- The paper presents a game-theoretic model that distinguishes creative effort, which fosters innovation, from mechanistic effort that inflates leaderboard scores.
- It demonstrates that reward skewness reduces benchmark hacking by incentivizing top performers to invest in creative strategies over routine optimization.
- Empirical analysis using Kaggle data validates the theoretical predictions, underlining the importance of contest design in promoting generalizable ML solutions.
Benchmark Hacking in ML Contests: Game-Theoretic Modeling and Empirical Validation
Introduction and Motivation
This work rigorously studies the phenomenon of "benchmark hacking" in the setting of competitive ML contests, where participants' incentives may diverge from the goals of contest organizers. Benchmark hacking refers to disproportionately optimizing for leaderboard performance through tactics that inflate measured success—via excessive trial-and-error or overfitting—while offering little true generalization or theoretical progress. The rise of large-scale ML competitions (e.g., Kaggle) and their real-world impact has rendered this issue both practically and theoretically pressing.
The central innovation of the paper is a formal distinction between two forms of contestant effort:
- Creative effort, which engenders genuine algorithmic innovation, novel representations, or meaningful adaptation of methods; and
- Mechanistic effort, which boosts competition metrics through routine, plug-and-play procedures (e.g., hyperparameter brute-force, established preprocessing, aggressive leaderboard probing) and is usually more susceptible to automation or overfitting.
The authors construct a principal-agent contest game to analyze not only which participants engage in benchmark hacking but also how contest reward structures systematically affect the ratio of creative to mechanistic effort, with implications for contest design and technical benchmarking culture.
Participants (agents) in the model are heterogeneous in their "type," representing overall capability in ML model development, but all face an allocation decision: how much creative (a) and mechanistic (b) effort to invest for a given contest. Model "fitness" is additively determined by a function of these two efforts, with creative effort's productivity supermodular in agent type, reflecting the greater returns of creative actions to more capable participants.
Contest rewards are assigned to players based purely on leaderboard ranking, constructed from performance metrics that are noisy signals of true model fitness. Crucially, while both effort types raise contest metrics, only creative effort aligns with the contest host's ultimate goal (generalization/innovation).
The equilibrium concept is Bayesian Nash. The paper rigorously establishes the existence of a symmetric monotone equilibrium where effort allocations are non-decreasing in agent type.
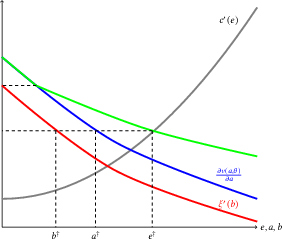
Figure 1: Marginal productivity of creative and mechanistic efforts, with thresholds demarcating regimes where agents only mechanize, allocate both efforts, or only create.
The model allows comparison to a baseline: the effort allocation a single, mature agent would undertake if solving the problem alone (without contest incentives). Under this baseline, agents do not engage in benchmark hacking. A key analytical device is defining benchmark hacking to occur whenever a contestant allocates more to mechanistic, and less to creative effort, than in this baseline.
Theoretical Results: Characterization of Benchmark Hacking
Threshold Phenomena in Effort Allocation:
The analysis yields a sharp partition: there exists a type threshold such that lower-type agents always engage in benchmark hacking (mechanize more, create less than individually optimal), while higher-type agents do not. For types above the threshold, equilibrium effort exceeds the baseline in both axes, but the bias is toward increased creative work.
Effect of Reward Skewness:
A principal design lever for contest hosts is the reward distribution (prize vector) across ranks. The paper formally shows that skewing prizes toward the very top performers induces (for all types) higher total effort and model fitness. Moreover, increased skewness reduces the prevalence of benchmark hacking: more contestants find it (weakly) optimal to prioritize economically valuable creative strategies.
Implications for Contest Design:
- Awarding a small number of large prizes is theoretically preferable if the principal values innovation and generalization, as this structure minimizes benchmark hacking among the better participants.
- Conversely, flatter prize distributions or excessive reward for low-ranked submissions exacerbate misaligned incentives and mechanistic exploitation.
Figure 2: Schematic representation of creative effort intensity across player types and reward structures.
Figure 3: Schematic representation of mechanistic effort allocation across player types and reward structures.
Empirical Validation Using Kaggle Data
The authors conduct an empirical investigation leveraging public Kaggle competition traces (26 contests, 45,103 player-contest pairs). Since creative and mechanistic efforts are not directly observed, effort types are proxy-inferred through patterns in submission score trajectories, with creative effort manifesting as sustained, monotonic improvement and mechanistic effort reflected by volatile, erratic submission sequences.
Key empirical findings include:
- Type monotonicity: Higher-type contestants reliably achieve greater contest fitness.
- Reward skewness: Increased prize skewness (modeled as fewer, larger prizes) is positively associated with improved fitness and greater creative effort, as measured by the Mann-Kendall statistic for monotonic score improvements.
- Benchmark hacking prevalence: Lower-type players show a significantly greater tendency to rely on mechanistic effort, providing external validation of the threshold prediction.
These associations hold under regression specifications controlling for contest-specific effects and are robust to subsample and model choice.
Broader Implications and Future Directions
This study reframes common contest pathologies—overfitting, leaderboard probing, and lack of breakthrough innovation—as equilibrium phenomena driven by contest design and participant heterogeneity. The model provides a formal microfoundation for the impact of prize distribution and types on emergent effort allocations, lending theoretical support to contest design interventions.
Practically, the results suggest:
- Concentrating rewards among top ranks promotes creative, generalizable solutions and suppresses over-mechanization.
- AI-driven automation will likely further compress the value of mechanistic effort, raising the relative worth (and contest focus) of creative, problem-specific innovation.
Future work may:
- Analyze dynamic contest feedback (e.g., public leaderboards, partial information revelation) and their effect on strategic allocation.
- Extend the model to collaborative/teaming scenarios or investigate the role of automated agents in lowering the cost of mechanistic actions.
- Bridge to robust contest architectures that further incentivize genuine generalization while mitigating reward hacking.
Conclusion
This work offers a rigorous game-theoretic treatment of benchmark hacking in ML contests, distinguishing creative from mechanistic effort and linking strategic effort allocation to agent type and contest prize structure. The model's predictions are borne out in large-scale empirical analysis of contestant behavior. The results position contest design—not just evaluation metric engineering—as central to fostering robust ML innovation and mitigating adversarial, over-mechanized competition outcomes.