- The paper proposes a novel hybrid model that combines state-space modeling with sparse patch-mixer attention for efficient, real-time CSI prediction.
- It achieves significant NMSE reductions in both TDD and FDD duplexing modes, outperforming traditional LLM and neural approaches.
- MambaCSP demonstrates linear scaling in throughput, memory usage, and latency, making it ideal for hardware-constrained wireless applications.
MambaCSP: Hybrid-Attention State Space Models for Hardware-Efficient Channel State Prediction
Introduction
MambaCSP addresses the major computational bottleneck in AI-native Channel State Prediction (CSP) by replacing quadratic-complexity LLM backbones with a state-space sequence model augmented by sparse attention. In wireless communication systems, the need for accurate real-time Channel State Information (CSI) prediction is critical for minimizing pilot overhead—particularly in high-mobility scenarios with reduced channel coherence time. Prior transformer-based CSP approaches leverage attention to model long-range dependencies, but their scaling characteristics prevent practical deployment on latency- and resource-constrained hardware. By integrating selective state space models (SSMs) with lightweight patch-mixer attentions, MambaCSP achieves both superior prediction accuracy and hardware scalability.
Unified CSI Prediction Pipeline
The prediction pipeline consists of preprocessing, tokenization, sequence modeling, and projection.
Preprocessing transforms complex-valued historical UL CSI into frequency and delay domain components, then partitions them into temporal patches to reduce sequence length and computational burden. Features are normalized and rearranged, yielding tensors amenable to hardware-friendly processing.
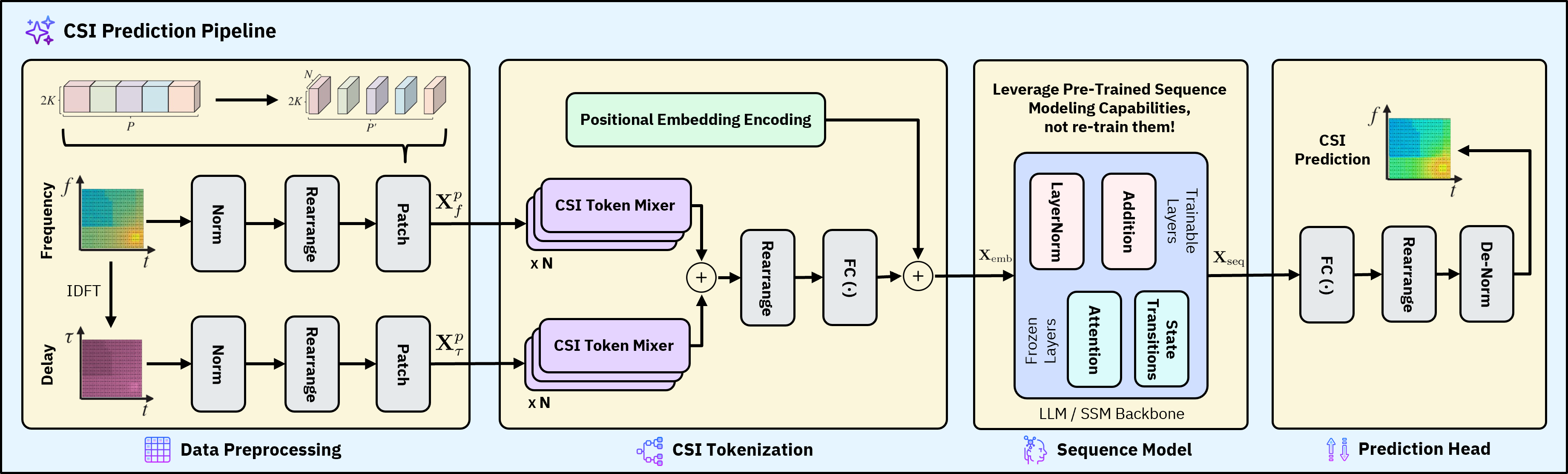
Figure 1: The full CSI prediction pipeline converts UL CSI to frequency/delay components, normalizes, patches, tokenizes, and projects to the complex domain.
Tokenization is carried out by CSI token mixer modules, which use convolutional layers and channel-wise gating to emphasize relevant features and attenuate noise. Multiple mixer modules operate over different representations to capture multipath structure and spectral correlations, followed by sinusoidal positional encoding to preserve temporal order.
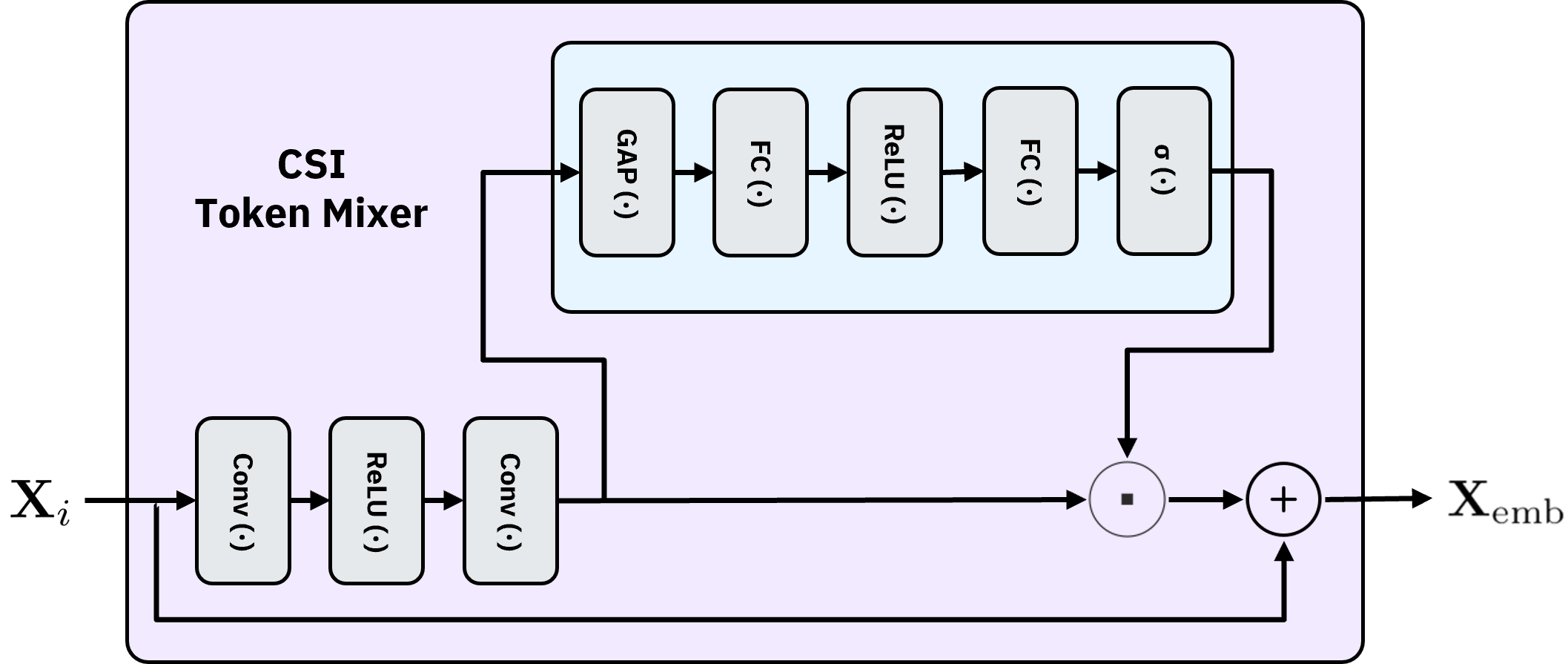
Figure 2: Schematic of the CSI token mixer module, which adaptively reweights features and maintains residual connections for stability.
The processed patches are fed into the backbone sequence model. In MambaCSP, the backbone is largely frozen; the architecture exploits the backbone for spatio-temporal context rather than learned semantic knowledge. Subsequently, a prediction head maps sequence outputs to the complex CSI domain via linear projection and denormalization.
Hybrid MambaCSP Architecture
Mamba extends classic SSMs by parameterizing state transitions and projections as functions of the input, thus making state updates data-dependent. The induction bias of continuous-time modeling and learned Δt step sizes is well-suited for time-varying channel dynamics, such as Doppler shifts encountered in mobile propagation.
Notably, plain SSMs propagate information recursively, limiting their ability to model global, non-local relationships. This is especially problematic in FDD prediction, where cross-frequency dependency is paramount for accurate DL CSI inference from UL history.
MambaCSP addresses this by sparsely injecting patch-mixer attention layers at regular intervals throughout the Mamba backbone. Each patch-mixer layer uses a small set of attention heads to perform cross-token mixing, with residual updates maintaining linear complexity.
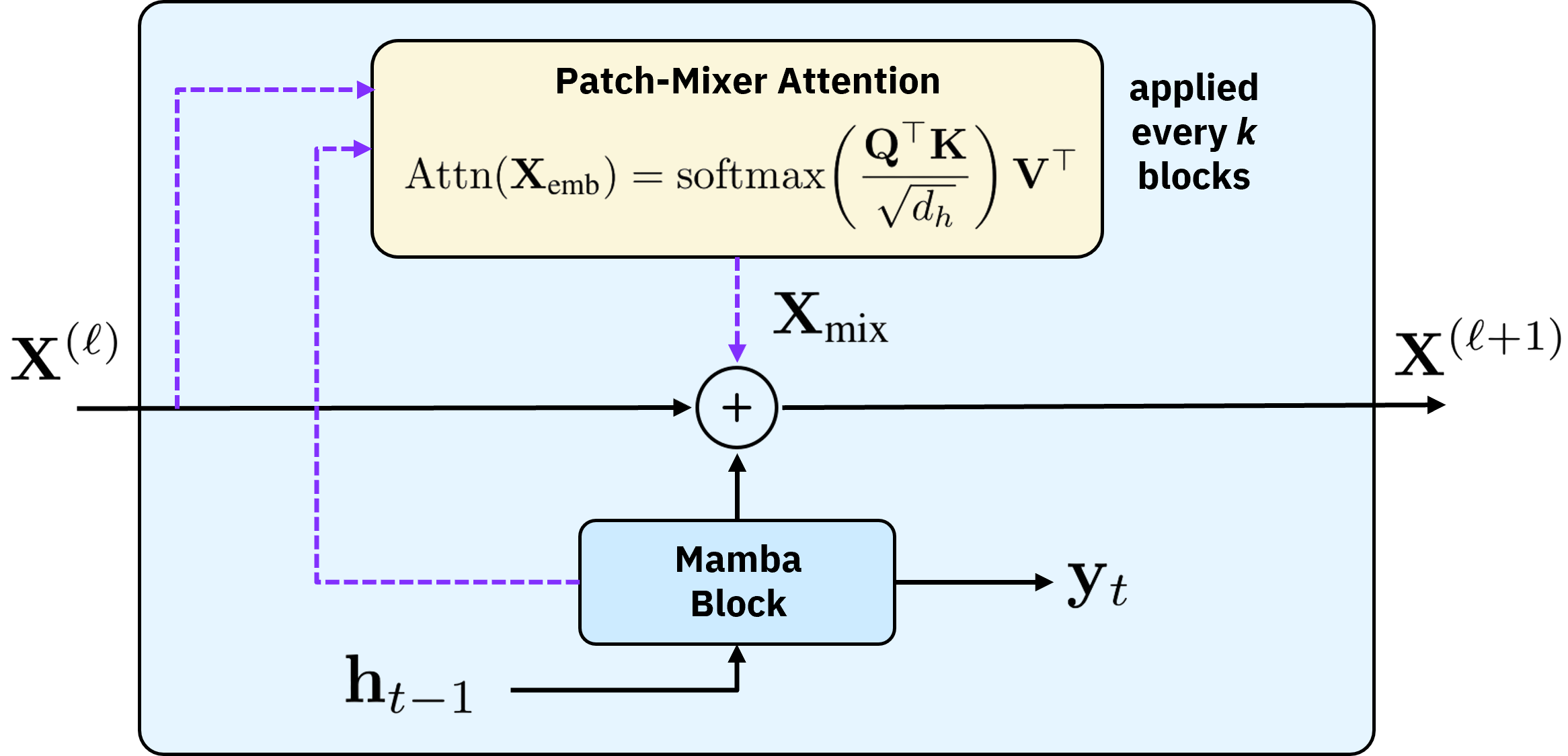
Figure 3: MambaCSP hybrid-attention architecture schema for layer l. Sparse patch-mixer attention is injected every k blocks to restore global modeling capacity.
This design delivers hardware efficiency: Mamba’s compute and memory requirements scale linearly with sequence length, while patch-mixer attention incurs negligible overhead compared to the quadratic scaling in transformer attention mechanisms.
Experimental Evaluation
Empirical results on MISO-OFDM datasets show that MambaCSP outperforms LLM and neural baselines in both TDD and FDD duplexing. For TDD, MambaCSP reduces NMSE by 9% compared to LLM and 5% compared to plain Mamba. In FDD, the hybrid model yields 17% lower NMSE over Mamba and 12% over LLM, particularly under high velocity, where non-local dependencies dominate.
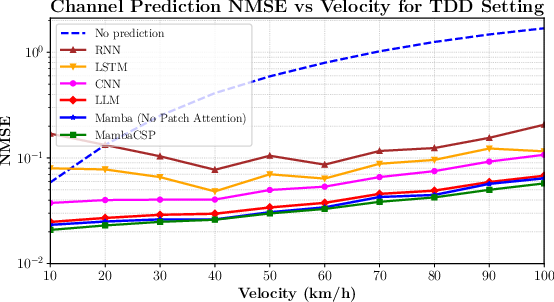
Figure 4: NMSE in TDD increases with velocity; MambaCSP consistently achieves lower NMSE than Mamba and LLM across velocity ranges.
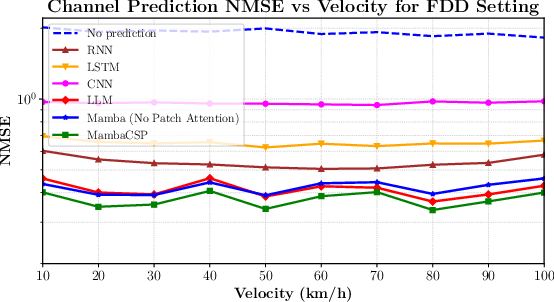
Figure 5: NMSE in FDD is stable across velocities, but MambaCSP outperforms baselines, highlighting the benefit of sparse attention for cross-frequency relations.
Hardware Efficiency
Throughput, memory footprint, and inference latency are benchmarked as the input sequence length increases. MambaCSP achieves up to 3.0× higher throughput, 2.6× lower VRAM usage, and 2.9× lower latency than LLM-based CSP for long CSI patch sequences.
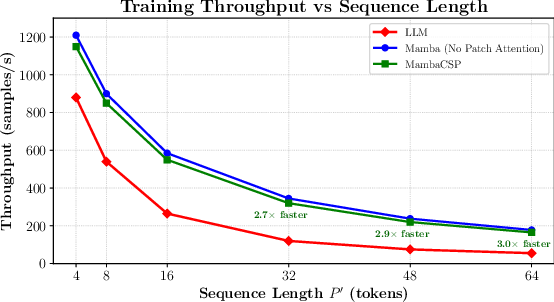
Figure 6: Throughput comparison for varying sequence lengths; MambaCSP matches Mamba and outperforms LLM, especially with longer context windows.
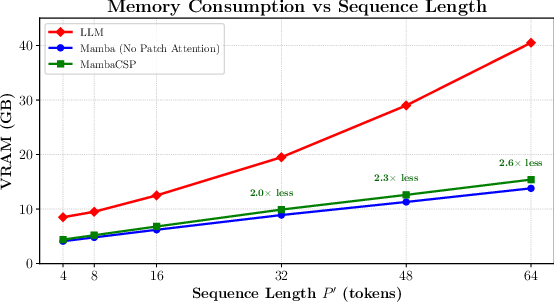
Figure 7: Memory consumption trends; LLM memory grows quadratically due to KV caching, while MambaCSP remains linear.
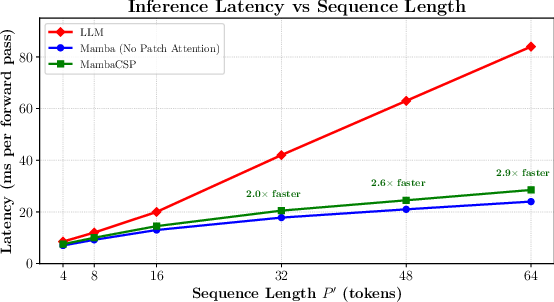
Figure 8: Latency as a function of sequence length. MambaCSP and Mamba scale linearly, while LLM latency increases steeply.
The ablation study indicates that patch-mixer attention with two heads injected every four blocks balances accuracy and efficiency, further supporting the architectural choices.
Implications and Future Directions
MambaCSP demonstrates that SSMs augmented with sparse attention outperform existing transformer-based methods for long-context CSP in accuracy and resource efficiency. This suggests that LLMs are not an optimal design for AI-native CSP pipelines in real-time wireless environments. The ability to scale to longer histories without excessive resource burden opens applicability for edge deployment, 6G baseband AI integration, and distributed inference in mobile terminals.
Further reduction in memory and compute—such as quantization or model pruning—remains unexplored. Additionally, the general framework is extensible beyond CSP, e.g., to other temporal prediction tasks in wireless signal processing or real-time control in communication systems.
Conclusion
MambaCSP offers a principled solution for hardware-efficient, long-context CSI prediction by combining linear-time SSMs with strategically injected attention. The empirical results confirm the superiority of this hybrid architecture over transformer-based and classic neural approaches in accuracy, throughput, memory usage, and latency. This work substantiates hybrid state-space models as a favorable alternative for scalable, resource-aware AI-native wireless applications, and delineates a future direction for efficient architectural design beyond LLMs in communication networks.
(2604.21957)