introduces SG-RAG, a method that enforces multi-constraint satisfaction using embedding-based subgraph matching.
- It employs a GNN-based model and R*-Tree indexing to rigorously structure, index, and retrieve knowledge from large datasets.
- SG-RAG achieves significant gains, outperforming baselines by 20.68–50.88 Hit@1 points on multi-condition queries.
Structure Guided Retrieval-Augmented Generation for Factual Queries: An Expert Analysis
Introduction and Motivation
LLMs integrated in Retrieval-Augmented Generation (RAG) pipelines exhibit significant improvements in factual accuracy relative to pure generation. However, contemporary RAG systems predominantly employ flat vector-based retrieval or graph chunking, resulting in semantic drift and incomplete constraint satisfaction when queries involve multiple structured conditions. The paper "Structure Guided Retrieval-Augmented Generation for Factual Queries" (2604.22843) formalizes this limitation by introducing the Exact Retrieval Problem (ERP): the requirement to retrieve and generate information that satisfies all user-supplied constraints in a factual query, with explicit guarantee of constraint satisfaction.
To address ERP, the authors propose Structure Guided RAG (SG-RAG), a system that replaces conventional vector aggregation with an embedding-based subgraph matching paradigm, enabling direct enforcement of multi-constraint satisfaction in retrieval and downstream answer generation. A large-scale benchmark, the Exact Retrieval Question Answering (ERQA) dataset spanning 20 domains, is constructed to systematically evaluate ERP solutions.
Problem Definition and System Architecture
The Exact Retrieval Problem (ERP) is formally defined as follows: Given a factual query qo decomposable into k≥2 explicit constraints, and a knowledge corpus K, retrieve knowledge from K such that all constraints are jointly satisfied, and generate an answer using an LLM with minimal hallucination.
SG-RAG’s architecture comprises:
- Document Structuring (ϵ): Converts K into a knowledge graph G of entities, relations, node/edge attributes.
- Graph Neural Network Model (M): Learns dominant embeddings for each node and subgraph structure.
- Index Construction (ϕ): Indexes all path embeddings in an R*-Tree for scalable retrieval.
- Query Graph Construction (ψ): Parses and normalizes the user query into a query graph, extracting all constraints as nodes/edges.
- Path-level Retrieval (k≥20): Implements path dominance-based matching in embedding space.
- Subgraph Assembly (k≥21): Merges path retrievals into candidate subgraphs isomorphic to the query graph.
- Answer Generation (k≥22): Prompts the LLM with the matched subgraph context to produce the final answer.
The system is orchestrated as a pipelined framework, combining semantic and structural alignment.
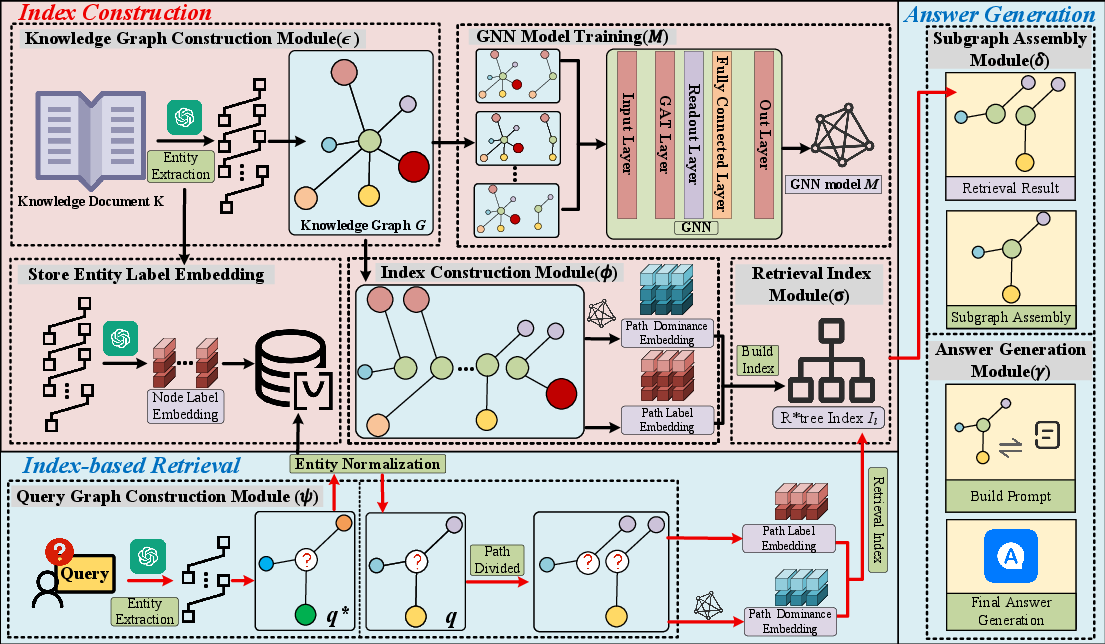
Figure 1: SG-RAG system architecture for structure guided retrieval and answer generation.
Technical Core: Embedding-Based Subgraph Matching
SG-RAG operationalizes ERP by transforming both query and knowledge contexts into attributed graphs. Key innovations include:
- Learning dominant embeddings for nodes and paths using a GAT-based GNN, which ensures that embeddings of substructures are always “contained” dimension-wise by those of their superstructure (see the imposed dominance constraint).
- Decomposing queries into linear paths of fixed length, then matching these via an R*-Tree over the embedding space. This dual-indexing allows simultaneous semantic and topological pruning during retrieval.
- For matching: a query path matches a knowledge graph path if both semantic and dominance constraints are satisfied in all dimensions; candidate paths are subsequently merged into subgraph candidates, which are checked for full isomorphism to the query graph.
This yields guarantee that all query constraints—no matter their specificity or combinatorial complexity—filter the retrieval process; retrieval degenerates to semantic matching only when structural evidence is too sparse.
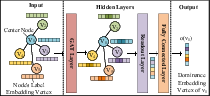
Figure 2: Architecture of the GNN used for learning dominant embeddings.
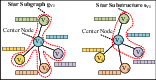
Figure 3: Illustration of a star-shaped subgraph and its substructures.
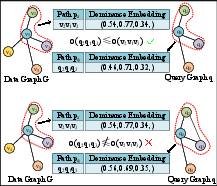
Figure 4: Path-level dominant embedding matching via element-wise comparison.
Dataset and Evaluation Protocol
The new ERQA benchmark comprises 120,000 multi-constraint factual QA pairs in three subsets:
- FB-ERQA: 80,000 questions from an English encyclopedic graph (avg. 6.1 constraints/query).
- UD-ERQA: 10,000 questions from multi-discipline textbooks (avg. 4.7 constraints).
- CM-ERQA: 30,000 queries from a Chinese medical KG (avg. 5.4 constraints).
Each question is graph-constructed to require intersectional satisfaction of multiple attributes or relations, closely reflecting real-world diagnostic or scientific lookup scenarios.
Expert human validation reveals high fluency (4.65), answerability (98.2%), and minimal ambiguity (1.8%), asserting dataset quality.
Results and Analysis
SG-RAG achieves major performance advances, materially advancing the state of the art on ERP:
- Absolute performance gains: On all ERQA subsets, SG-RAG exceeds the strongest baseline (GraphRAG, SubgraphRAG, KAG, LightRAG) by 20.68–50.88 Hit@1 points.
- Relative improvements: 34%–450% over best competitors in key metrics (Hit@1, F1, Recall).
- Multi-constraint robustness: SG-RAG sustains high Hit@1 (≥69%) even on queries with ≥6 constraints, where all prior methods degrade rapidly.
Compared with semantic or shallow graph methods (e.g., NaiveRAG, RAPTOR, LightRAG), SG-RAG’s performance margin is pronounced, especially on pathologically constrained queries in CM-ERQA.
A detailed efficiency study shows that the increased retrieval and offline indexing complexity is minimal—SG-RAG’s online latency nearly matches NaiveRAG and stays well below GraphRAG. For offline pre-processing, it incurs ~1h higher construction cost than LightRAG for 30k-examples, scalable with additional compute.
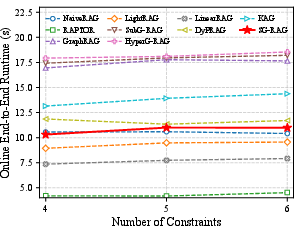
Figure 5: Online end-to-end runtime comparison.
Case Study
A highlighted case from the medical domain demonstrates SG-RAG’s capability to match all constraints:
"Which disease is likely to simultaneously cause deep vein thrombosis, acute closed Achilles tendon rupture, infection, and fracture as complications?"
SG-RAG retrieves the full constraint structure and correctly returns "Neurovascular injury", while baselines either hallucinate, partially match, or return "unable to determine", confirming the necessity of fine-grained structure alignment.
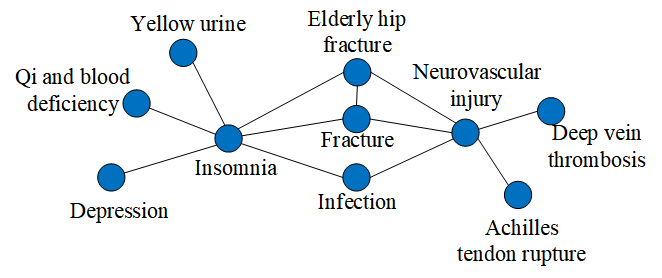
Figure 6: Subgraph structure used for query construction.
Theoretical Implications and Future Directions
SG-RAG bridges the gap between semantic retrieval and hard logical reasoning by merging GNN-based subgraph isomorphism with differentiable representations, offering a scalable protocol for enforcing constraint satisfaction in complex information access. Unlike “soft” multi-hop graph RAG methods, the embedding dominance mechanism guarantees that matches obey all supplied conditions, barring evidence incompleteness.
Potential future developments include:
- Further optimizing the pipeline for larger knowledge graphs and reducing propagation of upstream errors in entity normalization.
- Extending SG-RAG to support fuzzy or partially ordered constraints—enabling best-effort answers when exact fulfillment is impossible.
- Integrating domain-specific adaptations, especially for structured scientific, legal, or multi-lingual KBs.
- Hybridizing with retrieval-augmented neural symbolic systems or integrating logical inference modules on top of the matching mechanism.
Conclusion
SG-RAG establishes the ERP as a first-class research target and delivers a methodology that convincingly outperforms state-of-the-art vector and local structure RAG approaches by explicitly enforcing multi-constraint satisfaction. Its practical gains are most evident in multi-hop, attribute-rich domains where existing retrieval and generation systems systematically under-constrain their outputs. The approach further validates that structure-aware neural retrieval can mitigate hallucination not only by augmenting evidence, but by formalizing and guaranteeing the completeness of factual grounding.
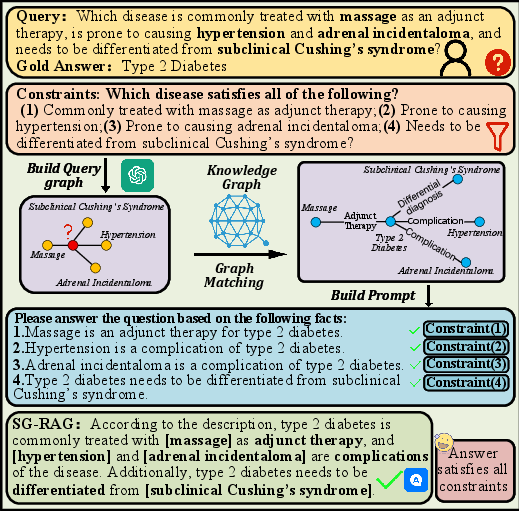
Figure 7: Multi-Condition QA Example.
Figure 1: SG-RAG system architecture for structure guided retrieval and answer generation.
Figure 5: Online end-to-end runtime comparison.
Figure 2: Architecture of the GNN used for learning dominant embeddings.
Figure 3: Illustration of a star-shaped subgraph and its substructures.
Figure 4: Path-level dominant embedding matching via element-wise comparison.
Figure 8: Illustration of a bridge-star subgraph structure.
Figure 6: Subgraph structure used for query construction.

