There Will Be a Scientific Theory of Deep Learning
Abstract: In this paper, we make the case that a scientific theory of deep learning is emerging. By this we mean a theory which characterizes important properties and statistics of the training process, hidden representations, final weights, and performance of neural networks. We pull together major strands of ongoing research in deep learning theory and identify five growing bodies of work that point toward such a theory: (a) solvable idealized settings that provide intuition for learning dynamics in realistic systems; (b) tractable limits that reveal insights into fundamental learning phenomena; (c) simple mathematical laws that capture important macroscopic observables; (d) theories of hyperparameters that disentangle them from the rest of the training process, leaving simpler systems behind; and (e) universal behaviors shared across systems and settings which clarify which phenomena call for explanation. Taken together, these bodies of work share certain broad traits: they are concerned with the dynamics of the training process; they primarily seek to describe coarse aggregate statistics; and they emphasize falsifiable quantitative predictions. We argue that the emerging theory is best thought of as a mechanics of the learning process, and suggest the name learning mechanics. We discuss the relationship between this mechanics perspective and other approaches for building a theory of deep learning, including the statistical and information-theoretic perspectives. In particular, we anticipate a symbiotic relationship between learning mechanics and mechanistic interpretability. We also review and address common arguments that fundamental theory will not be possible or is not important. We conclude with a portrait of important open directions in learning mechanics and advice for beginners. We host further introductory materials, perspectives, and open questions at learningmechanics.pub.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper argues that we can build a real, science-like theory that explains how deep learning (big neural networks) actually works. The authors call this future theory “learning mechanics,” because they think it will look a lot like physics: it will describe how learning moves and changes over time, make clear predictions, and match what we can measure.
What questions is the paper asking?
The paper asks, in simple terms:
- Can we move from “try lots of settings and see what works” to a scientific explanation of why deep learning trains the way it does and performs so well?
- What should that theory look like, and how would we test it?
- What clues do we already have that such a theory is possible?
How do they study it?
This is a big-picture, survey-style paper. The authors don’t introduce a single new experiment. Instead, they:
- Pull together results from many research areas to show patterns that repeat across different models and tasks.
- Use “toy models” (very simplified versions of neural networks) to get exact math results, the way physics starts with simple systems like a spring or a pendulum.
- Analyze “limits,” like imagining a network with infinitely many neurons, to find clean, predictable behavior.
- Collect simple measurement rules (empirical laws) that describe how performance improves as you scale up data, model size, or compute.
- Study hyperparameters (the knobs you set before training, like learning rate) to show they can be chosen more systematically.
- Look for universal behaviors—patterns that show up across many different models and datasets.
Along the way, they translate technical ideas into everyday ones. For example:
- Parameters are like the knobs of a machine that get adjusted during training.
- Training is like pushing a ball down a bumpy hill (the “loss landscape”) so it settles in a good valley.
- Gradients are the directions the ball should roll to go downhill fastest.
- Hyperparameters are the dials you pick before training (like how big each step is).
What are the main findings?
The authors highlight five growing areas of evidence that a scientific “learning mechanics” is emerging. Here they are, with plain-language descriptions and why they matter.
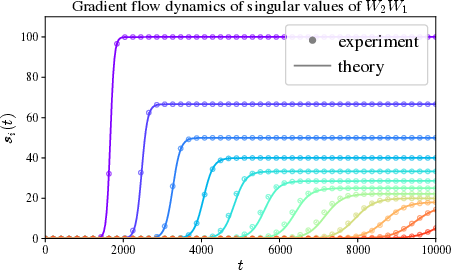
- Solvable toy settings give insight Researchers can fully solve simplified networks and see the whole training story in math. For example, in “deep linear networks” (networks without nonlinearities), the model tends to learn the simplest, strongest patterns in the data first, then moves on to weaker, more detailed patterns. This mirrors what we see in real networks and helps explain why they can generalize.
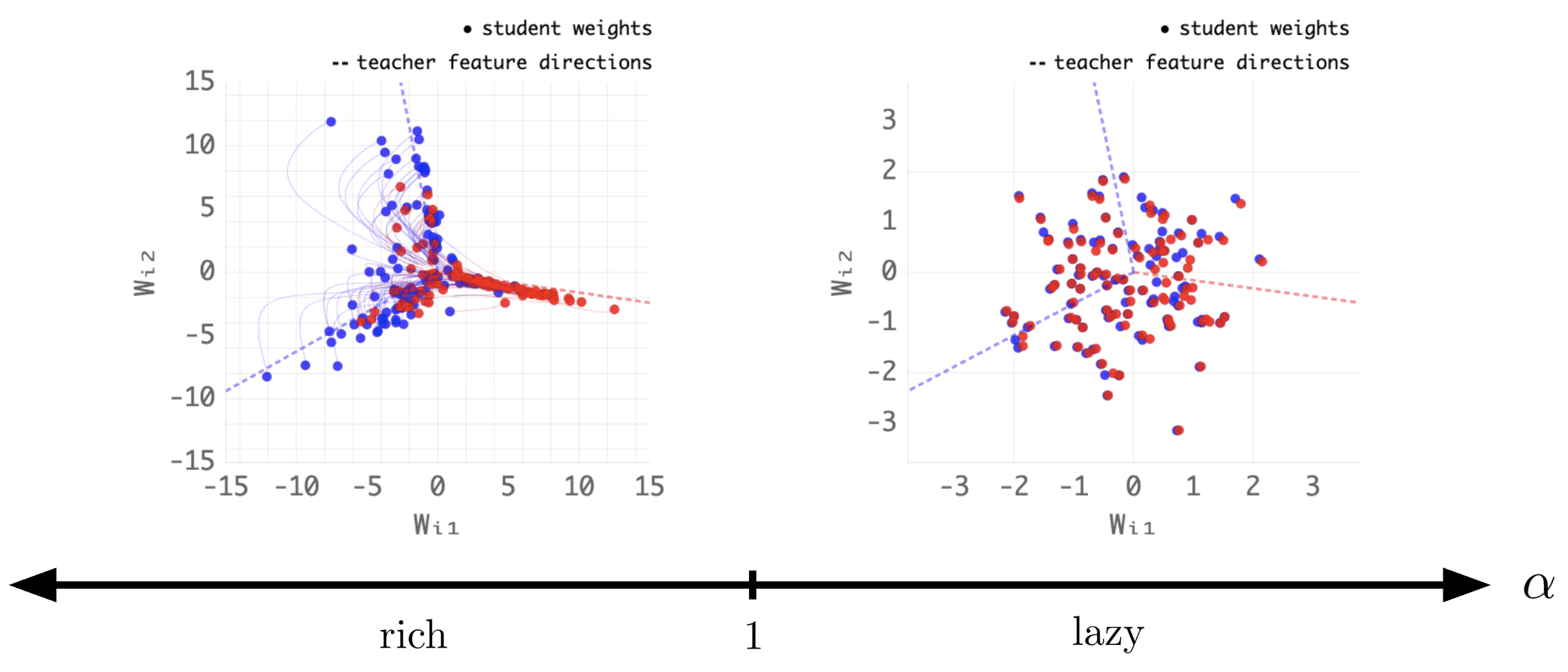
- Simplifying limits reveal clean behavior If you imagine networks with infinitely many neurons, you can see two regimes: 1) “Lazy” learning: features barely change; training looks like a fixed kernel method (more like a linear method in disguise). 2) “Rich” learning: internal features do change; the network really learns new representations. Knowing which regime you’re in helps explain when a network will truly learn features versus acting like a fancy linear model.
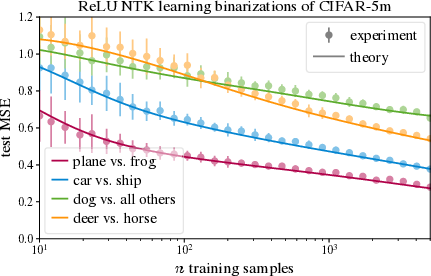
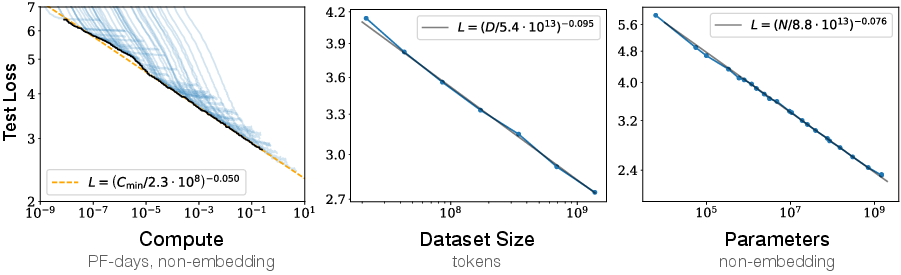
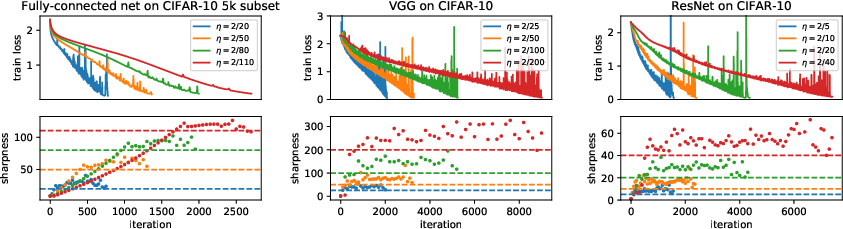
- Simple empirical laws track big-picture trends Scaling laws show how performance improves as you increase model size, dataset size, or compute. These are like “rules of thumb” that consistently predict how much better a model gets when you scale up. Other simple, measurable patterns (like training working best near an “edge of stability”) help guide practice.
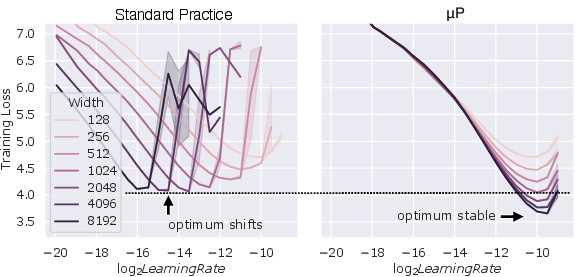
- Hyperparameters can be disentangled and predicted Work on how to set hyperparameters—like how learning rate should depend on network width or depth—shows that many of these “magic numbers” are not magic. With the right formulas, you can choose them more reliably and reduce guesswork.
- Universal behaviors show up across systems Many different models learn similar internal patterns and follow similar training dynamics. When very different systems behave similarly, it usually means there is a shared underlying principle. Finding these repeatable patterns tells us what really needs explaining.
Beyond these five areas, the paper:
- Proposes “learning mechanics” as a name and direction for the theory: like physics, it should be mathematical, predictive, and grounded in first principles.
- Lists seven qualities this theory should have: fundamental, mathematical, predictive, comprehensive (but not needlessly detailed), intuitive, useful, and honest about its limits.
- Explains how this physics-like view complements “mechanistic interpretability” (which is more like biology—studying the parts and circuits inside a trained model). The two approaches can support each other.
Why is this important?
A clear theory of deep learning could have several big impacts:
- Science: It could reveal general principles of learning and representation, and even give clues about natural intelligence.
- Engineering: It could reduce trial-and-error, guide model and dataset design, and help set hyperparameters in a principled way—saving time and compute.
- Safety and oversight: It’s easier to regulate and trust systems we can describe precisely. A theory that identifies the key variables and mechanisms would help with reliability and governance of powerful AI.
Final takeaway
The authors believe that a physics-style theory of deep learning is not only possible but already taking shape. By combining solvable toy models, clean limits, simple laws, better hyperparameter rules, and universal behaviors, we can build “learning mechanics”—a practical, predictive science of how neural networks learn. If successful, it will make AI systems easier to design, understand, and manage, and it will deepen our understanding of learning itself.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored based on the paper’s arguments and evidence.
- Unified nonlinear theory: Develop analytically tractable frameworks that remain genuinely nonlinear in both data and parameters and apply across architectures; current toy models capture isolated phenomena without a unifying framework.
- Defining and measuring “feature learning”: Provide precise, operational definitions and robust metrics for “features” and “feature learning,” and link these to generalization and sample efficiency across training regimes and architectures.
- Predicting lazy vs. rich regimes at finite scale: Derive finite-width/depth/sequence-length conditions (phase diagrams) for transitions between lazy (linearized) and rich (feature-learning) behavior as a function of initialization scale, output multipliers, normalization, optimizer, and data properties.
- Infinite-depth ambiguity: Determine which infinite-depth scaling ( vs. ) best models modern residual/transformer practice under realistic training, and develop diagnostics that distinguish the regimes empirically.
- Joint/proportional scaling limits: Characterize non-commuting limits and proportional scaling laws (e.g., width–depth–sequence length–dataset size–batch size–learning rate–head count/size–MoE expert count), and map regime boundaries where qualitative dynamics change.
- Finite-size/finite-step corrections: Build systematic expansions (e.g., perturbative or mean-field corrections) that quantify deviations from infinite-width/depth/zero-step-size limits at practical scales, with error bars and validity ranges.
- Beyond NTK for inductive bias: Explain how architectural choices (e.g., residual connections, normalization, activation, attention) shape inductive bias in the rich regime where NTK/linearization is inadequate.
- Theory for attention and transformers: Develop solvable or controlled approximations for self-attention (multi-head interactions, context-length scaling, positional encodings, residual streams) that produce quantitative predictions for learning dynamics and generalization.
- Mixture-of-Experts (MoE) dynamics: Theoretically characterize expert routing, specialization, stability, and scaling with expert count and sparsity; derive prescriptions for initialization and hyperparameters that ensure rich feature learning.
- Fine-tuning linearity: Identify when fine-tuning is near-linear vs. fully nonlinear; provide predictors (in terms of task shift, model size, and data) and implications for data/compute efficiency.
- Data distribution realism: Extend theory beyond Gaussian/synthetic assumptions to realistic, structured, non-Gaussian data; relate data geometry/spectra to nonlinear dynamics, implicit bias, and scaling exponents.
- First-principles origins of scaling laws: Derive neural scaling laws (and breaks/phase transitions in exponents) from the joint effects of model capacity, data distribution, optimization noise, and initialization scale in the rich regime.
- Hyperparameter disentanglement at scale: Generalize μP-like prescriptions across architectures (including attention, MoE, layer norm, different activations) and optimizers (Adam-family), and specify how to co-scale learning rate, weight decay, momentum, and normalization.
- Role of stochasticity: Quantify how minibatch noise, data order, and temperature-like parameters alter implicit bias, phase transitions, convergence, and generalization in both lazy and rich regimes.
- Loss-landscape mechanics in rich regime: Connect sharpness, edge-of-stability behavior, and curvature spectra to training dynamics and hyperparameters in feature-learning settings, with predictive control knobs.
- Universality claims: Identify which phenomena are universal vs. architecture/data-specific; develop principled tests and invariants for universality across tasks, scales, and model classes.
- Bridging toy models to practice: Establish validation protocols and finite-sample guarantees that tie predictions from solvable settings to real systems, including explicit domains of applicability and quantitative error bounds.
- Mechanistic interpretability linkage: Formalize how macroscopic “learning mechanics” variables constrain or predict micro-level circuits/algorithms; create bidirectional tests that align circuit-level observations with coarse-grained theory.
- Safety-relevant observables: Identify and model coarse variables (e.g., specialization, capability emergence, out-of-distribution sensitivity) that correlate with risk; provide theory-backed monitoring/control strategies grounded in learning mechanics.
Practical Applications
Immediate Applications
The paper synthesizes emerging “learning mechanics” principles that can already inform tools, workflows, and decisions across sectors. The following applications can be deployed now, given current empirical support and available implementations.
- Mechanics‑aware hyperparameter scaling in training pipelines (software/MLops, cloud)
- Use width/depth parameterizations (e.g., μP/maximal update parameterization) to keep training dynamics invariant across model scales; scale learning rate, initialization, and layer multipliers to maintain target regimes.
- Potential tools/products: “Mechanics‑Aware Trainer” plugins for PyTorch/JAX; config validators that auto‑scale hyperparameters with width/depth; linting for parameterization errors.
- Assumptions/dependencies: Parameterization rules derived from large‑width/depth analyses; may require retraining or re-initialization when migrating to μP; effectiveness highest on modern architectures (e.g., residual/transformer).
- Edge‑of‑stability diagnostics to reduce trial‑and‑error tuning (software/MLops, hardware)
- Log and control curvature/sharpness and learning rate to operate near, but not beyond, the “edge of stability” for faster convergence with fewer collapses.
- Potential tools/products: Sharpness monitors; automatic LR controllers that keep models in stable regimes during long runs; dashboards in training platforms.
- Assumptions/dependencies: Sharpness proxies must be cheap and robust under mixed precision; stability boundaries depend on optimizer and batch size.
- Compute/data planning via scaling laws (finance, product, policy, energy)
- Use neural scaling laws to forecast loss vs. compute/data/model size; budget compute and data collection; set procurement and emissions targets.
- Potential tools/products: “Scaling Planner” that predicts marginal returns to more tokens/parameters; Monte‑Carlo planners for project ROI and carbon impact.
- Assumptions/dependencies: Scaling exponents must be fit in regime of interest; extrapolations can fail near phase transitions (architecture or data regime shifts).
- Fast fine‑tuning triage with linearized (NTK) proxies (software, healthcare, legal, customer support)
- Approximate fine‑tuning outcomes using NTK/kernel ridge regression when updates are near‑linear; decide adapter rank, dataset size, early stopping, and task feasibility before spending large compute.
- Potential tools/products: “Kernel Proxy Evaluator” that predicts few‑shot/LoRA performance; auto‑selection of adapter rank and learning rates.
- Assumptions/dependencies: Near‑linearization holds best for small steps/short horizons and certain objectives; proxies less reliable for heavy feature learning.
- Data curation using spectral/low‑rank learning biases (all sectors; especially healthcare, vision, speech)
- Exploit greedy low‑rank and frequency biases to curate datasets: prioritize high‑signal modes, de‑duplicate near-redundant examples, and stage curricula from simple to complex patterns.
- Potential tools/products: “Data Spectrum Analyzer” that computes input–output correlation spectra; curriculum and pruning policies aligned to learned mode ordering.
- Assumptions/dependencies: Many results assume approximately whitened/Gaussian inputs or least‑squares tasks; needs adaptation to complex multimodal corpora.
- Regime selection: lazy vs. rich dynamics for prototyping vs. production (software, research)
- Choose output/initialization scaling to induce lazy (linearized) dynamics for quick prototyping or rich (feature‑learning) dynamics for final training.
- Potential tools/products: “Regime Detector” that estimates feature drift; initialization/output scaling knobs with safe defaults; warnings when drift is insufficient/excessive.
- Assumptions/dependencies: Relies on monitoring feature evolution; requires architecture-aware scaling of output layers and residual blocks.
- Batch size and optimizer co‑design via gradient noise scale (software/MLops, hardware vendors)
- Match batch size, learning rate, and momentum to measured gradient noise scale for efficient utilization and stable training at scale.
- Potential tools/products: Auto‑batch schedulers that adapt to hardware throughput; guidance for mixed precision and memory budgets.
- Assumptions/dependencies: Noise scale estimation must be online and low‑overhead; interaction with data heterogeneity and curriculum must be handled.
- Reproducibility and benchmark protocols that log mechanics variables (academia, open source)
- Standardize logging of curvature, feature drift, noise scale, and scaling exponents alongside accuracy/loss to make experiments diagnosable and comparable.
- Potential tools/products: “Mechanics Dashboard” integrated in training frameworks; benchmark leaderboards with mechanics-based metadata.
- Assumptions/dependencies: Minimal overhead logging; community buy‑in for shared schemas and metrics.
- Education and upskilling using solvable models (education, workforce development)
- Use deep linear networks, NTK, and toy attention models in labs to build intuition for training dynamics, stability, and inductive biases.
- Potential tools/products: Instructor kits; interactive notebooks; visualization libraries for mode learning and feature drift.
- Assumptions/dependencies: Simplified assumptions (e.g., Gaussian inputs) used for pedagogy must be contextualized for real systems.
- Safety pre‑mortems using early‑warning signals (industry safety, policy)
- Monitor phase transitions, loss‑landscape sharpness spikes, and abrupt representation shifts that correlate with instability or unexpected behavior; gate deployments.
- Potential tools/products: “Go/No‑Go” checklists tied to mechanics metrics; automated alerts on anomalous dynamics during training or fine‑tuning.
- Assumptions/dependencies: Correlational evidence is stronger than causation in many settings; thresholds must be calibrated per model family.
- Energy and cost savings via reduced tuning and failed runs (energy, sustainability, finance)
- Apply mechanics‑guided defaults and diagnostics to cut hyperparameter sweeps and restarts, reducing compute, cost, and emissions.
- Potential tools/products: Optimization of training schedules; carbon‑aware planning linked to scaling law forecasts.
- Assumptions/dependencies: Savings depend on organizational adoption and integration with MLOps; requires robust defaults.
Long‑Term Applications
As “learning mechanics” matures from approximate rules to predictive, first‑principles models, the following applications become increasingly feasible. These typically require further theory, verified approximations, and toolchain integration.
- One‑shot hyperparameter selection with theory‑backed guarantees (software/MLops, cloud)
- Eliminate most tuning by deriving hyperparameters from model/data/task descriptors and desired stability regime.
- Potential tools/products: Certified configuration generators with bounds on stability/convergence time.
- Assumptions/dependencies: Requires validated models of optimizer dynamics across architectures and tasks.
- First‑principles dataset design and augmentation (all sectors; strong fit for healthcare, scientific ML)
- Compute which data modes are most valuable for a target loss frontier; optimize acquisition, augmentation, and curriculum to maximize returns per token/sample.
- Potential tools/products: “Data Designer” that outputs optimal sampling/weighting strategies and augmentation pipelines.
- Assumptions/dependencies: Needs accurate mappings from data spectra to learning curves in nonlinear, multimodal regimes.
- Architecture co‑design from infinite‑width/depth/head limits (software, hardware, robotics)
- Use depth/width/head/expert scaling limits to set robust hyperparameters (e.g., residual scaling, head count) and to pick lazy vs. rich behavior per module (attention, MoE, MLP).
- Potential tools/products: Automated architecture suggesters; head/expert allocation tools for transformers and MoEs.
- Assumptions/dependencies: Joint scaling limits must commute or be characterized; validated on large, modern workloads.
- Hardware–algorithm codesign targeting desired regimes (semiconductors, cloud)
- Design accelerators and runtime kernels that maintain stability and feature‑learning dynamics (e.g., precision, accumulator ranges, fused ops to control noise/sharpness).
- Potential tools/products: “Regime‑Aware” compilers/schedulers; co‑tuned optimizers for specific hardware.
- Assumptions/dependencies: Requires closed‑loop measurements of mechanics variables on‑hardware; collaboration across vendors and researchers.
- Predictive safety and alignment metrics grounded in dynamics (policy, regulated industries)
- Define reportable “state variables” (e.g., curvature bands, feature drift rates, phase boundaries) and link them to risk profiles, with standard tests and thresholds for compliance.
- Potential tools/products: Mechanic‑based certification; audit suites for training runs; documented safety envelopes for fine‑tuning.
- Assumptions/dependencies: Must establish causal links between dynamics and downstream risks; standardization across jurisdictions.
- Mechanistic interpretability fused with mechanics (academia, safety, industry)
- Bridge circuit‑level mechanisms with macroscopic training variables to predict when circuits emerge, change, or “break” under fine‑tuning or scaling.
- Potential tools/products: Tools that forecast circuit formation; change‑point detectors tied to representation dynamics.
- Assumptions/dependencies: Requires robust mappings from microstructure to macroscopic observables; validated across families.
- Robust online/continual learning with stability guarantees (robotics, edge AI, autonomous systems)
- Deploy controllers and perception models that adapt in the rich regime while provably avoiding catastrophic drift, using real‑time regime and stability control.
- Potential tools/products: On‑device regime controllers; adaptive curricula from live data streams.
- Assumptions/dependencies: Theoretical guarantees for non‑stationary, partially observed environments; low‑overhead sensing of mechanics metrics on device.
- Compute‑efficient personalization for consumers (daily life, mobile)
- On‑device adapters optimized via kernel proxies and stability controllers for quick, safe personalization without cloud compute.
- Potential tools/products: Personalization kits that pick adapter rank/LR from device constraints and task descriptors.
- Assumptions/dependencies: Near‑linear fine‑tuning must hold or be correctable; tight memory/latency budgets.
- Sector‑specific reliability playbooks (healthcare, finance, legal, public sector)
- Translate mechanics to domain workflows: e.g., healthcare models with monitored representation shifts during updates; finance models with pre‑set stability budgets and data spectra guardrails.
- Potential tools/products: Domain toolkits with mechanics‑aligned SOPs and dashboards.
- Assumptions/dependencies: Domain‑specific data properties and constraints must be modeled; coordination with regulators.
- Green AI optimization from theory‑based scaling (energy, sustainability, policy)
- Optimize compute schedules and model choices to meet target performance with minimal carbon, guided by predictive scaling and stability models.
- Potential tools/products: Carbon‑aware trainers; procurement tools that plan tokens/parameters/epochs for minimum emissions at target loss.
- Assumptions/dependencies: Accurate emissions accounting and reliable long‑range scaling forecasts.
- Standards and regulation for “mechanics reporting” (policy, consortia)
- Require standardized reporting of scaling exponents, stability margins, and feature‑learning indicators for high‑risk models; inform risk tiers and oversight.
- Potential tools/products: Reporting schemas; compliance dashboards; third‑party audit services.
- Assumptions/dependencies: International alignment on metrics and thresholds; minimal burden while preserving utility.
- Nonlinear theory–driven improvements to model classes (research → industry)
- Mature nonlinear toy models (e.g., attention/feature learning) into design rules that directly improve sample efficiency and robustness in production.
- Potential tools/products: New attention scalings, gating schemes, and regularizers predicted by theory and validated empirically.
- Assumptions/dependencies: Transferability of insights from solvable models to real architectures; thorough ablations on diverse tasks.
Notes on Cross‑Cutting Assumptions and Dependencies
- Regime validity: Many results assume infinite width/depth or specific parameterizations; finite‑size corrections must be understood for given architectures.
- Data assumptions: Several analyses use Gaussian/whitened inputs or least‑squares losses; extensions to multimodal, non‑Gaussian, and generative objectives are ongoing.
- Instrumentation: Real‑time measurement of sharpness, feature drift, and noise scale needs low overhead and standardized implementations.
- Generalization of limits: Lazy/rich, depth/width/head/expert limits and their joint scaling must be validated on modern transformer/MoE stacks.
- Organizational adoption: Benefits hinge on integrating mechanics‑aware defaults and monitors into MLOps, with cultural and tooling support.
Glossary
- Bayes-optimal inference: The ideal Bayesian procedure that achieves the lowest possible average error given a data-generating process. Example: "Bayes-optimal inference and learning dynamics"
- Bernoulli ODEs: A class of nonlinear ordinary differential equations of the Bernoulli type that can be transformed into linear ODEs for solution. Example: "decouple into independent solvable Bernoulli ODEs."
- double descent: A phenomenon where test error decreases, then increases near interpolation, and decreases again as model capacity grows. Example: "double descent"
- edge-of-stability: A regime where training operates near the stability boundary of gradient-based optimization, often producing oscillations. Example: "edge-of-stability oscillations with gradient descent"
- feature learning: The process by which a network’s internal representations (features) adapt during training to capture structure in data. Example: "fail to exhibit feature learning."
- Gaussian processes: Distributions over functions where any finite collection of function values has a joint Gaussian distribution; used to model infinite-width networks at initialization. Example: "Gaussian processes"
- generalization error: The expected difference between a model’s predictions and true outcomes on unseen data. Example: "expected generalization error"
- gradient flow: The continuous-time limit of gradient descent dynamics described by differential equations. Example: "gradient flow learning rule"
- inductive bias: The set of assumptions that guide a learning algorithm toward certain solutions over others. Example: "inductive bias through the NTK eigenstructure"
- kernel methods: A class of algorithms that rely on kernel functions to operate in implicit feature spaces, enabling linear methods to solve nonlinear problems. Example: "deep linear networks and kernel methods"
- kernel ridge regression: A kernelized version of ridge regression that fits functions in a reproducing kernel Hilbert space with L2 regularization. Example: "kernel ridge regression with the NTK"
- LeCun initialization rule: A variance-scaling initialization scheme designed to keep signal magnitudes stable across layers. Example: "LeCun initialization rule"
- Maximal Update Parameterization: A parameterization and scaling strategy that preserves order-one parameter updates at infinite width, enabling feature learning in the limit. Example: "Maximal Update Parameterization"
- mean-field behavior: A simplification where the collective effect of many components is captured by average quantities, ignoring microscopic details. Example: "so-called mean-field behavior"
- mechanistic interpretability: An approach to understanding neural networks by identifying and explaining the internal mechanisms that implement behaviors. Example: "mechanistic interpretability aims to be the biology of deep learning"
- Neural ODEs: Continuous-depth models where residual networks are interpreted as discretizations of ordinary differential equations. Example: "Neural ODEs"
- neural tangent kernel (NTK): A kernel defined by gradients of the network output with respect to parameters at initialization, governing dynamics in the linearized regime. Example: "neural tangent kernel (NTK)"
- overparameterized: Describes models with more parameters than necessary to fit the training data, often enabling zero training error. Example: "overparameterized"
- PAC learning theory: Probably Approximately Correct learning framework providing worst-case guarantees on learnability and sample complexity. Example: "PAC learning theory"
- population gradient descent: Gradient descent computed with exact population gradients (infinite batch size), not stochastic estimates. Example: "population gradient descent"
- random matrix theory: The study of the statistical properties of matrices with random entries, often used to analyze high-dimensional limits. Example: "random matrix theory"
- residual stream: The running state or hidden representation that flows through residual connections in deep residual networks. Example: "the residual stream changes smoothly over depth"
- scaling laws: Empirical or theoretical power-law relations that predict performance as a function of model/data/compute scale. Example: "empirical scaling laws"
- statistical mechanics: A branch of physics that uses probabilistic methods to study systems with many degrees of freedom, often applied to learning theory. Example: "statistical mechanics"
- stochastic differential equation: A differential equation involving randomness, modeling dynamics driven by noise. Example: "stochastic differential equation"
- teacher-student models: Theoretical setups where a “student” model learns from data generated by a known “teacher” function or network. Example: "teacher-student models"
- thermodynamic limit: The limit where the number of components (e.g., particles or parameters) goes to infinity, revealing simplified macro behavior. Example: "thermodynamic limit"
- weight decay: L2 regularization applied during training to penalize large weights and improve generalization. Example: "weight decay"
Collections
Sign up for free to add this paper to one or more collections.

