- The paper introduces GS-Quant, a novel hierarchical quantization strategy that fuses relational and textual embeddings for improved knowledge graph completion.
- The proposed framework leverages granular semantic enhancement and generative structural reconstruction to align discrete code tokens with LLM token sequences.
- Empirical evaluations demonstrate state-of-the-art gains, including up to +2.4% improvement in Hits@1, validating the method’s effectiveness across benchmark datasets.
GS-Quant: Hierarchical Quantization for Enhanced Knowledge Graph Completion via LLMs
Introduction and Motivation
Knowledge Graph Completion (KGC), the task of inferring missing links in knowledge graphs (KGs), is a critical challenge for scalable symbolic reasoning, with direct applications in recommendation, QA, and hallucination mitigation in LLMs. While LLMs have recently boosted the generative reasoning capability for KGC, existing approaches suffer from a fundamental modality gap: continuous KG embeddings are holistic and dense, but LLMs operate over discrete token sequences.
Approaches to align these modalities fall into three main paradigms:
- Text-based methods flatten graph structures into unstructured text, causing both information loss and high computational cost.
- Embedding-based methods inject continuous graph representations directly into LLMs, which often yields weak alignment due to modality mismatch.
- Quantization-based methods utilize dictionary-based discrete code tokens for entities, striving for a linguistic isomorphism with LLM token sequences.
However, early quantization approaches typically treat the problem as mere numerical compression, neglecting the coarse-to-fine semantic stratification intrinsic to both language and human reasoning. The consequence is semantically entangled codes, poorly suited for the hierarchical autoregressive nature of LLMs.
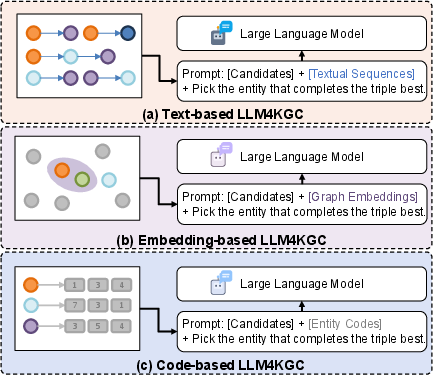
Figure 1: Comparison of KGC-LLM integration paradigms: (a) text-based (flattened sequence), (b) embedding-based (direct injection), and (c) code-based (GS-Quant's hierarchical tokenization).
GS-Quant Framework
GS-Quant introduces a semantically stratified, generative quantization pipeline for KGC-LLM integration. The entity representation pipeline consists of several key components:
- Entity Encoding: Entities are encoded by fusing relational embeddings (e.g., RotatE) with PLM-based textual representations using a weighted sum, ensuring both structural and lexical knowledge are captured.
- Residual Quantization (RQ): Using an RQ-VAE backbone, entities are discretized into a tuple of code indices via multi-level codebooks, each level refining the residual representation from the previous.
- Granular Semantic Enhancement (GSE): Unlike numerically optimized codebooks, GSE imposes explicit coarse-to-fine semantic constraints by hierarchical clustering of entity semantics. Early codebook layers capture general categories; deeper layers encode fine-grained attributes. This alignment is enforced through losses promoting both within-layer alignment to hierarchical centroids and separability across sibling codes.
- Generative Structural Reconstruction (GSR): To further encourage context and cross-level interactions among codes, a causal Transformer decoder is trained to autoregressively reconstruct both the entity embedding and its hierarchical ancestors from the code tuple, thus mimicking hierarchical linguistic generation.
- LLM Vocabulary Augmentation: The learned codes are integrated as new tokens into the LLM vocabulary. Only the new code token embeddings and LoRA adapters are updated, preserving base LLM knowledge while enabling efficient integration.
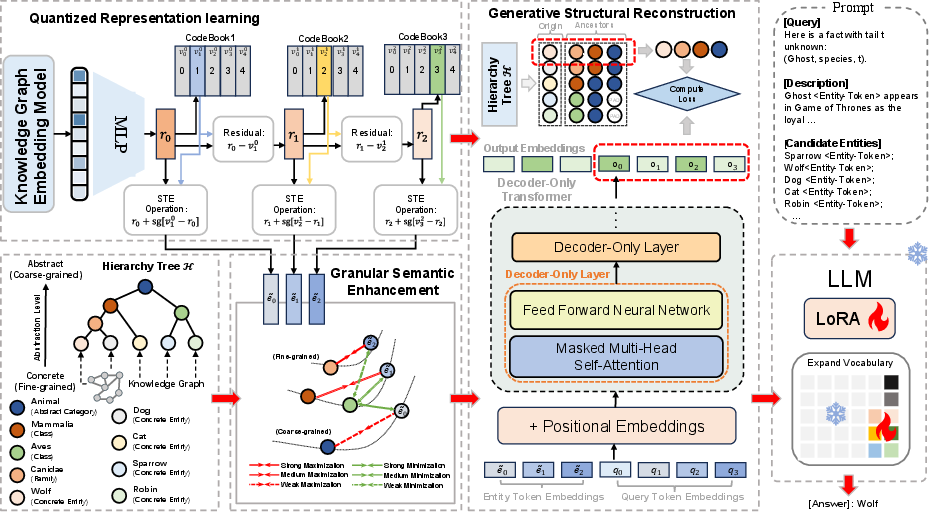
Figure 2: The GS-Quant pipeline: hierarchical clustering, residual quantization, semantic alignment, and code-based LLM fine-tuning.
Empirical Evaluation and Ablation
GS-Quant is benchmarked on WN18RR and FB15k-237, two standard KGC datasets. Comparisons encompass embedding-based (TransE, RotatE, CompGCN), text-based (KG-BERT, CoLE), and SOTA LLM-based baselines (KICGPT, DIFT, SSQR).
GS-Quant achieves a +1.7% MRR and +2.4% Hits@1 gain over the previously strongest LLM-based method on WN18RR, and +1.6% MRR/+2.2% Hits@1 on FB15k-237, robustly outperforming both DIFT (continuous embeddings) and SSQR (flat quantization). Gains are most pronounced for Hits@1, indicating superior top-rank prediction.
Ablation results confirm:
- Both GSE components (coarse-to-fine and separability losses) are essential; removal degrades MRR/Hits@1 by 0.5–0.9%.
- GSR further boosts multi-level structural consistency.
- The code-based input tokens alone account for the largest accuracy increase; without quantized tokens, the LLM reverts to vanilla text and loses most learned structure.
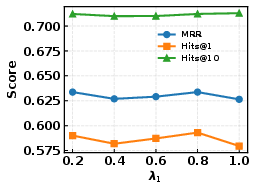
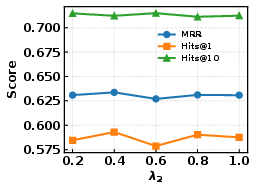
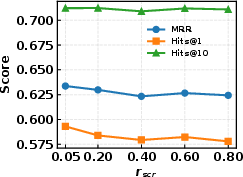
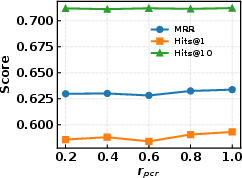
Figure 3: Sensitivity analysis for GSE and GSR regularization strengths (λ1, λ2, λs, λh) on WN18RR.
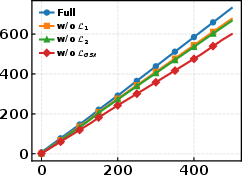
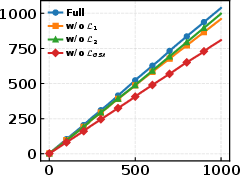
Figure 4: Cumulative training time for full GS-Quant and ablations; extra regularization yields moderate overhead relative to gains.
Semantic and Structural Interpretability
GS-Quant encourages an explicit hierarchy in code utilization across layers, as confirmed by t-SNE and codebook visualizations. Coarse-grained code layers are used more uniformly and globally, while deeper layers encode discriminative, fine-grained semantics, closely mirroring human category hierarchy.
Codebook entropy maximization is directly correlated with performance: higher entropy (more uniform code utilization) tracks with higher MRR and Hits@K.
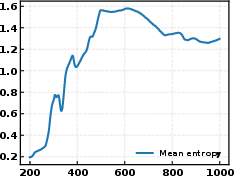
Figure 5: Evolution of codebook entropy (Y) during training. High and stable entropy indicates effective codebook usage.
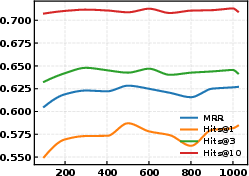
Figure 6: Convergence curves for MRR and Hits@K metrics across GS-Quant codebook training epochs.
GS-Quant also achieves more seamless integration into the LLM embedding space compared to DIFT, with KG token embeddings forming a contiguous, non-isolated region in the overall token space.
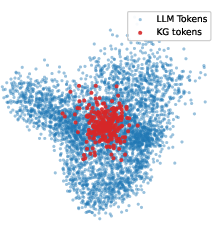
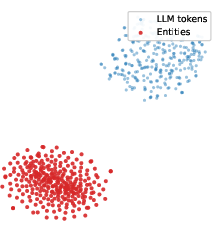
Figure 7: t-SNE visualization of code token embeddings (GS-Quant) versus entity embeddings (DIFT); GS-Quant shows compact integration with base tokens.
Robustness and Practical Implications
Experiments across a diverse set of LLM architectures (Llama, Mistral, Qwen2.5, Vicuna, DeepSeek-R1) demonstrate that GS-Quant is not tied to a specific backbone, achieving stable relative gains in all tested settings. The pipeline is also robust to different initial KG embedding models (ComplEx, DistMult, pRotatE, TransE).
From a practical standpoint, the approach enables scalable LLM-based KGC with minimal token inflation and competitive wall-clock efficiency, thanks to code-level discrete integration and LoRA-based fine-tuning.
Qualitative case analysis shows that GS-Quant's hierarchical codes enable more precise entity retrieval regarding geographic containment, administrative granularity, degree types, and semantic consistency, systematically correcting baseline errors.
Theoretical Implications and Future Directions
GS-Quant provides a principled treatment of semantic hierarchy in quantization, aligning the discrete code sequence not solely to compressive fidelity, but to the coarse-to-fine, autoregressive process inherent in LLM-based reasoning. This bridges the gap between numerically optimized quantization and the compositional logic required for natural language and symbolic reasoning tasks.
The paradigm suggests promising future research avenues:
- Scaling to even larger or more diverse KG domains with arbitrary hierarchical depth.
- Extending discrete stratified code integration to more complex generative or reasoning-intensive tasks beyond link prediction, such as multi-hop QA or abductive reasoning.
- Investigation of the generalization of learned codebooks to new KG schemas or transfer across domains.
- Joint training with LLM backbones for end-to-end symbolic-semantic fusion, possibly leveraging nonparametric or continual learning settings.
Conclusion
GS-Quant advances the integration of KGs and LLMs for knowledge graph completion by introducing a semantically coherent, hierarchy-aware quantization strategy. By coupling granular semantic enhancement and generative structural reconstruction, it enables LLMs to reason over discrete, linguistically isomorphic code sequences that retain the underlying graph structure. Empirical results establish new standards for LLM-based KGC performance, paving the way for further unification of symbolic and neural reasoning in scalable AI systems.
Reference: "GS-Quant: Granular Semantic and Generative Structural Quantization for Knowledge Graph Completion" (2604.21649)

