- The paper introduces StyleID, detailing a human-perception aligned framework using StyleBench-H and StyleBench-S for robust face identity recognition under diverse stylizations.
- The study employs a CLIP-based model with supervised contrastive and angular margin losses, achieving superior metrics such as a 0.74 TPR in challenging cross-method evaluations compared to baselines.
- The work demonstrates practical integration in generative stylization pipelines while highlighting areas for improvement including demographic diversity and synthetic realism.
StyleID: A Perception-Aligned Metric and Dataset for Stylization-Robust Face Identity Recognition
Motivation and Problem Statement
Face stylization, encompassing transformations into cartoons, paintings, and other visual idioms, is increasingly ubiquitous in consumer and creative AI applications. However, robust identity preservation under strong stylization remains an unsolved problem. Conventional identity recognition networks, such as ArcFace and AdaFace, are trained and calibrated exclusively on photographic data and fail to reliably assess or preserve identity once a face undergoes substantial artistic modification. Existing identity metrics either over-penalize stylistic texture changes as identity drift or overlook geometric edit-induced identity loss, and are not calibrated to human-perceptual judgments under stylization. The lack of a human-aligned, style-agnostic protocol for evaluating and supervising identity preservation undermines both the development and assessment of expressive stylization systems.
Key Contributions
The StyleID framework systematically addresses this gap through three interlinked contributions:
- StyleBench-H: A perceptual benchmark of human same/different identity judgments, covering a diverse set of styles and controllable stylization strengths using modern diffusion- and flow-matching-based stylization methods.
- StyleBench-S: A large-scale synthetic supervision set generated through human-calibrated psychometric recognition curves, anchoring training data to perceptual identity thresholds as stylization intensifies.
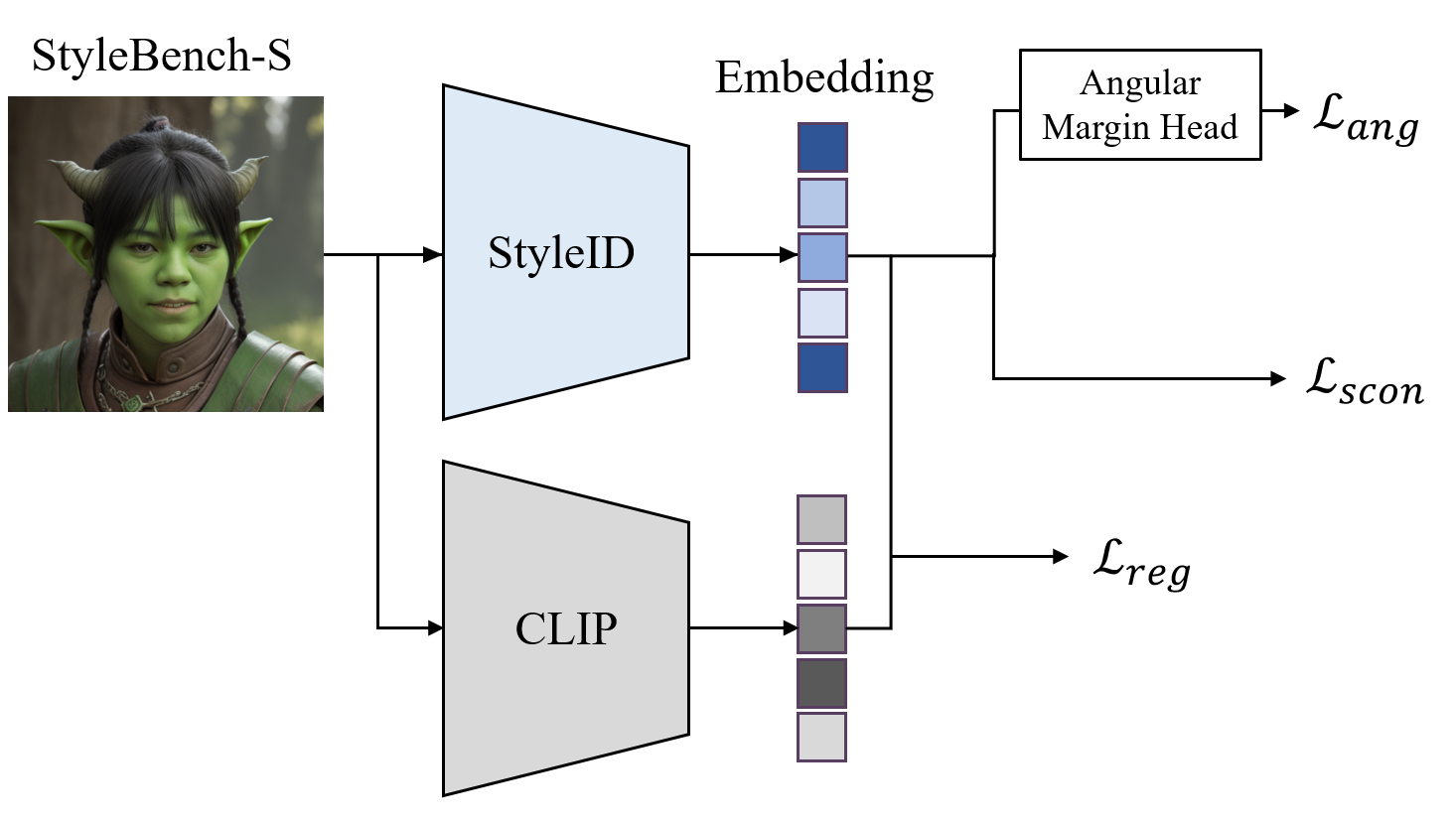
- StyleID Model: A CLIP-based identity encoder, fine-tuned on StyleBench-S with supervised contrastive and angular margin losses, that delivers human-aligned, stylization-robust identity embeddings outperforming both classical and contemporary baselines.
Dataset Design and Analysis
Controllable Stylization and Perceptual Judgments
A key innovation is the explicit disentanglement of stylization strength (s∈[0,1]) from style type. The pipeline utilizes three state-of-the-art stylization methods (IP-Adapter, InstantID, InfiniteYou), each supporting tunable stylization intensity.
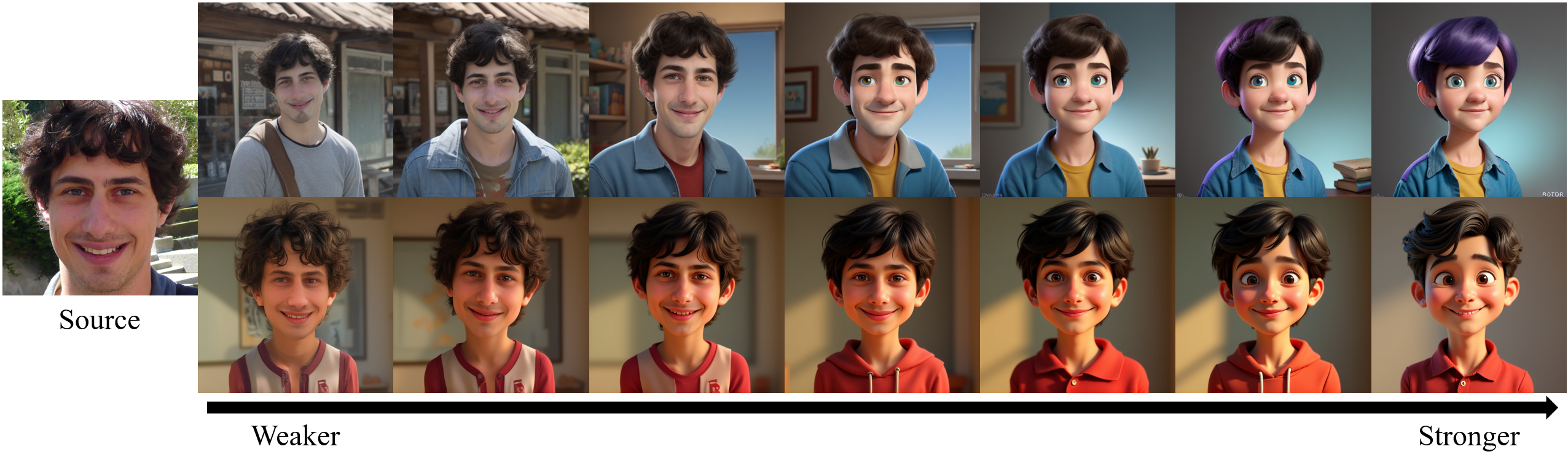
Figure 1: Example data generated by IP-Adapter and InfiniteYou, demonstrating decreasing identity preservation with increasing stylization strength.
Crowdsourced pairwise verification tasks are designed to measure human perception of identity consistency as stylization changes. Rigorous filtering ensures data integrity (e.g., timing and consistency checks; see filtering pipeline below).
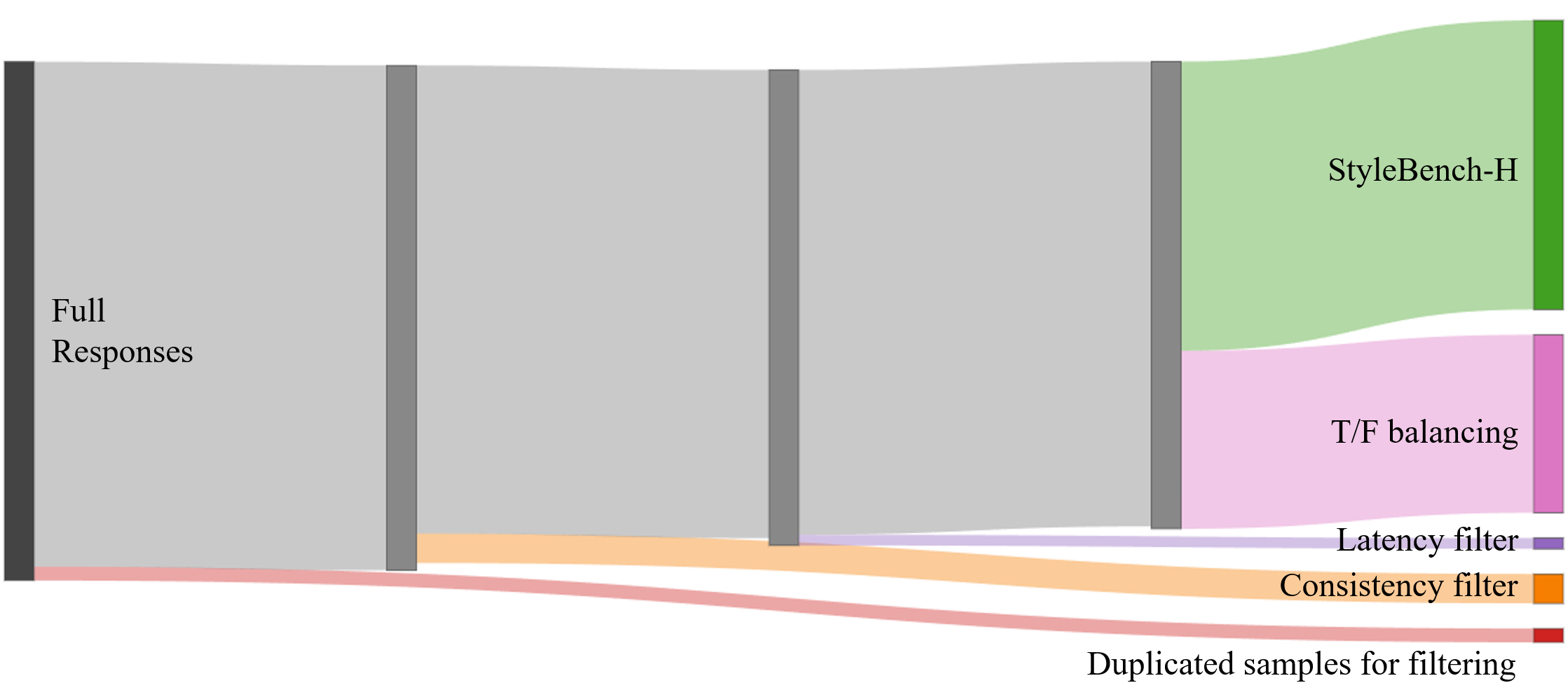
Figure 2: StyleBench-H dataset filtering pipeline.
Demographic balance is considered, but the dataset remains skewed toward young, white subjects.
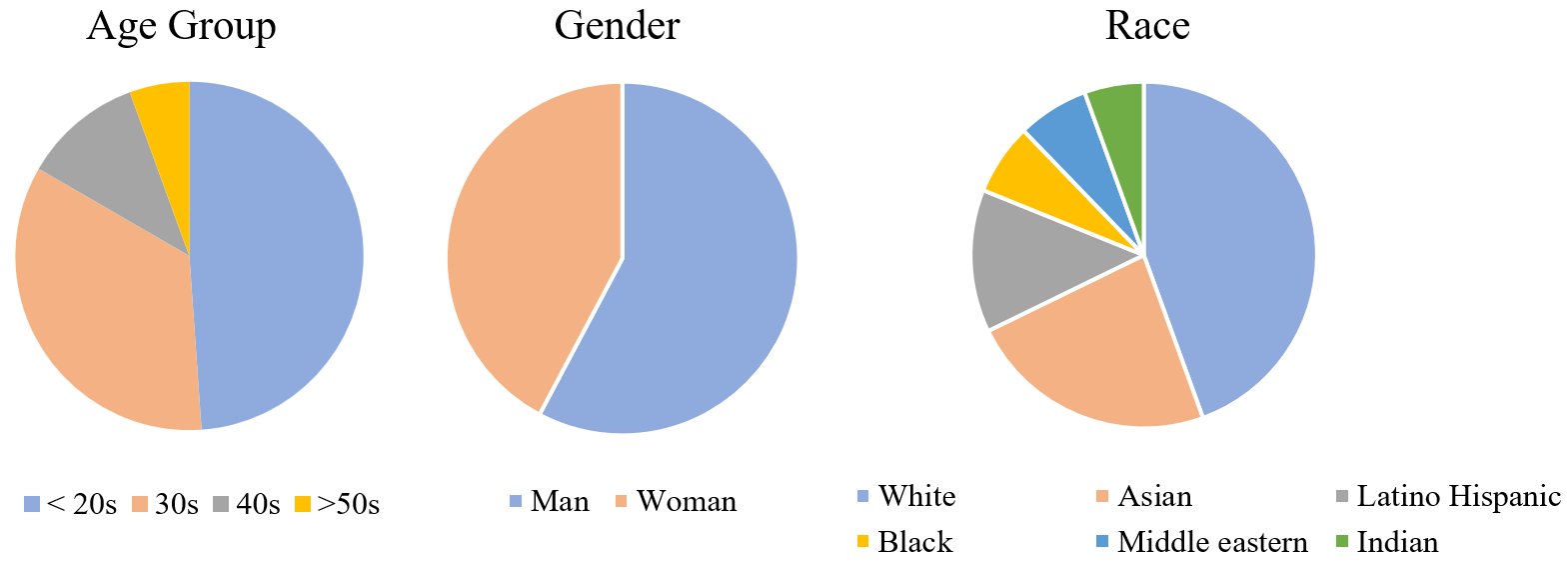
Figure 3: Demographics of StyleBench-H source images.
Psychometric Calibration and Synthetic Supervision
Through two-alternative forced-choice (2AFC) protocols, the authors obtain psychometric curves of human recognition accuracy across style, method, and stylization strengths. These curves reveal method- and style-specific thresholds for perceptible identity retention as stylization intensity increases.
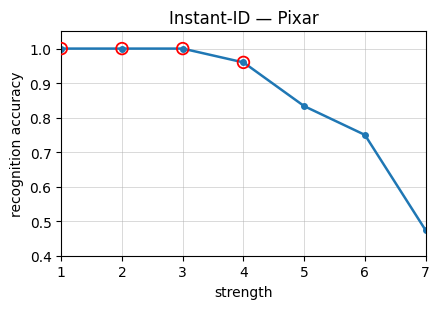
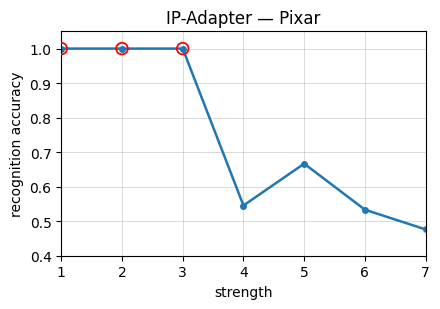
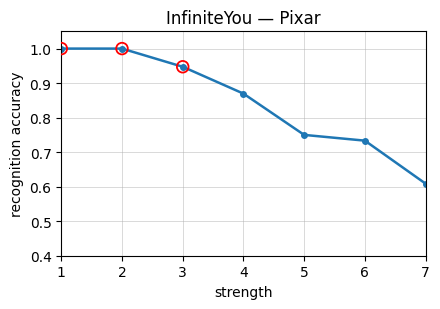
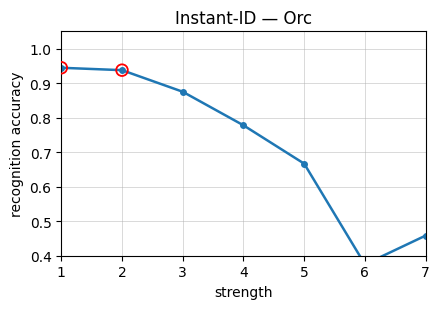
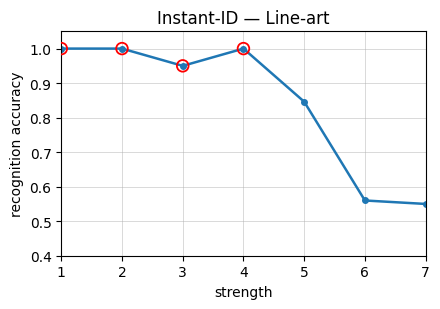
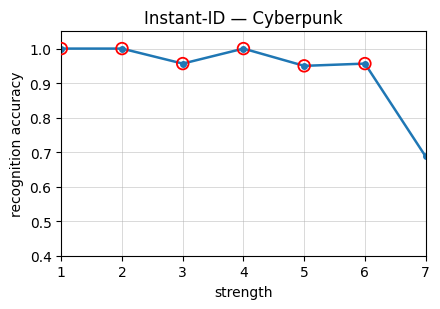
Figure 4: Recognition accuracy as a function of stylization strength on StyleBench-S, showing severe drops at high stylization strengths and prominent variability across methods and styles.
The construction of StyleBench-S leverages these curves by selecting stylized pairs at strengths where the human recognition probability is above 90%. Lower thresholds allow excessive semantic cue reliance, which are insufficient for identity preservation.

Figure 5: Comparison of 90% and 70% selection thresholds, showing that lower thresholds fail to maintain identity.
Model Architecture and Perceptual Alignment
CLIP Backbone and Training
StyleID builds upon the CLIP-L ViT vision encoder, leveraging large-scale image-text pretraining for increased tolerance to distributional shifts. Training employs LoRA adapters for parameter-efficient adaptation. The loss function jointly optimizes:
Comparative Evaluation
The StyleID model demonstrates superior correlation with human identity judgments under stylization, significantly outperforming ArcFace, AdaFace, CLIP, SigLIP2, and even purpose-trained competitors such as StylizedFace.
- On StyleBench-H, StyleID achieves TPR > 0.9 in “Cross-ID” and “Cross-Style” settings, and 0.74 in the challenging “Cross-Method” OOD split, exceeding all baselines. The “Cross-Method” setting, which tests on entirely unseen stylization methods and prompts, shows a remarkable robustness gap (StyleID: 0.74; best baseline: 0.50).
- On the SKSF-A dataset with hand-drawn sketches, StyleID maintains high verification performance (TPR: 0.89), with large margins over all other candidates.
- AUROC and accuracy metrics across a broad threshold range confirm StyleID’s separability under all tested conditions.
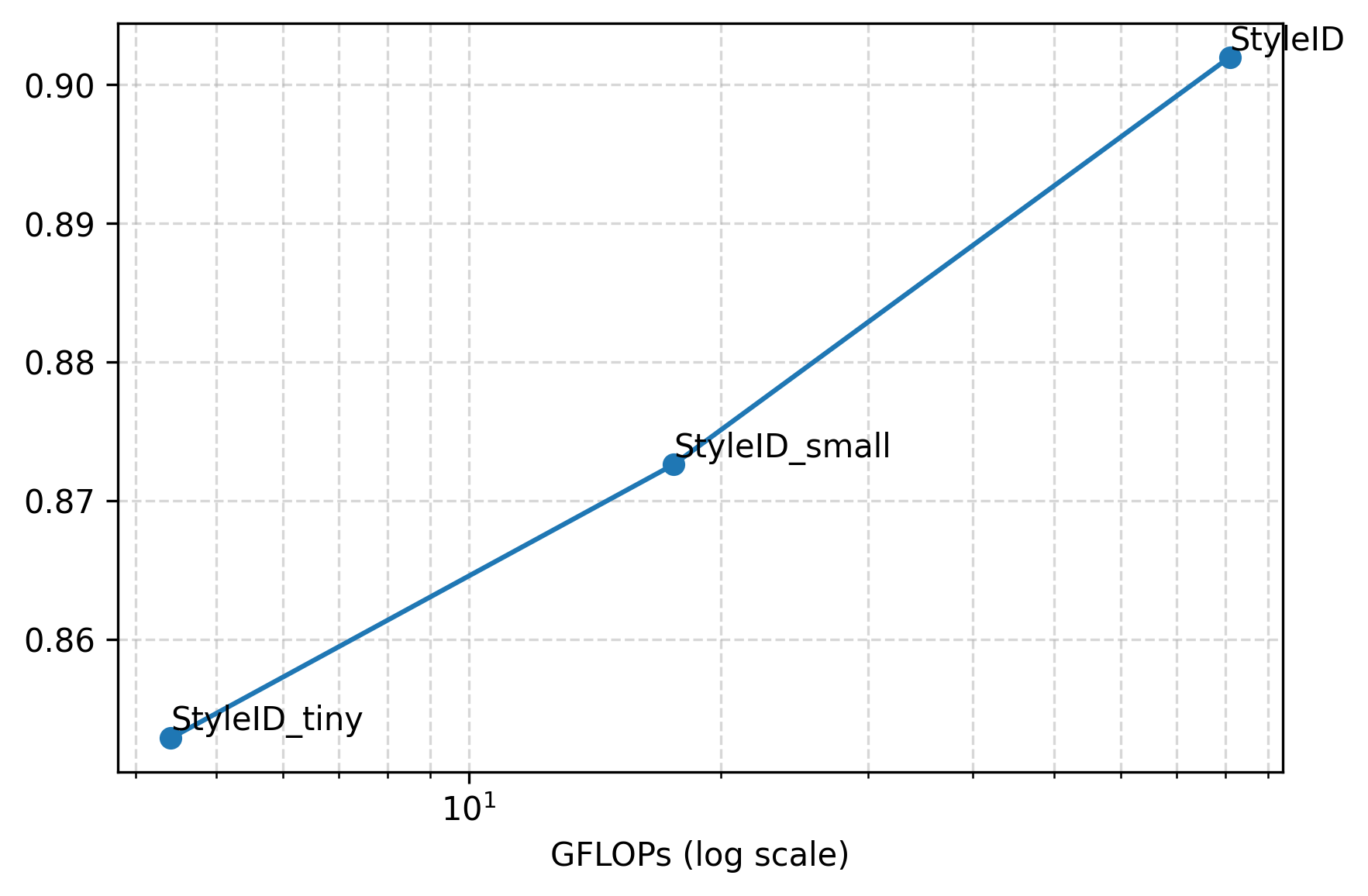
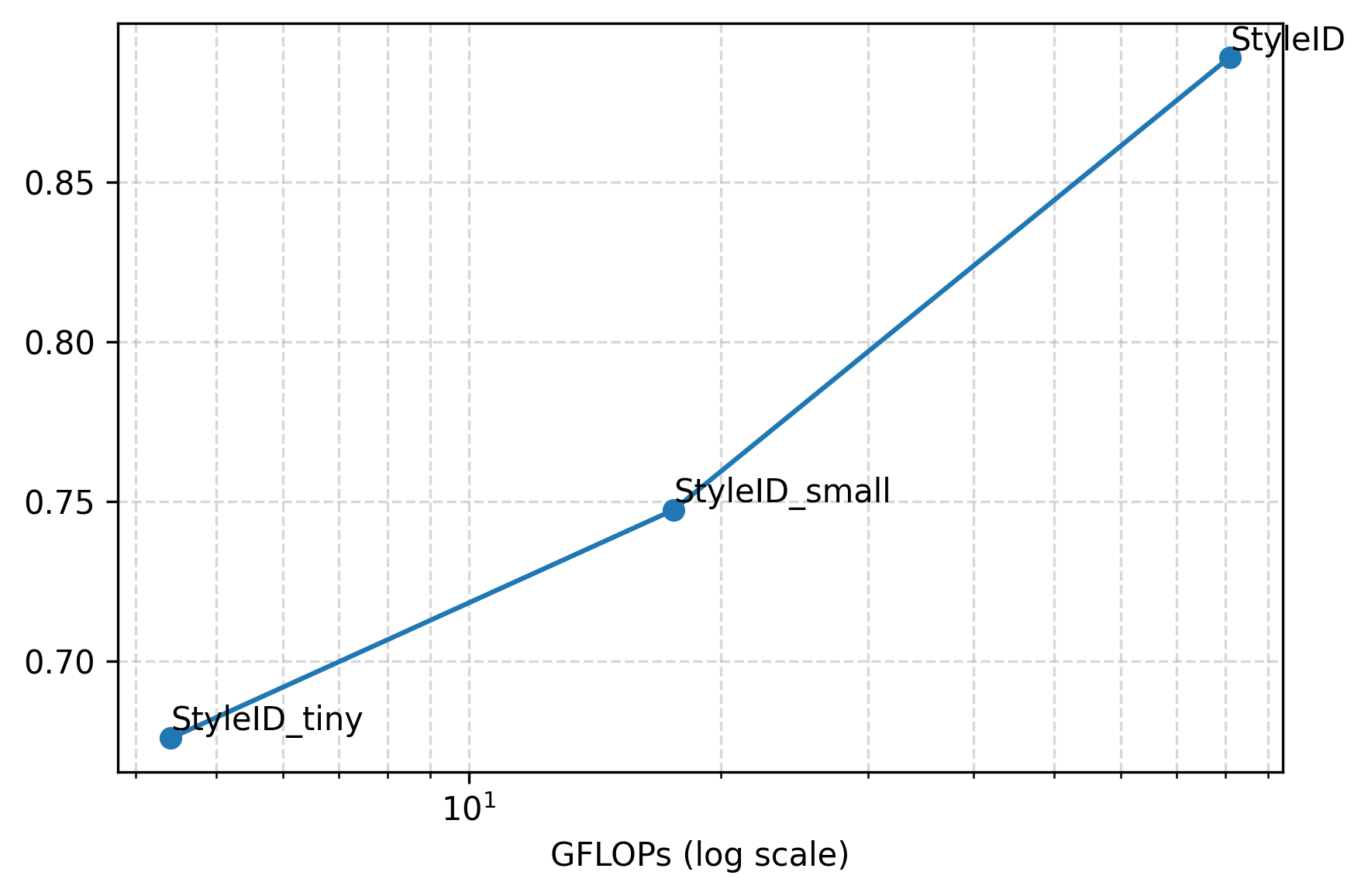
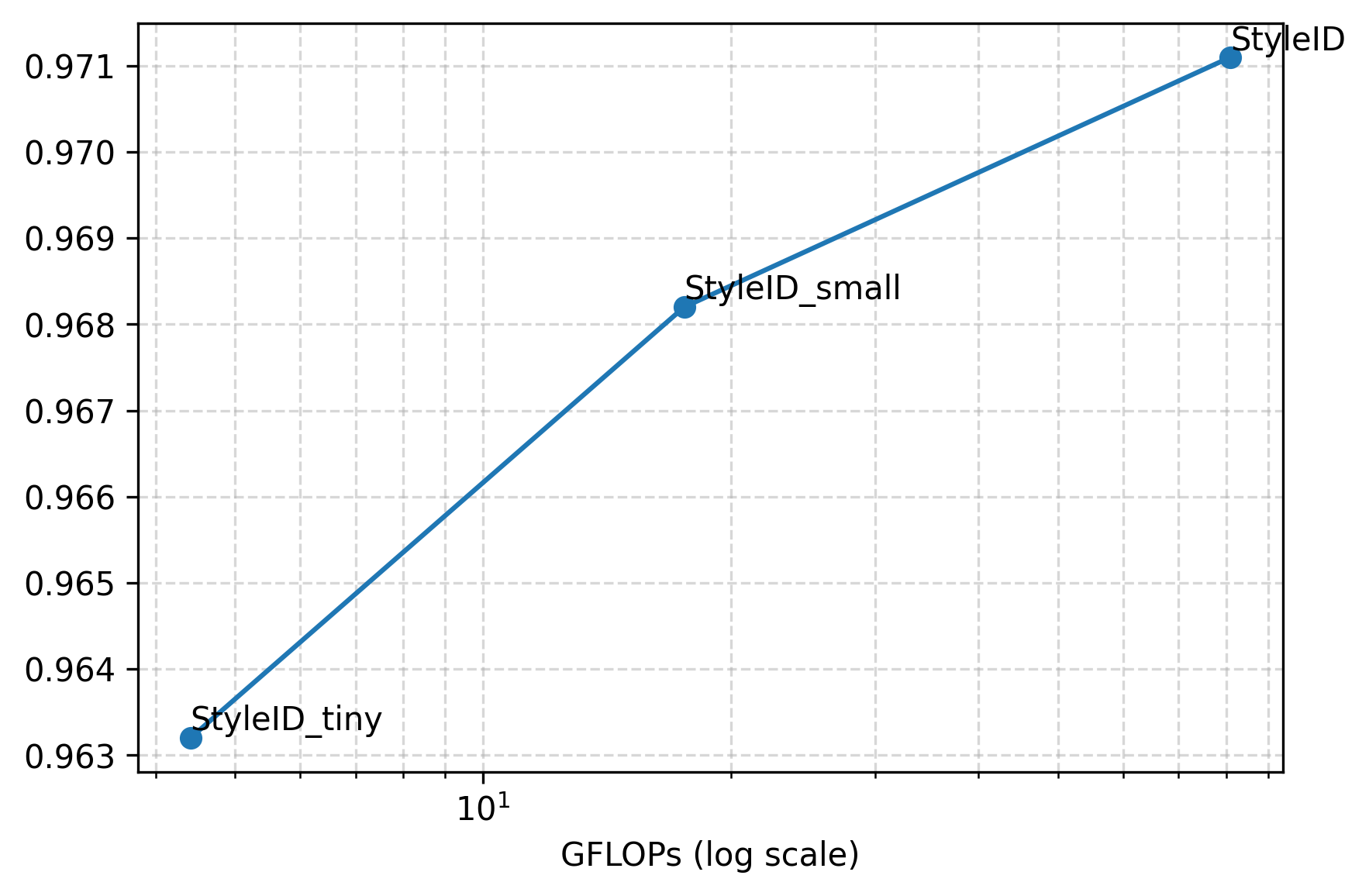
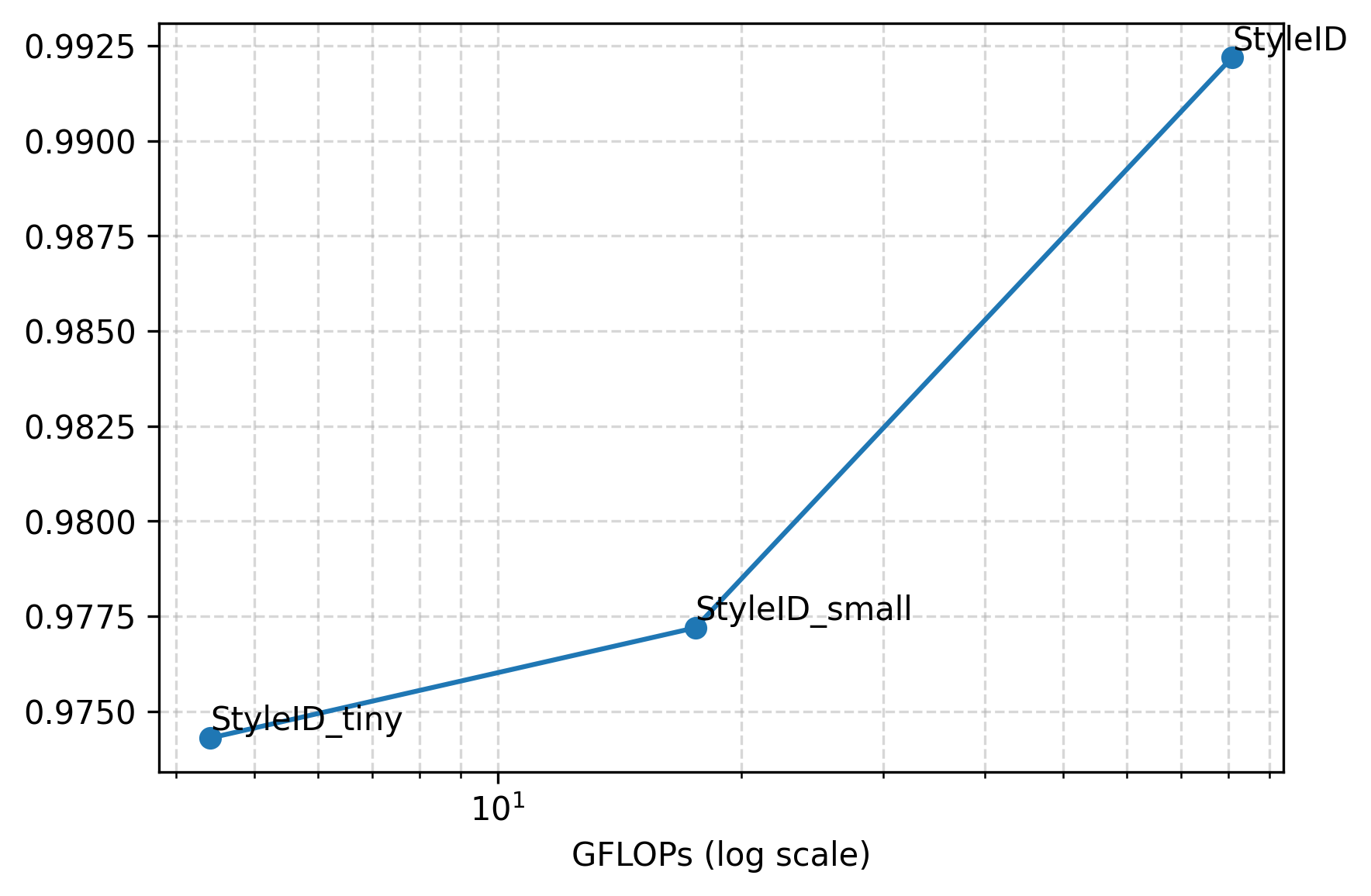
Figure 7: TPR and AUROC versus GFLOPs for StyleID variants; performance drops with smaller backbones but surpasses baselines even at high efficiency.
Retrieval and Pose Robustness
Embedding quality is further validated with cross-domain retrieval: StyleID surpasses ArcFace/AdaFace by 10–20% on SKSF-A, both for searching sketches from real images and vice versa.

Figure 8: Top-4 nearest neighbor retrievals from SKSF-A, showing cross-domain identity consistency.
Pose robustness experiments reveal that StyleID preserves identity similarity under viewpoint changes for both real and stylized images, unlike ArcFace, whose similarity collapses under stylization.
Applications and Broader Implications
Integration into Generative Stylization Pipelines
As a practical demonstration, replacing ArcFace with StyleID within JoJoGAN produces stylized portraits that better preserve both identity and source color, avoiding prominent artifacts.
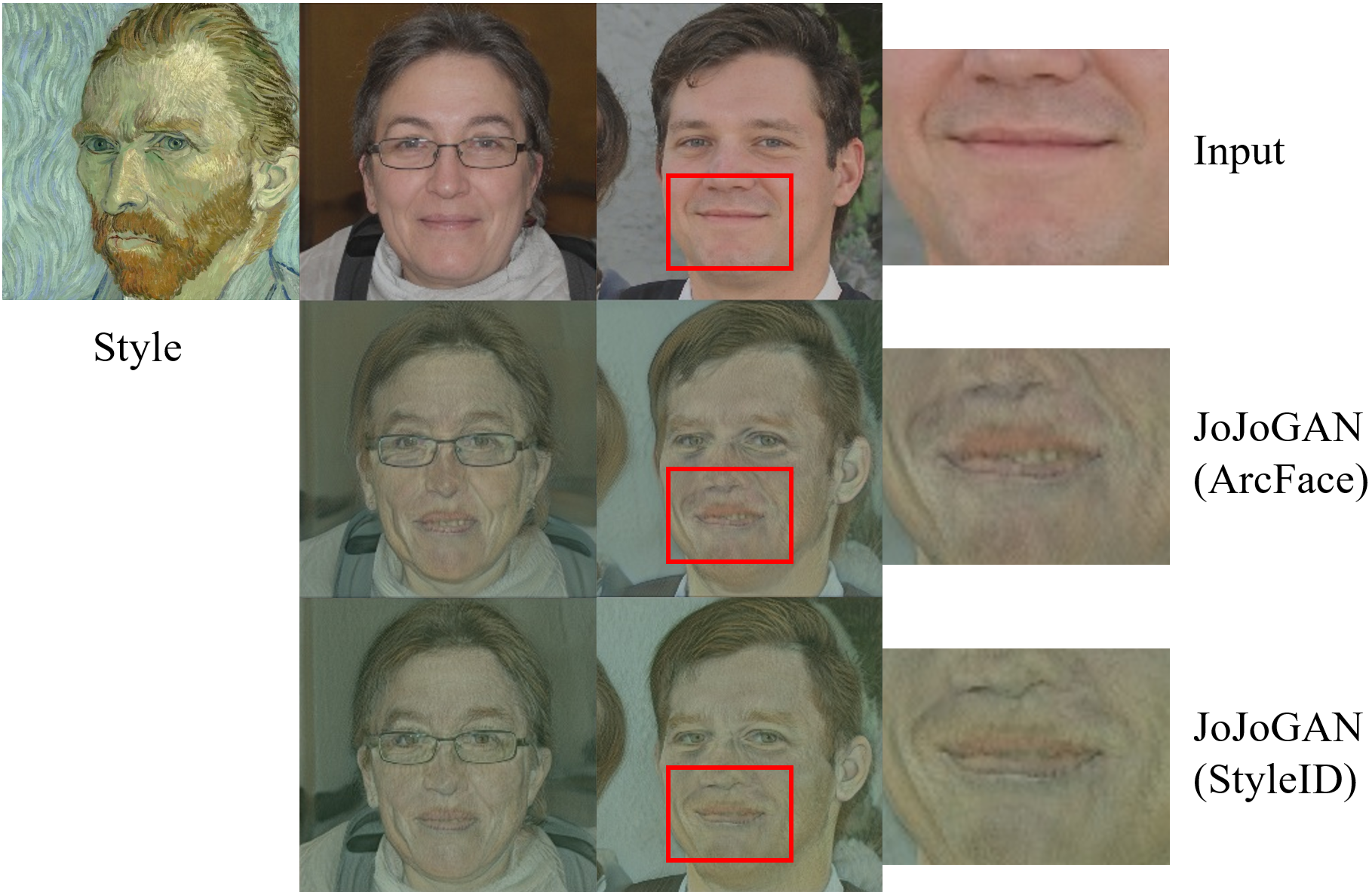
Figure 9: JoJoGAN outputs with ArcFace (top) versus StyleID (bottom). StyleID maintains color accuracy and artifact-free structure under strong stylization.
Automated (GPT-5.4-based) and human user studies consistently prefer JoJoGAN+StyleID for identity, expression, style, and overall quality.
Generalization and Efficiency
StyleID maintains reasonable performance on LFW, verifying that perceptual adaptation for stylization does not catastrophically degrade natural-image verifiability.
Lightweight StyleID variants using CLIP-B backbones offer substantial reductions in memory and FLOPs while retaining superiority over dedicated face recognition baselines for stylized faces.
(Figure 7 revisited)
Figure 7 (again): Efficiency-accuracy frontier, validating deployment flexibility.
Limitations and Future Directions
- Demographic Coverage: Both StyleBench benchmarks are demographically biased, potentially limiting generalization and fairness. Expanding to include more diverse populations is essential.
- Synthetic Realism: StyleBench-S relies on calibrated synthetic data, which may not fully capture the complexity of hand-drawn or real artistic stylization.
- Handling of Extreme Conditions: Current benchmarks and modeling focus on appearance transformations rather than extreme pose or occlusion, which should be integrated for comprehensive robustness.
- Hybrid Supervision: Combining perception-calibrated synthetic data with more real-world user-provided stylizations could further enhance real-world alignment.
Conclusion
The StyleID framework establishes a new paradigm for facial identity recognition under stylization by explicitly anchoring both evaluation and supervision to human perception. Through large-scale, psychometrically-grounded dataset construction and CLIP-based model adaptation, StyleID delivers quantifiable robustness and alignment to human judgments across a wide variety of stylization pipelines, methods, and degrees. The empirical results indicate that the field must shift from photo-trained identity metrics toward perception-calibrated, style-agnostic encoders for trustworthy deployment in creative and generative applications. Continued scaling of annotation, broadened domain coverage, and further analysis of social and demographic factors will be critical in advancing this line of research.