- The paper introduces DROL, a dynamic routing mechanism that decouples pointwise latent-to-action correspondence to preserve multimodal support in offline RL.
- The methodology uses a top-1 winner routing strategy that localizes behavior cloning updates, enabling candidate specialization and reducing global averaging bias.
- Empirical results on OGBench and D4RL benchmarks demonstrate that DROL achieves competitive performance with efficient one-step inference and improved task adaptability.
Dynamic Routing for One-Step Actors in Multimodal Offline Reinforcement Learning
Offline reinforcement learning (RL) in the multimodal setting requires optimizing a policy under a strict support constraint: policy actions should remain within the local action neighborhoods supported by an offline dataset. Traditional one-step actors, especially in multimodal or complex generative settings (e.g., OGBench), are typically distilled from stronger iterative teachers under a pointwise correspondence constraint, as exemplified by Flow Q-Learning (FQL). This approach enforces that for each sampled latent, the student output must compromise between maximizing the critic and staying near a specific teacher-generated action—a suboptimal strategy when the data support is inherently multimodal and local ownership of the support should be flexible.
Methodology: Dynamic Routing for Offline RL (DROL)
DROL introduces a top-1 dynamic routing mechanism for one-step actors, explicitly designed to decouple pointwise latent-to-action correspondence in favor of support preservation. For each state, K candidate actions are sampled from a bounded latent prior. During training, each dataset action is routed to its nearest candidate, and only that winner receives the actor update via behavior cloning (BC) and critic improvement. Crucially, this routing is computed based on the current set geometry, allowing ownership of local support regions to transfer across candidates as learning progresses.
This mechanism is visualized in the following schematic:
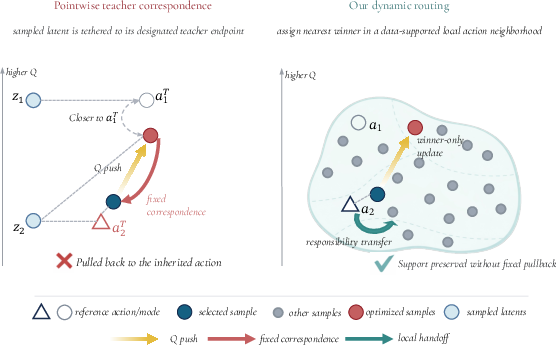
Figure 1: Under pointwise extraction (left), every improvement and reconstruction is assigned to the same sampled output, enforcing rigid correspondence. DROL (right) dynamically routes each dataset action to its nearest candidate, allowing flexible ownership and specialization within the support.
DROL's update only affects the routed winner per offline state-action pair, making BC a local rather than global constraint. At test time, the actor operates with a single latent sample—retaining the computational efficiency of one-step extraction.
Mechanism Analysis
The DROL framework induces a Voronoi partition of the action space for each state, with each candidate action responsible for the local support region closest to it:
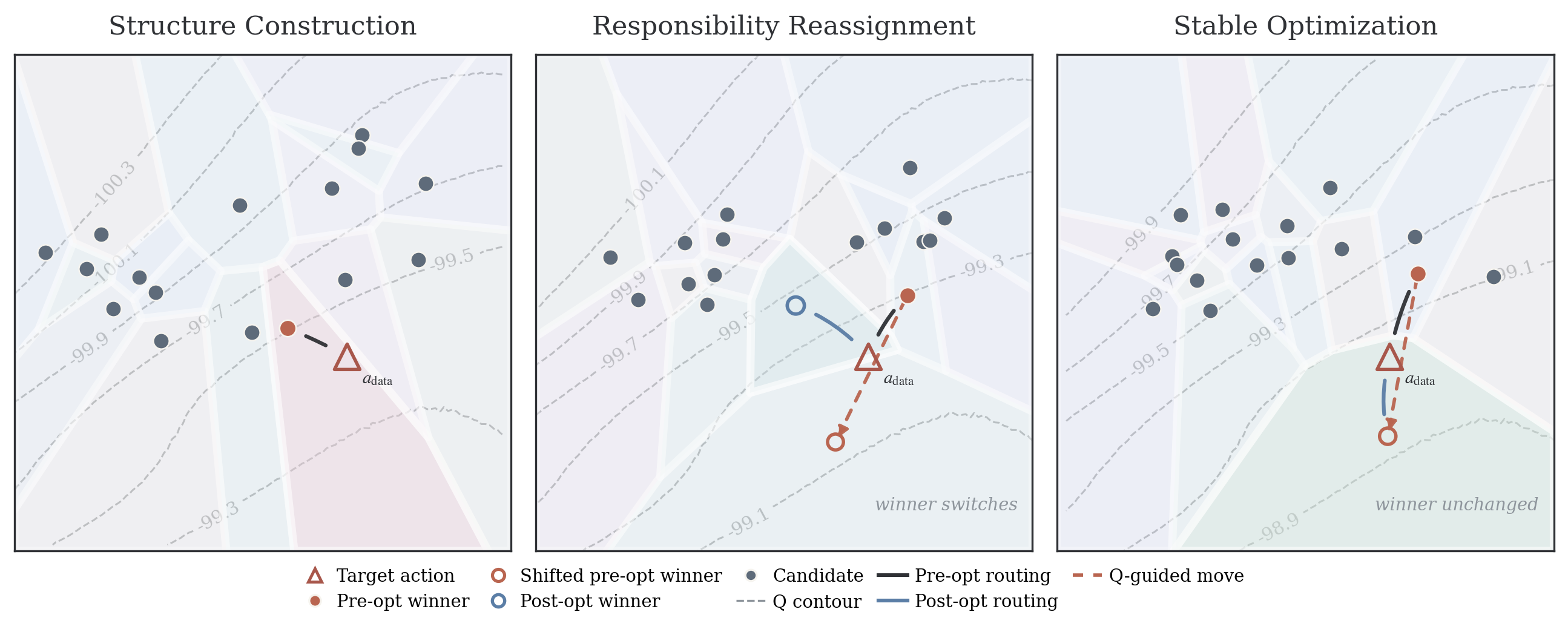
Figure 2: The candidate set initially spreads to cover support (left), followed by responsibility reassignment (center), and stabilization (right) as the actor and critic evolve.
This routing mechanism localizes the BC loss and enables candidates to specialize, alleviating the collapse towards a global mean. Theoretical analyses, including dispatch models on separated support intervals, rigorously demonstrate that routed winner-only updates avoid the reductive averaging present in global BC and foster local specialization.
A formal comparison of pointwise vs.~routed objectives reveals that persistent tethers in the former induce undesirable bias toward initial targets, even when a better local improvement exists. DROL's winner-only routing dynamically reassigns responsibility, permitting a candidate to move toward a higher-Q action while other candidates inherit responsibility for previous support regions as the partition adapts.
Results: Empirical Validation and Tradeoffs
DROL is evaluated on OGBench and D4RL benchmarks. Results establish that a straightforward one-step actor with DROL routing matches or surpasses FQL in numerous multimodal domains, despite the latter's heavier iterative inference and pointwise correspondence constraints:
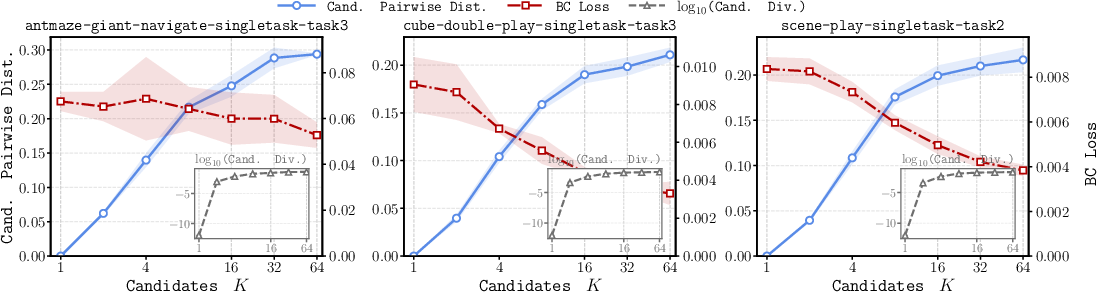
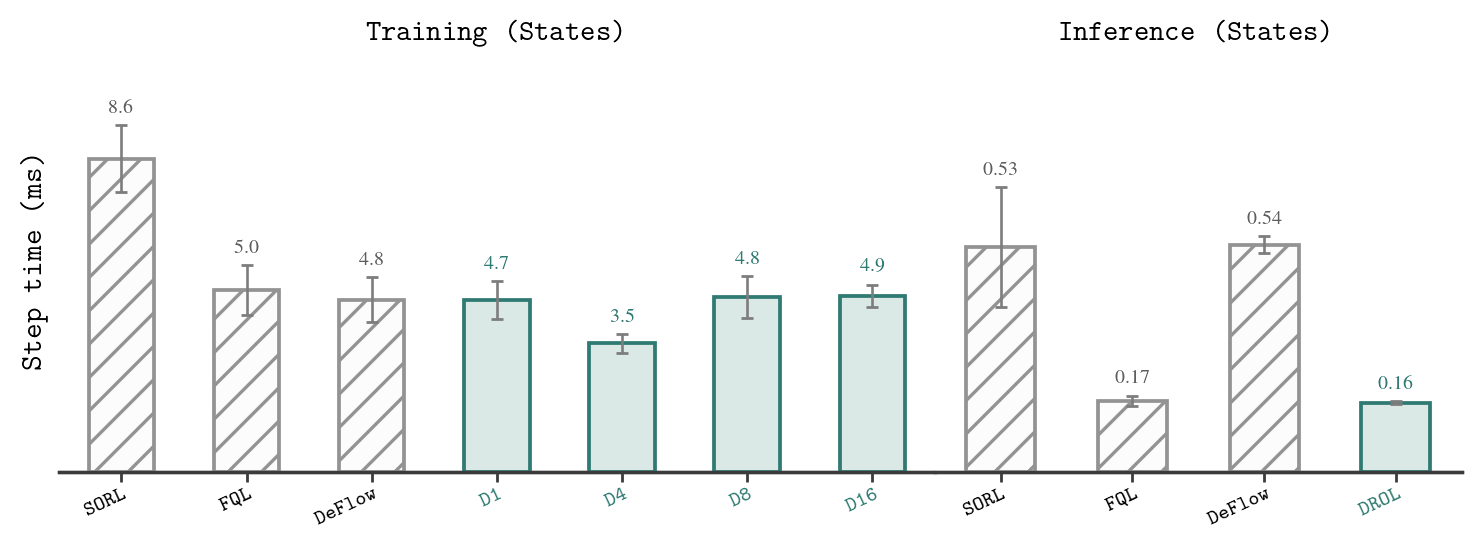
Figure 3: Training performance and runtime demonstrate that increasing the routing budget K enhances candidate diversity and reduces BC loss, with negligible inference overhead compared to FQL.
The candidate set does not collapse with growing K; instead, candidates diversify, quantizing the support neighborhood more finely. The BC reconstruction loss monotonically decreases with K, supporting the geometric interpretation advanced in the theoretical analysis.
Sensitivity analyses show that task families with highly multimodal support (e.g., antmaze-giant) gain substantially from increased K, while simpler families may saturate with smaller candidate sets:
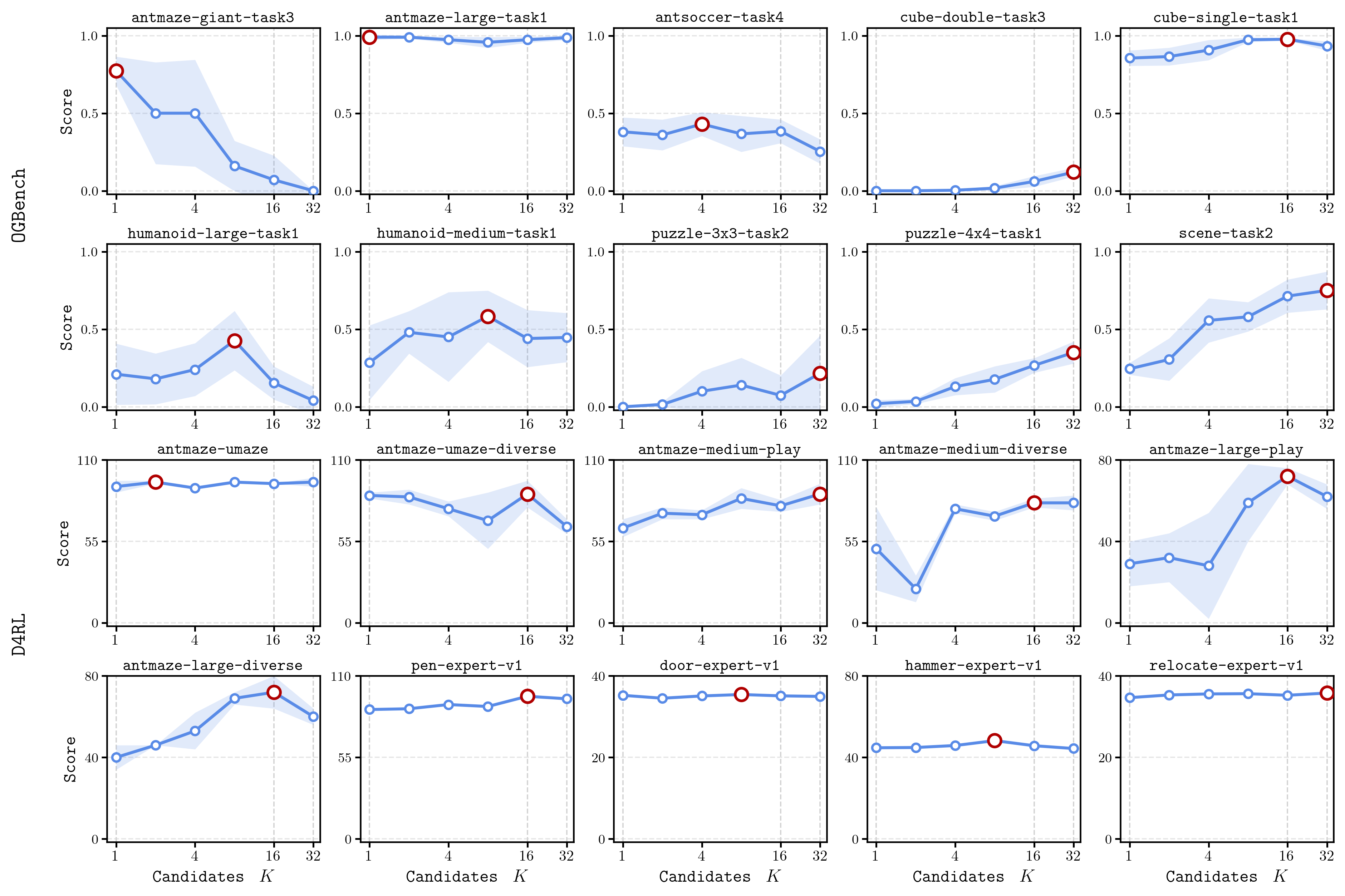
Figure 4: Representative K-sweeps highlight that larger candidate sets improve performance in multimodal domains, but optimal K is task-dependent.
Theoretical Implications
DROL reframes regularization in policy extraction: rather than enforcing sample-wise latent-to-action consistency, it leverages set-level nearest-neighbor matching to preserve local support. This transition from correspondence preservation to support preservation aligns more faithfully with the underlying geometry of the multimodal data distribution, as evidenced both by theoretical dispatch models and practical benchmark gains.
Practical and Future Directions
Practically, DROL maintains single-pass inference, incurring additional complexity only in the form of batch-able candidate set evaluations during training. The runtime remains comparable to other one-step architectures while matching or exceeding iterative baselines in several challenging settings. However, it introduces hyperparameters such as the routing budget K and relies on Euclidean distances and hard winner-takes-all routing.
Potential extensions include:
- Adaptive or learned routing metrics in place of hard Euclidean distance.
- Dynamic candidate set sizing, possibly using softer responsibility allocation.
- Further geometric regularization schemes operating at the region level.
These directions aim to address limitations around fixed K, rigidity of current routing, and to more accurately balance BC and Q-improvement.
Conclusion
DROL establishes that pointwise actor-teacher correspondence is not essential in one-step offline RL extraction on multimodal benchmarks. Dynamic support-based routing enables one-step actors to match or surpass the effectiveness of iterative and multi-step methods in key domains, without sacrificing inference efficiency. This geometric perspective on actor extraction opens several avenues for more flexible, support-aware policy learning in offline RL.

