- The paper introduces BLAST, a dedicated framework that benchmarks LLMs on Answer Set Programming generation using domain-specific semantic metrics.
- The paper employs both test-suite-based and model-based evaluation methods to accurately measure semantic correctness against gold ASP programs.
- The paper demonstrates that while LLMs achieve high syntactic validity, they struggle with semantic precision, highlighting crucial areas for future improvement.
BLAST: Structured Benchmarking of LLMs for Answer Set Programming Generation
Introduction and Motivation
The proliferation of LLMs has yielded substantial advances in code generation for imperative languages, but systematic evaluation of their capacity to generate declarative logic programs remains understudied. "BLAST: Benchmarking LLMs with ASP-based Structured Testing" (2604.22306) addresses this deficit by introducing the first dedicated methodological framework and dataset for benchmarking LLMs on Answer Set Programming (ASP) code generation tasks. This benchmark advances the field by providing two dedicated, domain-specific semantic evaluation metrics and a robust, reproducible evaluation suite that abstracts away from syntactic surface forms, focusing on genuine semantic correctness.
BLAST Framework and Evaluation Methodology
The BLAST evaluation pipeline decomposes into two principal components: (1) an LLM-based ASP generation framework and (2) an automated semantic testing infrastructure.
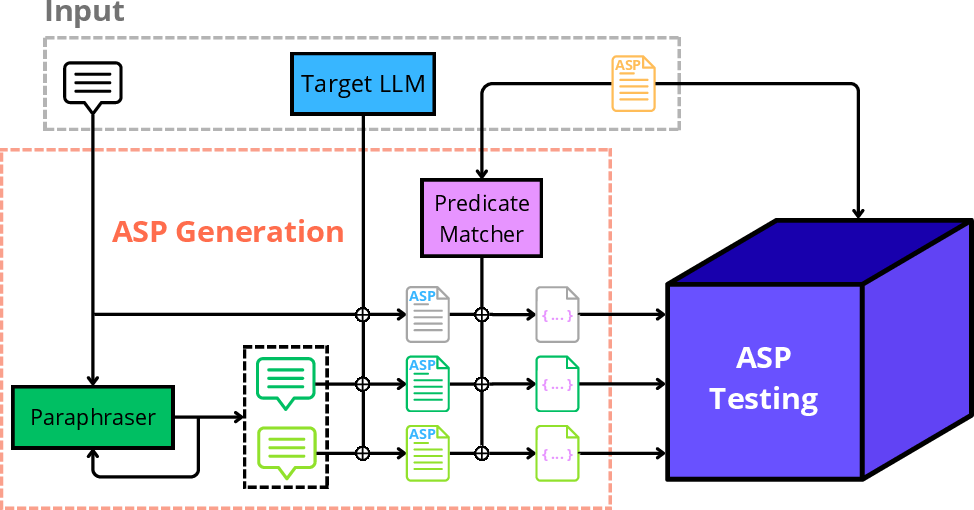
Figure 1: Overall BLAST framework, encompassing natural language problem specification, the target LLM for ASP code generation, predicate matching normalization, and automated semantic testing.
ASP programs are generated from natural language specifications by the target LLM, without enforced syntactic conventions or architectural model constraints. To ensure fairness in comparing model outputs against the reference solutions (gold programs), the authors deploy an LLM-based predicate matcher, which constructs mappings between predicates in the generated and reference programs. The matcher is agnostic to the original predicate surface forms and encodes the semantic alignment between candidate and reference encodings, mitigating evaluation artefacts caused by mere lexical variation.
Additionally, a paraphraser LLM is used to generate alternative, more human-accessible descriptions of each problem, with the goal of measuring target LLM robustness to problem formulation.
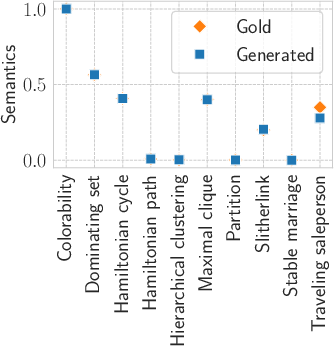
Figure 2: Semantic comparison of gold and generated predicate matchings for DeepSeek-R1, demonstrating high alignment and validating the predicate matcher’s neutrality with respect to naming.
Semantic Metrics: Test-suite-based and Model-based Evaluation
BLAST introduces two complementary semantic evaluation metrics:
- Test-suite-based: Employs the ASP-WIDE unit testing infrastructure to systematically probe specified invariants, constraints, and solution properties, enabling white-box validation. The method quantifies semantic coverage as the fraction of passed test cases, with test suites iteratively refined via mutation analysis to ensure high discriminative power.
- Model-based: Directly evaluates the correspondence of generated and gold stable models over curated input instances. F1-score is computed between the sets of ground models, focusing exclusively on relevant output predicates, abstracting away from otherwise irrelevant syntactic discrepancies.
The predicate matcher bridges the gap between superficially distinct but semantically equivalent encodings, ensuring measured accuracy genuinely reflects logical correctness.
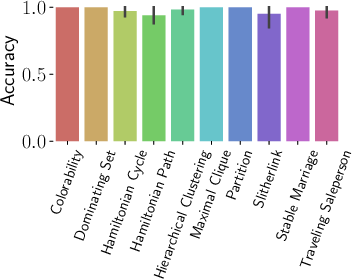
Figure 3: GPT-4o achieves high accuracy as a predicate matcher, with error bars indicating ten-run confidence intervals.
Empirical Results and Analysis
Eight state-of-the-art LLMs—across five architectural families—were benchmarked on ten classical graph problems from the ASP literature. The evaluation demonstrates a marked divergence between syntactic and semantic accuracy.

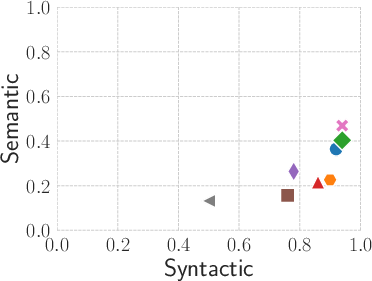
Figure 4: Syntactic (x-axis) versus semantic (y-axis) performance of evaluated LLMs, averaged across all problems; syntactic correctness is consistently higher than semantic.
- All LLMs except LLaMa3.3-70B achieve high syntactic validity.
- Semantic correctness, measured via the test suite, is consistently much lower, accentuating the gap between superficial parsing and deeper logic synthesis.
- There are no models that consistently achieve high semantic accuracy across all tasks.
Problem-wise heatmaps corroborate that the complexity of the specification sharply impacts semantic success: elementary problems such as Colorability or Dominating Set are tractable for several models, but performance degrades drastically for problems with combinatorial or nonstandard constraints (e.g., Slitherlink, Partition).
Impact of Problem Paraphrasing
A central question addressed is whether restating the problem in paraphrased, less technical language improves LLM performance. The results, using DeepSeek-R1 as the testbed, show only minor or inconsistent improvements:

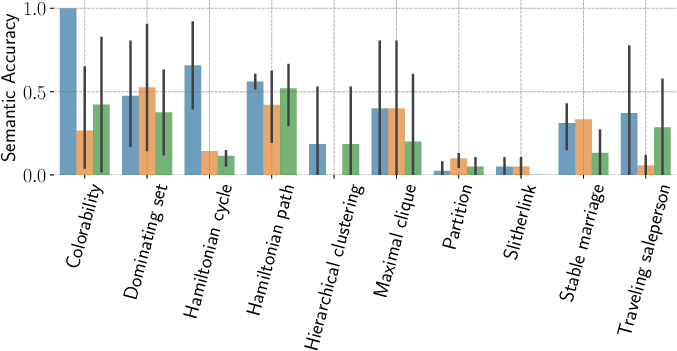
Figure 5: Comparison of test-suite-based semantic accuracy for DeepSeek-R1, contrasting original and paraphrased problem specifications.
In general, the original technical description yields superior or comparable performance, although some individual problem instances benefit slightly from paraphrasing. This suggests that current LLMs are not yet robust to substantial variation in problem statement style when targeting semantic understanding in system programming languages.
Comparison and Efficiency of Semantic Metrics
A direct comparison of the two semantic scores across models and tasks evidences a very strong correlation (ρ=0.865), confirming that the automated, model-based approach closely tracks the more labor-intensive test-suite-based evaluation.

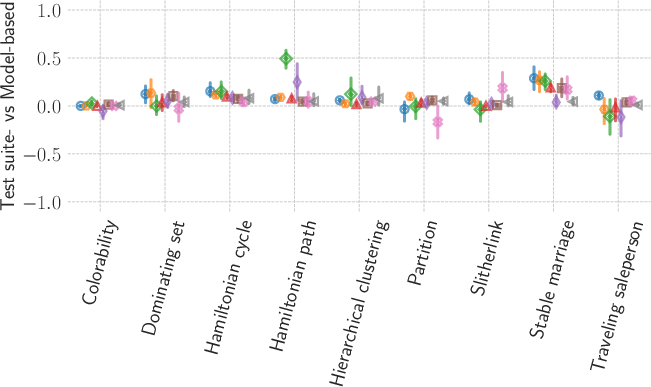
Figure 6: Difference between test-suite-based and model-based semantic metrics for DeepSeek-R1; close alignment is observed except in isolated cases.
Testing times are also compared, showing that the test-suite-based approach is consistently faster in almost all tasks, except for those with high test suite complexity (e.g., Hierarchical Clustering).

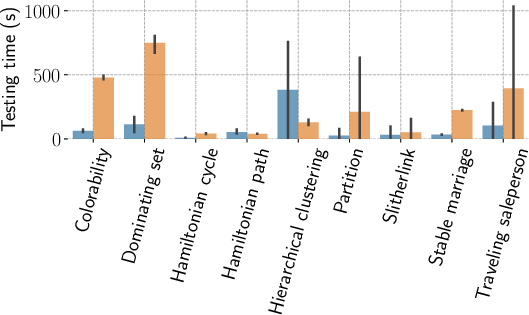
Figure 7: Relative efficiency (execution time in seconds) of test-suite and model-based semantic metrics, showing the significant efficiency of the test-suite approach.
Error Modes and Qualitative Observations
Analysis of output programs reveals recurrent issues, including:
- Missing or insufficient constraint enforcement (e.g., failing to implement bijectivity or path constraints).
- Incorrect predicate signatures and argument mismatches.
- Misplaced or unnecessary constraints, evidencing superficial or heuristic-driven generation rather than deep structural understanding.
These failure patterns manifest even under otherwise successful syntactic parsing, underlining the limitations of LLMs in formal logic synthesis without domain-specialized guidance or architectural adaptation.
Theoretical and Practical Implications
BLAST delivers robust, automated, and scalable benchmarking infrastructure for evaluating LLMs’ declarative programming synthesis capability. Its predicate-agnostic, semantic-centric methodology sets a new standard for evaluation in logic programming generation, essential for future work in neuro-symbolic and hybrid system research.
The empirical findings establish that current state-of-the-art LLMs, even those excelling at imperative code generation, are not yet reliable in producing correct, semantically complete ASP encodings for nontrivial problems. This poses significant challenges for deploying LLMs in critical AI/KR&R pipelines requiring formal correctness and highlights the necessity for complementary techniques such as solver-in-the-loop training, prompt engineering, or fine-tuning on high-volume, domain-specific exemplars.
Prospects and Future Work
Several promising extensions are identified:
- Few-shot and retrieval-augmented prompting may provide the semantic scaffolding needed to close the performance gap observed under zero-shot conditions.
- Extending benchmarks beyond graph problems and into richer domains will enable more comprehensive evaluation.
- The BLAST evaluation protocol is model-agnostic and applicable to logic-centric neuro-symbolic systems, tailored NMT/CNL-based models, and other automatic code generation frameworks.
Conclusion
BLAST establishes rigorous, domain-aligned benchmarks and methodologies for ASP program generation from natural language via LLMs. The approach illuminates both the potential and current constraints of LLMs for declarative logic synthesis, providing a vital substrate for subsequent methodological innovation and practical deployment in AI systems demanding verifiable and interpretable logic program generation.