- The paper demonstrates that adapted AttnLRP yields reliable post-hoc explanations for DNABERT-2, matching CNN methods in biological interpretability.
- The paper introduces novel aggregation/disaggregation strategies to align token- and nucleotide-level attributions, preserving key biological signals.
- The paper confirms that DNABERT-2 explanations are faithful, sparse, and biologically relevant, supporting hypothesis-driven genomics research.
Evaluation of Post-hoc Explanations of the Transformer-based Genome LLM DNABERT-2
Introduction and Context
This paper addresses the critical challenge of interpretability in deep learning models applied to genomics, specifically genome sequence classification. While CNNs have long served as capable and interpretable models for identifying regulatory elements from raw DNA sequences, Transformer-based genome LLMs (gLMs) like DNABERT-2 present a more expressive modeling paradigm by capturing long-range dependencies. The primary aim is to determine whether the reliability and interpretability observed in CNN post-hoc explanations transfer to gLMs, especially considering the nonlinearities inherent in Transformer attention mechanisms.
The researchers adapt AttnLRP—a recent extension of layer-wise relevance propagation specifically designed for attention—enabling its application to DNABERT-2. They systematically evaluate AttnLRP's explanations on multiple axes (similarity, sparsity, complexity, faithfulness, and biological localization) and contrast them with LRP-based explanations from a CNN baseline. Importantly, they propose aggregation/disaggregation strategies to compare explanations across the differing granularities (token-based for gLMs; nucleotide-based for CNNs).
Methodological Details
The adaptation of AttnLRP incorporates custom rules for DNABERT-2's ALiBi and GLU components, employing the uniform redistribution rule from the modified Gradient×Input approach, as operationalized in [arras2025close]. For ALiBi, relevance is equally split between query, key, and the distance-dependent bias; for GLU, between gated and content branches.
To enable comparison between DNABERT-2 (token-level relevance) and CNNs (nucleotide-level relevance), four aggregation/disaggregation strategies are introduced, addressing relevance conservation and dilution:
- Sum aggregation: Total relevance of nucleotides within a token.
- Mean aggregation: Average relevance, potentially diluting strong signals.
- Passed on: Token relevance assigned directly to all constituent nucleotides.
- Equally distributed: Token relevance shared uniformly across nucleotides.
This distinction is crucial, as different aggregation forms affect alignment between explanation maps—particularly when relevant motifs are sparsely distributed within long tokens.
Experiments and Datasets
The empirical analysis leverages two datasets from [gresova2023genomic]:
- Nontata Promoters (Human): Short 251-bp sequences—positive class denotes non-TATA promoters, negative samples are random coding regions.
- Drosophila Enhancers: Long (median 2,142 bp) enhancer regions versus random genomic segments.
The classification baselines employ both a standard CNN and (for Drosophila) DeepSTARR, with DNABERT-2 fine-tuned on each task. DNABERT-2 achieves 94% and 78% test accuracy on nontata promoters and drosophila enhancers, respectively, indicating strong predictive capability.
Qualitative Relevance Attribution
The adapted AttnLRP produces non-random, interpretable relevance maps for DNABERT-2, with notable concentration of relevance in CLS and SEP tokens. As sequence length increases, the relative relevance assigned to internal tokens declines, echoing patterns observed in NLP transformers. For meaningful biological and model comparison, CLS and SEP relevance is excluded and the attribution renormalized.
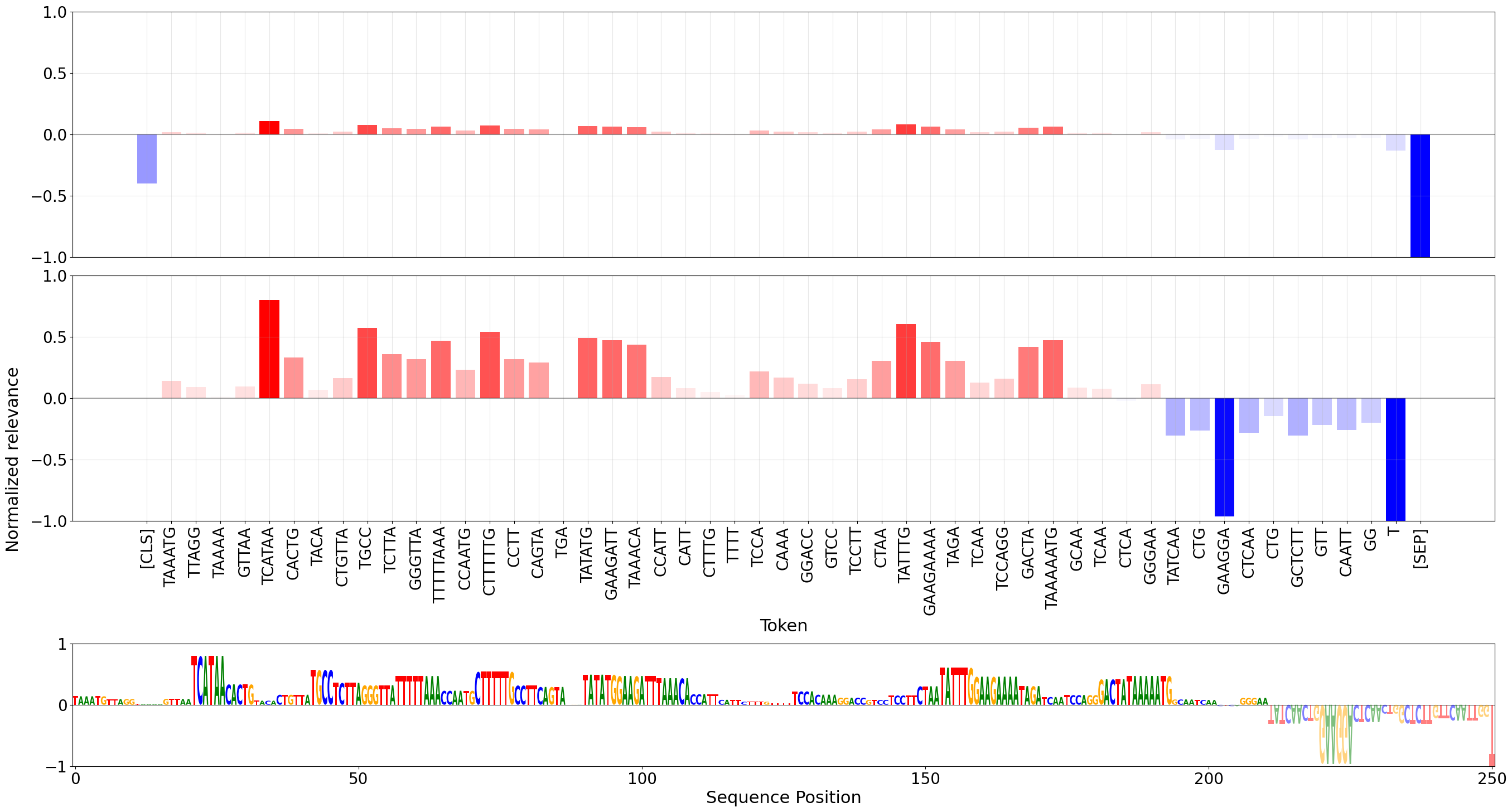
Figure 1: DNABERT-2 AttnLRP relevance attribution for a nontata promoters sample, showing the impact of CLS/SEP removal and the logo plot for nucleotide-level relevance.
Explanation Alignment: Similarity
Continuous Jaccard Similarity (CJ) quantifies overlap between explanation maps from DNABERT-2 and CNN, across aggregation strategies. On the nontata promoters dataset, CJ distributions center around positive values, denoting moderate motif agreement. In contrast, Drosophila enhancer explanations exhibit CJ distributions closer to zero, reflecting less correspondence—primarily due to sequence length and increased signal-to-noise ratio. Strategies preserving total relevance (sum aggregation/equally distributed) dilute key signals, reducing alignment; strategies (mean, passed on) maintain motif correspondence.
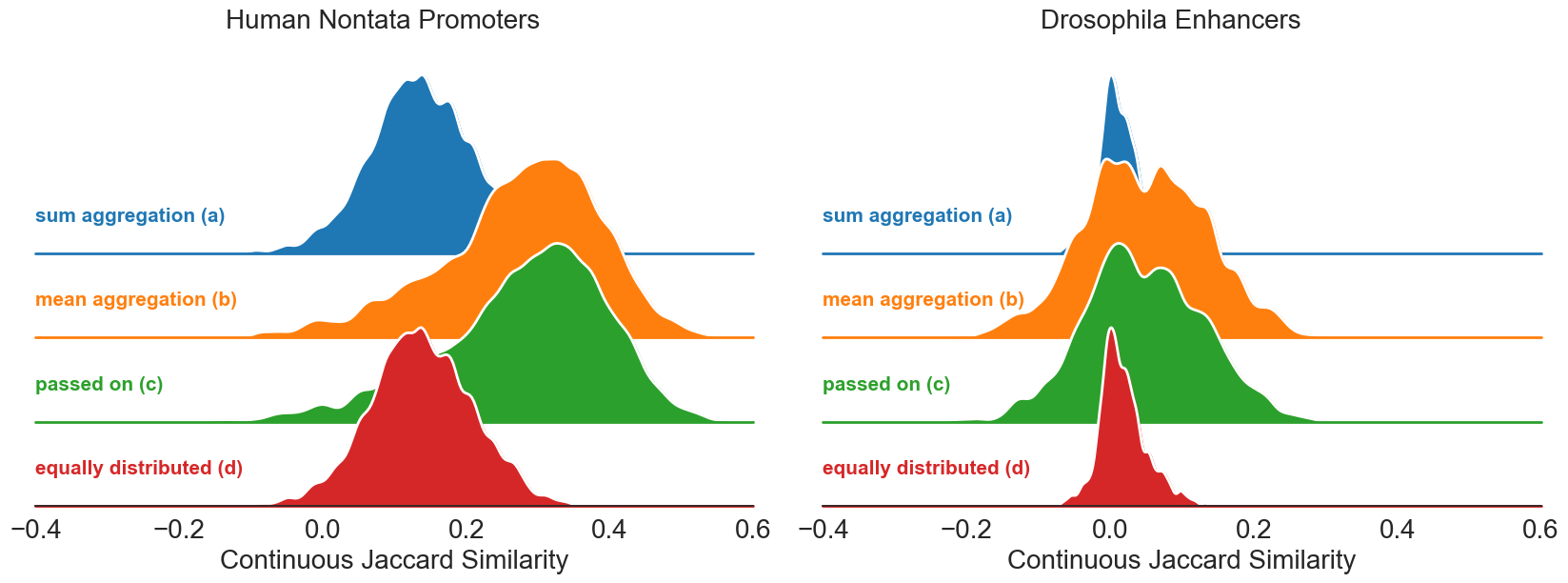
Figure 2: CJ similarity distributions between DNABERT-2 and CNN explanations across tokenization strategies, contrasting human promoters and Drosophila enhancers.
Sparsity and Complexity
Sparsity (Gini index) and complexity (entropy) are evaluated for both models at token and nucleotide granularity. Explanations from AttnLRP and LRP are comparable in interpretability:
- On short sequences (nontata promoters), CNN explanations are sparser (Gini 0.51) than AttnLRP (Gini 0.42).
- On longer sequences (Drosophila), AttnLRP produces sparser maps (Gini 0.64), outperforming CNN (Gini 0.50).
- Entropy is sensitive to granularity; token-level explanations are consistently less complex.
Thus, Transformer-based gLMs do not inherently yield less interpretable attribution, challenging prevailing expectations based on architecture complexity.
Faithfulness
Faithfulness is assessed by perturbing the most/least relevant features (MIF/LIF) and measuring prediction score changes. DNABERT-2/AttnLRP explanations display higher faithfulness (larger prediction shifts for MIF perturbations) relative to CNN/LRP, except in specific cases (random perturbation on 50% of features). LIF perturbations yield negligible prediction changes, confirming reliability of low-relevance assignments.
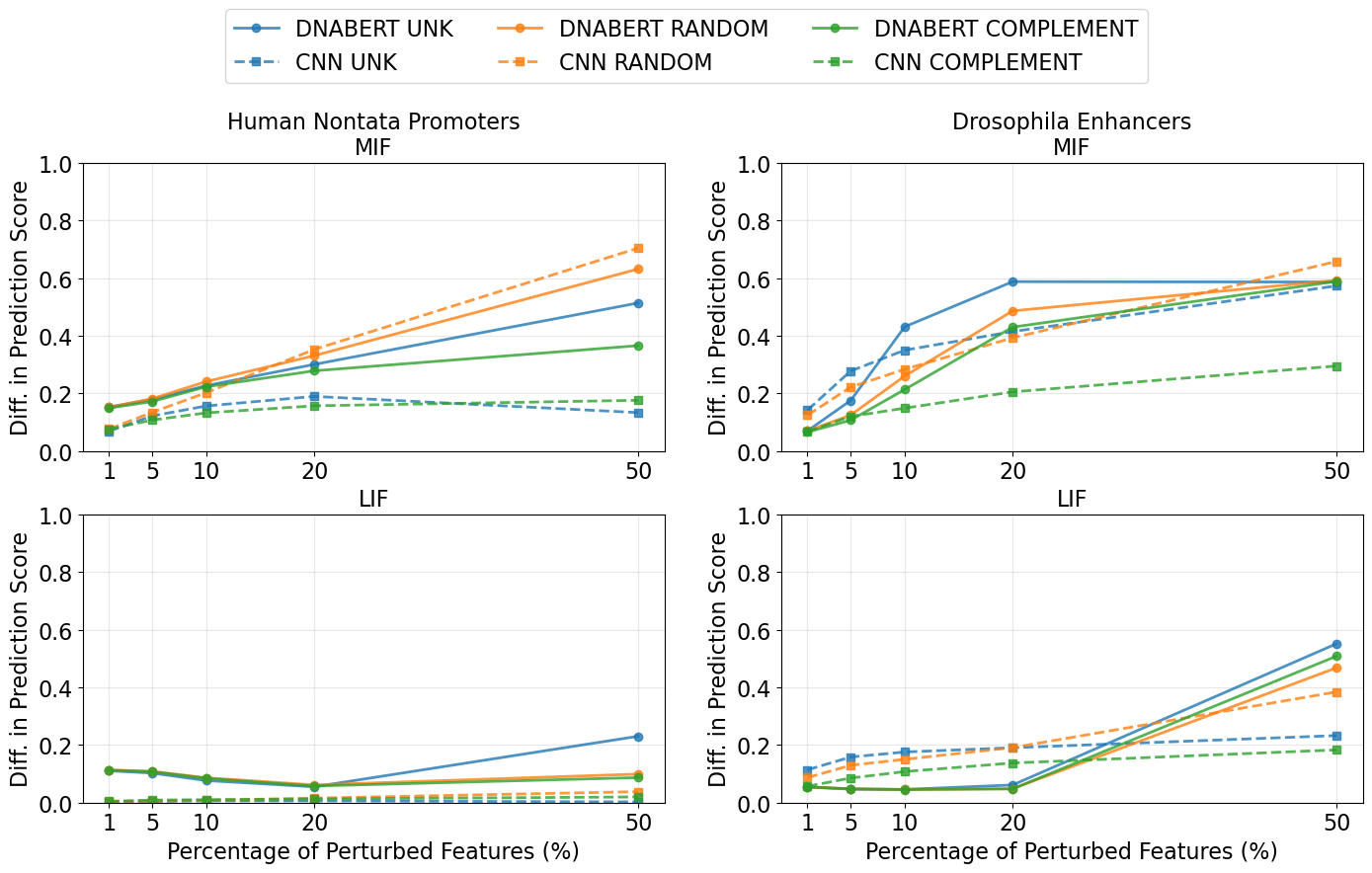
Figure 3: Effect of MIF and LIF perturbations on positive-class prediction scores for both datasets, revealing fidelity of AttnLRP attributions in DNABERT-2.
Biological Localization
TF-MoDISco extracts motif patterns from attribution maps, with database matching (JASPAR via TOMTOM) confirming biological plausibility:
- For nontata promoters, DNABERT-2 explanations consistently highlight GC boxes (motif MA0528.1), aligning with objective class definition (higher GC content in positives).
- In Drosophila enhancers, both models converge to motif MA1841.1 (enhancer repression) in high-CJ samples, validating model reliance on relevant biological signals.
Explanations frequently correspond to established motifs but may contain context patterns, suggesting broader potential for hypothesis generation.
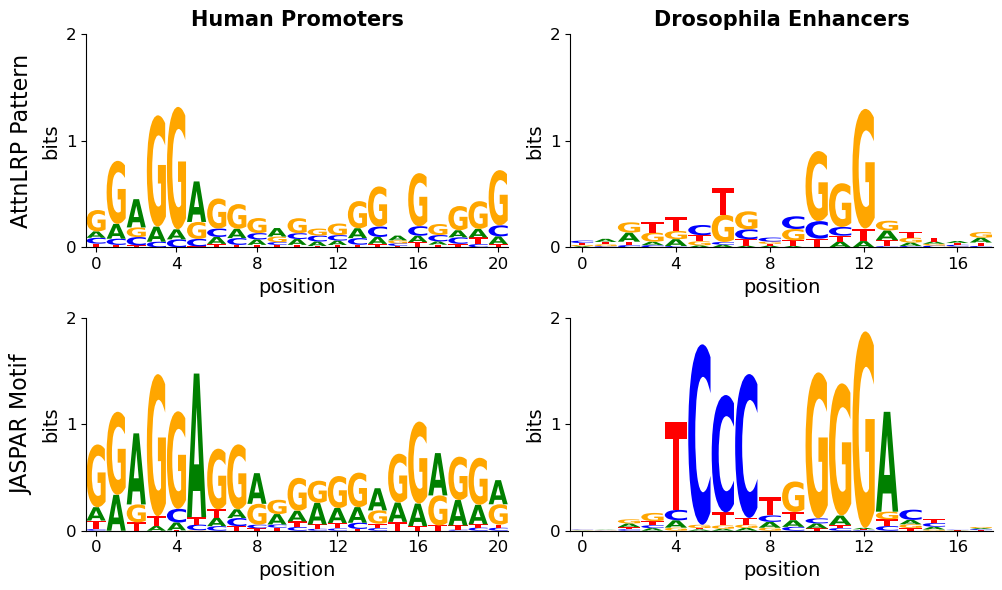
Figure 4: TF-MoDISco motif patterns from AttnLRP explanations matched to JASPAR targets for nontata promoters and drosophila enhancers, demonstrating overlap and information content.
Implications and Future Directions
This work demonstrates that Transformer-based genome LLMs, when explained by properly adapted relevance propagation methods, yield explanations as reliable and biologically interpretable as those from CNNs, refuting the assumption that architectural complexity precludes actionable post-hoc attribution. The comparability of explanation quality across modeling paradigms supports deeper adoption of gLMs for hypothesis-driven genomics research.
Practically, the findings endorse AttnLRP (and its modifications for DNABERT-2) as a robust tool for interpretable genomics AI, expanding the suite of methods available for regulatory region discovery, disease mechanism elucidation, and synthetic biology design. Theoretically, the aggregation strategies introduced enable meaningful comparison across model architectures and granularities, exposing limitations of strict relevance conservation.
Future directions include:
- Extension to additional gLMs (e.g., Nucleotide Transformer, GENA-LM [fishman2025gena]),
- Application to broader classes of genomic tasks (e.g., variant effect prediction, multi-species modeling),
- Exploration of complementary XAI methods beyond AttnLRP,
- Assessment of explanation variation by dataset characteristics (sequence length, species, annotation quality).
Conclusion
The adaptation of AttnLRP for DNABERT-2 demonstrates that post-hoc explanations for Transformer-based genome LLMs are quantitatively and qualitatively reliable, rivaling those produced for CNNs. Attribution patterns correspond well with established biological motifs, reinforcing gLMs as interpretable and hypothesis-generating tools in genomics. The methodological innovation in aggregation/disaggregation, faithfulness evaluation, and database localization provides a template for rigorous XAI benchmarking across model types.

