- The paper presents a multi-LLM pipeline with a feedback loop that refines candidate goals through iterative evaluation.
- It compares Zero-shot, One-shot, and Few-shot prompting, showing Zero-shot's effectiveness with a 61% F1-score for low-level goal identification.
- The study emphasizes that robust prompt engineering for the evaluator LLM is crucial to balance precision and recall in semi-automated requirements extraction.
Evaluating LLM-Based Goal Extraction in Requirements Engineering: Prompting Strategies and Their Limitations
Architectural Overview and Goal Extraction Pipeline
The paper presents a structured LLM chain for automating the Goal-Oriented Requirements Engineering (GORE) process by decomposing goal extraction into sequential phases: actor identification, high-level goal extraction, and decomposition into low-level functional goals. The architecture leverages two distinct LLMs—GPT-4 serving as the generator and Llama 3.3 70B acting as the evaluator—integrated through an iterative feedback loop. The generator produces candidate goals from documentation, while the evaluator scores these outputs and feeds critiques back to the generator, enforcing refinement until a quality threshold is met or a fixed iteration limit is reached. This loop is empirically capped at three iterations to balance accuracy and computational cost.
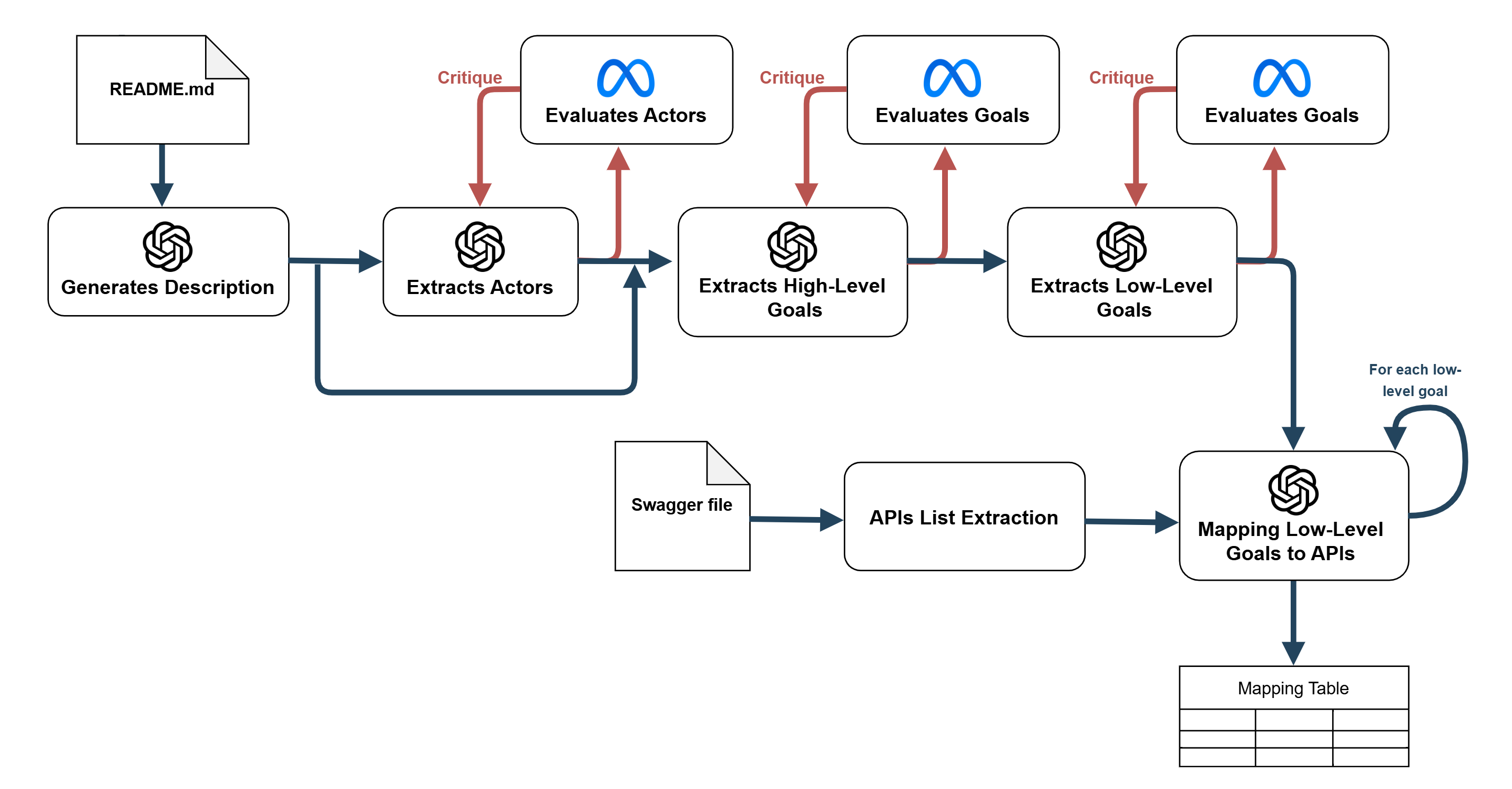
Figure 1: Schema of the proposed architecture, consisting of a LLM chain.
The pipeline optionally preprocesses software README files to yield concise natural language descriptions, followed by actor extraction, high-level goal identification per actor, and hierarchical decomposition to low-level actionable goals. API mapping is included conceptually to illustrate traceability but is not exhaustively evaluated.
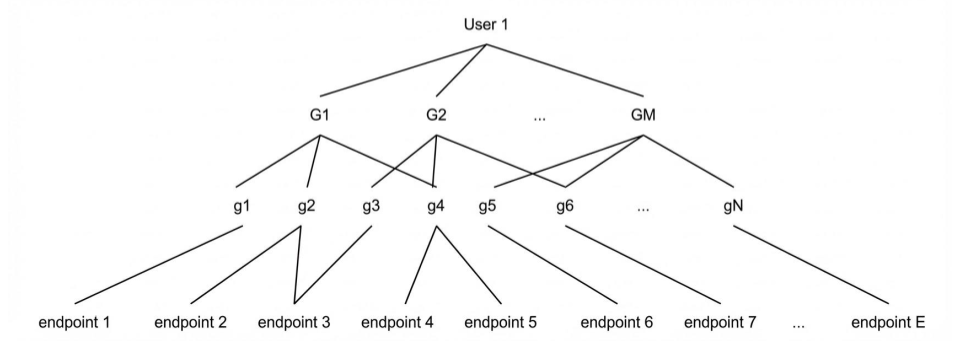
Figure 2: Schema representing the hierarchical decomposition of high-level goals.
Prompt engineering is central: the generator LLM is prompted via Zero-shot, One-shot, or Few-shot methods, employing three manually curated exemplars per task. The evaluator (Llama) is restricted to Few-shot prompting due to observed scoring insensitivity in the absence of reference anchors. Outputs are structured using Pydantic for schema conformity, and priming strategies are used to frame the task and guide output quality.
Empirical Evaluation and Prompting Strategies
Evaluation leverages BERT-based embeddings for cosine similarity between generated and ground truth annotations, solving a Maximum Weight Bipartite Matching problem to pair candidate and reference entities/goals and derive precision, recall, and F1-score via BERTScore. Datasets include enterprise applications, a well-established GORE case study (London Ambulance Service), and a manually annotated academic use case.
The pipeline's accuracy in low-level goal identification peaks at 61% F1, with strong trade-offs observed between precision and recall across prompting strategies. Zero-shot prompting systematically outperforms One-shot and Few-shot in the full architecture, particularly in actor and goal extraction. However, ablation studies reveal that Few-shot prompting improves performance in a standalone GPT setting, while the feedback-loop dampens the benefits of additional exemplars, implicating the prompting strategy applied to the critic LLM as a primary performance bottleneck.
Strong numerical results are reported:
- Actor extraction: Zero-shot achieves highest F1 (0.76); One-shot maximizes recall (0.80), Few-shot delivers highest precision (0.78).
- High-level goal extraction: Zero-shot achieves best combined precision (0.63), recall (0.61), F1 (0.62).
- Low-level goal extraction: Zero-shot produces highest F1-score (0.61); ablation reveals possible error propagation, setting a performance ceiling.
A pronounced correlation exists between the precision achieved on individual datasets and the cosine similarity of ground truth descriptions to Few-shot exemplars in the evaluator's prompt, suggesting that the critic LLM’s prompt diversity and quality are critical for robust performance. This correlation is not observed for recall or F1-score.
The introduction of the feedback mechanism with Zero-shot prompting consistently outperforms Few-shot prompting applied solely to GPT. Ablations show marginal improvements for actor extraction with feedback removal, but substantial benefits for goal extraction tasks. The feedback loop thus acts as a regularizer, constraining random effects introduced by exemplars but limiting the exploitation of in-context learning.
Limitations and Threats to Validity
Several limitations constrain external and construct validity:
- Evaluation is limited to functional requirements, omitting non-functional goals which are crucial in real-world RE, and relies on annotated README files as proxies for stakeholder-driven requirement artifacts.
- The set of Few-shot exemplars is manually curated and limited, which may cause bias toward higher performance in datasets closely resembling the examples.
- The multi-step pipeline enforces waterfall progression, precluding late-stage goal discovery or revision typical in GORE obstacle analysis.
- Results are sensitive to architecture, specific LLMs, and infrastructural parameters (quality thresholds, iteration limits).
- API mapping is exploratory, lacking rigorous evaluation of alignment between extracted goals and endpoint documentation.
The feedback mechanism’s efficacy is contingent on the diversity and representativeness of Few-shot examples given to the evaluator LLM; insufficient coverage causes scoring insensitivity and diminishes refinement quality.
Practical and Theoretical Implications
Practically, the architecture demonstrates that LLM chains can accelerate goal extraction in RE, functioning best as a semi-automated assistant rather than a replacement for manual curation. Systematic errors and performance ceilings indicate that human-in-the-loop strategies remain necessary. Precision and label coverage limitations, especially in low-level goals, implicate error propagation through sequential phases, demanding iterative cross-phase revision mechanisms and improved prompt engineering for refinement.
Theoretically, results corroborate prior work advocating multi-agent and iterative LLM-based workflows for software engineering tasks. The feedback-loop architecture provides improved robustness over isolated LLM querying, but also uncovers intrinsic limitations in current prompting methodologies: the inability of Few-shot exemplars to scale precision without substantial diversity and the lack of nuanced evaluative anchors for the critic LLM. These findings align with evidence from SRE literature that rigorous prompt construction is as essential as model selection.
Future research directions include:
- Augmenting the pipeline with Retrieval-Augmented Generation (RAG) and Chain-of-Thought (CoT) prompting to diversify exemplars and improve reasoning accuracy
- Extending datasets and repeating runs to test stability and generalization
- Integrating human feedback and evaluation throughout iterative loops
- Revising architecture to enable late-stage goal revision and obstacle analysis
- Incorporating domain-specific knowledge into the critic prompts
Conclusion
The paper delivers a detailed empirical evaluation of multi-LLM goal extraction in RE, showing that feedback-based iterative refinement is more effective than monolithic LLM querying but remains bounded by prompt quality, particularly at the evaluator stage. Despite attaining an F1-score of 61% in low-level functional goal identification, results indicate the architecture is most useful as an assistive tool for accelerating manual RE processes, rather than a fully automated solution. Future enhancements should focus on expanding in-context example diversity, integrating retrieval-based prompt augmentation, and incorporating formal human-in-the-loop mechanisms to systematically improve recall and interpretability.

