- The paper demonstrates that LLMs recognize harmful situations but systematically fail to convert this recognition into actionable authorization compared to community norms.
- Methodologically, the study leverages lexicon-based metrics and a 70-category taxonomy derived from 11,565 Reddit posts to quantify advisory divergences.
- The findings highlight the need to recalibrate LLM safety alignment to preserve community-specific vernacular competence and ensure effective directiveness in high-risk advice contexts.
Recognition Without Authorization: A Critical Analysis of LLMs and the Moral Order in Online Advice
Introduction
"Recognition Without Authorization: LLMs and the Moral Order of Online Advice" (2604.22143) presents a systematic comparative analysis between assistant-style LLM outputs and Reddit’s r/relationship_advice community advice. The study situates LLMs in the context of platform-specific normative economies, using 11,565 carefully selected Reddit posts as a baseline for evaluating the intersection of algorithmic safety-alignment and vernacular competence. Leveraging lexicon-based metrics and a robust taxonomy of relationship problems, the work quantifies and qualifies the divergence between LLM advisory defaults and concentrated, community-endorsed forms of judgment.
Conceptual Framework: Vernacular Competence and Defamiliarization
The paper frames the community’s advice-giving as instantiating vernacular competence: the socio-linguistic capacity to map recognition of harm onto actionable, authorizing judgment. This stands in contrast to LLMs, whose outputs, shaped by alignment—principally via RLHF and corporate risk-mitigation—demonstrate a portable advisory style dominated by validation, hedging, and therapeutic process. The distinction foregrounds "recognition without authorization": models reliably register harm but fail to transfer deontic authority, i.e., to grant socially ratified permission for decisive action.
Methodological Rigor: Taxonomy, Corpus, and Metrics
A multi-stage process underpins the analysis: independent topic categorization by six diverse LLMs yields a fine-grained 70-category taxonomy, maximally surfacing boundaries between “harm” and “neutral” narratives. Four production LLMs (Gemini 2.5 Flash Lite, GPT-4.1-nano, DeepSeek v3.2, Ministral 8B) generate responses to each post without persona or genre cues. Comparative evaluation against highest-voted community comments employs lexicons for epistemic stance, leave-orientation, therapeutic framing, and a gradient of permission language aligning with Stevanovic and Peräkylä’s deontic authority transfer spectrum.
Validation against human pairwise judgments reveals high reliability for directional distinctions, confirming that the large-scale, coarse-grained operationalizations capture substantive, reproducible stylistic and functional divergences.
Main Findings: Patterns of Divergence
The LLMs’ divergence from r/relationship_advice norms persists at all analytic levels: problem recognition, action prescription, and language of authorization.
- Perceptual Divergence: LLMs vary on what constitutes “harm,” with 82.2% of posts lacking unanimous harm-normal classification across models. Even when all models identify harm, their cautiousness in prescribing action barely shifts.
- Therapeutic Flattening: Therapeutic language is deployed by LLMs at uniform, elevated rates across all topics, in stark contrast to community responses where deployment is selectively concentrated (Figure 1).
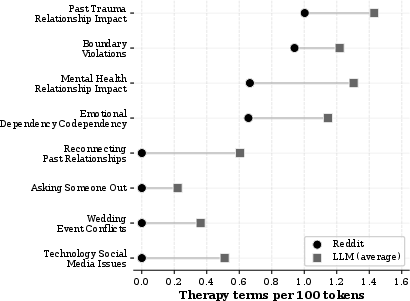
Figure 1: Therapeutic language density across eight topics; LLMs show high, uniform deployment, while Reddit advice exhibits large topic-dependent variance.
- Hedging and Sentiment: LLMs employ order-of-magnitude more hedging, elevated positive sentiment, and high rates of validation/entitlement language (e.g., “you deserve respect”), supplanting directive, unhedged judgment (“leave,” “break up”) even in unambiguous harm contexts.
- Permission Asymmetry: LLMs invert the action:validation ratio, prioritizing empathy and non-prescriptive affirmation over concrete action-authorization, effectively denying recipients the functional support necessary for decisively escaping deleterious situations. Community advice shows a 5:1 action:validation ratio, LLMs reverse this to 1:4.
- Consensus Cases Amplifying Divergence: Strikingly, model divergence from community advice is maximized in posts with overwhelming community consensus for action (e.g., leave in cases of abuse)—the most directive cases experience the strongest suppression in LLM responses (Figure 2).
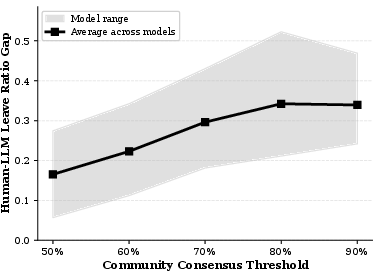
Figure 2: Reddit–LLM divergence in exit recommendations escalates with increasing thread consensus, exposing uniform suppression of directiveness in the models.
- Model Heterogeneity: DeepSeek yields the closest alignment to community norms across key metrics but does not replicate community prescriptiveness; GPT-4.1-nano is the most divergent. However, even with persona prompting, fundamental caution remains, particularly in permission-granting.
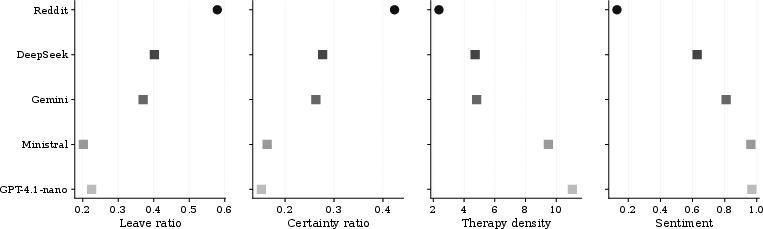
Figure 3: Model-wise comparison across multiple metrics; DeepSeek is consistently closest to Reddit, GPT-4.1-nano furthest, but all models exceed Reddit’s therapeutic language and fall short in prescriptiveness and certainty.
Theoretical and Practical Implications
Normative Alignment Is Not Value Neutral
This analysis challenges the prevailing assumption that LLM safety alignment operates as a benign baseline. The systematic flattening of advisory affect—where context-sensitive prescriptive variation is replaced by portable, risk-averse, therapeutically couched neutrality—has critical sociotechnical consequences:
- Authorization Gap as Functional Risk: For advice-seekers in situations requiring strong action authorization (e.g., abuse, coercive control), the LLM’s reluctance to grant permission may constitute not merely a stylistic variation but a substantive failure of function, potentially impeding harm prevention and escape.
- Algorithmic Monoculture: The cumulative effect of LLM-mediated flattening threatens vernacular diversity—if repeated model-mediated interaction begins to normatively shape online communities, there is potential for algorithmic monoculture and the erosion of locally evolved, high-utility advisory scripts [kleinberg2021algorithmic].
Evaluation and Benchmarking in Context
Existing benchmarks, which optimize for helpfulness, harmlessness, and honesty, ignore the structurally significant dimension of deontic permission. As the findings show, LLMs’ hedging and validation are insensitively applied regardless of situational clarity, suggesting the necessity of new metrics that directly assess permission-granting and directive adequacy vis-à-vis community-concentrated norms.
Alignment as Algorithmic Moral Governance
Safety alignment emerges here as a mechanism of algorithmic moral governance, constraining not only what is said (content filtering) but fundamentally reconfiguring what can be said about social action and agency in advice contexts. It prioritizes corporate risk-aversion and therapeutic individualism over context-specific, directive intervention.
Practical Recommendations and Future Directions
- Recalibrating Alignment: Explicitly tuning LLMs for action-authorization in high-consensus, high-harm scenarios could mitigate practical normative deficits, though this raises non-trivial governance risks.
- Longitudinal Studies: As LLMs increasingly mediate peer advice, longitudinal research will be essential to track the evolution—potentially displacement—of vernacular competence.
- Domain-Specific Fine-Tuning: Supplementing safety-alignment protocols with domain (or community)-specific fine-tuning, perhaps constrained by deontic authority assessment, may restore contextually appropriate directive capacity.
Conclusion
The study rigorously demonstrates that current assistant-style LLMs, while capable of recognizing the same harm patterns as concentrated online communities, fall categorically short in converting recognition to directive action. The "recognition without authorization" phenomenon documented across four distinct models is not a transient technical artifact but a systematic structural effect of alignment protocols and training data averaging. These findings explicate the limits of current normative frameworks for AI evaluation and raise consequential considerations for the deployment of LLMs in sensitive advice-giving settings.
The construct of vernacular competence operationalized here provides a robust lens for future research, demanding nuanced, context-aware approaches to both alignment and evaluation in AI-mediated interpersonal domains. The cumulative normative impacts—from practical missing support for advice-seekers to the risk of algorithmic monoculture—warrant sustained critical scrutiny as LLMs continue to be embedded in sites of everyday moral deliberation.