- The paper introduces CRAFT, which leverages clustered regression to efficiently select training subsets that closely match validation distributions.
- It employs a two-stage procedure that first aligns source embeddings via k-means clustering and then applies conditional target selection to minimize KL divergence.
- CRAFT demonstrates superior translation quality (up to 43.34 BLEU) and speed, operating vectorization-agnostically with both dense and TF-IDF representations.
CRAFT: Clustered Regression for Adaptive Filtering of Training Data
The rapid growth of parallel corpora for sequence-to-sequence tasks, especially neural machine translation (NMT), has highlighted the inefficiency of full fine-tuning on ever-expanding datasets. Many models can approach or surpass full-data performance by fine-tuning on a strategically selected subset, provided it sufficiently captures the relevant distributional properties present in the validation (target) set. The challenge lies in efficiently identifying a small, high-quality subset from candidate pools with tens of millions of examples that (1) matches the validation data distribution, (2) does so orders of magnitude faster than previous methods, and (3) is robust to different vectorization strategies.
CRAFT (Clustered Regression for Adaptive Filtering of Training Data) is introduced as a vectorization-agnostic data selection algorithm for training seq2seq models. It is founded on a principled decomposition of the joint source-target distribution P(S,T) into a two-stage selection procedure that exploits the conditional structure inherent in parallel datasets—a structure not explicitly leveraged by prior selection methods.
Methodology
Factorization and Two-Stage Selection
CRAFT formalizes data selection as matching the empirical distribution induced by a validation set V={(si,ti)}i=1M using a subset T′⊂T of size k≪N from a very large candidate pool T. The joint distribution P(S,T) is decomposed as P(S)⋅P(T∣S), guiding a two-stage procedure:
- Source Marginal Matching: Validation source embeddings are clustered via k-means (ms clusters). Cluster occupancy proportions are used to allocate selection budget per source cluster, thereby minimizing KL divergence between the source distribution of the selected data and the validation set. It is analytically shown that this proportional allocation minimizes the discretized KL divergence over the clusters, with an explicit upper bound on the continuous KL divergence that vanishes as clusters become fine (smaller diameter).
- Conditional Target Selection: Within each source cluster, validation target embeddings are separately clustered into mt clusters. For a candidate in a source cluster, the selection score is defined as the expected distance to validation target cluster centroids, weighted by the empirical conditional distribution V={(si,ti)}i=1M0 observed in the validation set. This strategy regularizes selection (preventing over-concentration) by scoring at the cluster centroid level, not raw embedding distance, yielding robustness to metric noise and vectorizer choice.
This methodology is visualized through contrasted point distributions:
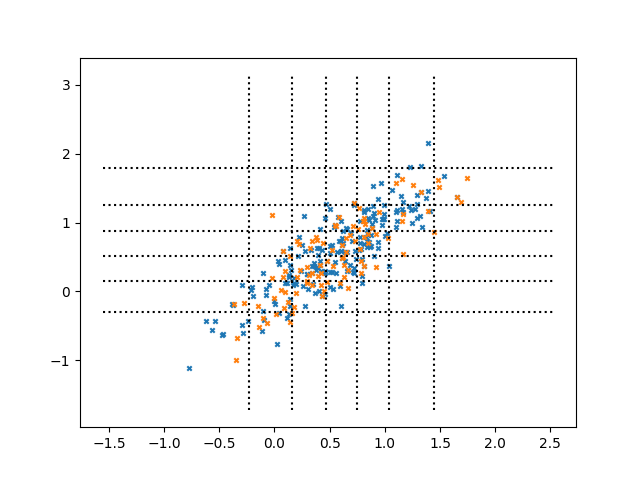
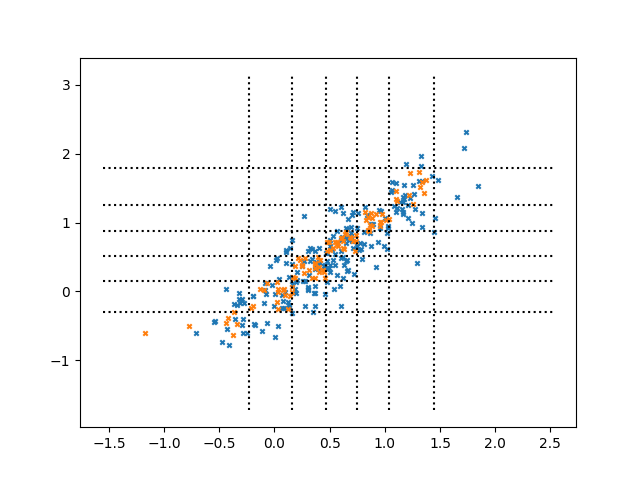
Figure 1: Distribution-matched: two samples drawn from the same joint distribution. The selected points (orange) cover the full spread of the validation points (blue).
CRAFT (not shown) concentrates selected points along the locus of the true conditional V={(si,ti)}i=1M1, leading to more precise and semantically aligned training data.
Vectorization-Agnostic Design
All operations in CRAFT—clustering, bucket assignment, centroid computations, and selection—depend only on distance calculations over vector representations. The framework is agnostic to the embedding method, admitting dense (semantic) LLM-based representations or high-dimensional sparse representations such as TF-IDF, with demonstrated robustness to representational expressivity.
Algorithmic Complexity
For V={(si,ti)}i=1M2 candidates and V={(si,ti)}i=1M3 validation examples, the vectorization step dominates runtime if using LLM-based embedding (V={(si,ti)}i=1M4 for embedding cost V={(si,ti)}i=1M5). TF-IDF vectorization significantly reduces compute, making selection practical for CPU-only environments, while selection itself (excluding vectorization) operates with linear or near-linear complexity.
Empirical Evaluation and Ablation
Experimental Protocol
The effectiveness of CRAFT is evaluated primarily on the English–Hindi translation task using the 33M-pair NLLB corpus, with mBART-50 fine-tuned via LoRA on selected 20K subsets. All strong data selection baselines (DSIR, TSDS, TAROT) are included, using standardized encoders and consistent selection pool sizes. Both selection effectiveness (BLEU, chrF, METEOR) and algorithmic efficiency (end-to-end selection runtime, including vectorization and selection) are assessed.
Key Results
- Quality: On a 1M candidate pool, CRAFT (dense embeddings) achieves 43.34 BLEU, surpassing TSDS (41.21), with TAROT scoring highest (45.61). With TF-IDF representations, CRAFT nearly matches TSDS (41.78 vs. 41.21 BLEU).
- Efficiency: Selection time for CRAFT (dense) is 26.86 seconds, 2.8V={(si,ti)}i=1M6 faster than TAROT (75.6s) and V={(si,ti)}i=1M740V={(si,ti)}i=1M8 faster than TSDS. With TF-IDF, CRAFT reaches sub-minute selection even on million-scale pools, with CPU-only operation for both vectorization and selection.
- Ablation: Ablating either source/target separation or conditional scoring (reduced to distribution matching) causes BLEU to degrade to near-random selection. This empirically confirms the necessity of CRAFT’s individualized source clustering and conditional alignment objectives.
- Scalability: Increasing the candidate pool from 1M to 33M yields only marginal BLEU improvement, indicating that CRAFT rapidly isolates high-quality data early and avoids compute waste even on massive pools.
Theoretical Implications
CRAFT provides a formal connection between cluster-based data selection and continuous KL divergence minimization between validation and selected source distributions. The cluster diameter-dependent residual further offers a handle for practitioners to control selection quality by adjusting the number of clusters. Notably, regularization-by-discretization at the cluster level mitigates issues of overfitting and aligns well with the use of proxy distances in high-dimensional embedding spaces.
Furthermore, CRAFT naturally generalizes prior work (e.g., TSDS, DSIR, TAROT) by internalizing stratification/strata selection and integrating selection regularization implicitly, rather than via explicit diversity penalization or optimal transport instantiation.
Practical Significance and Future Directions
CRAFT’s flexibility regarding vectorization ensures practicality amidst diverse compute/resource settings. It offers a compelling trade-off between selection speed and fine-tuning efficacy, especially relevant for large-scale or latency-sensitive domains. The robust performance of CRAFT with simple TF-IDF encodings makes it appealing for bootstrapping rapid prototypes or large multilingual systems where GPU usage is constrained.
The explicit modeling of the conditional structure present in parallel datasets encourages adaptation of the CRAFT framework to other structured prediction tasks beyond translation, including cross-modal (e.g., vision-language) datasets.
A clear direction for future work involves extending both experimental benchmarks (other tasks/languages and modalities) and investigating cluster resolution adaptivity (dynamically selecting V={(si,ti)}i=1M9, T′⊂T0 depending on validation set entropy) for optimal performance-variance balancing.
Conclusion
CRAFT is a theoretically grounded, highly efficient data selection method for large-scale seq2seq training. By decomposing the source-target joint distribution via stratified clustering and conditional alignment, it consistently achieves high translation quality with minimal selection latency and exhibits robustness across vectorization choices. The regularization effect of cluster-level selection and the empirical efficacy in large parallel corpora motivate CRAFT as a generic data selection solution for modern machine learning workflows (2604.22693).