- The paper demonstrates that principled data selection, especially importance weighting and Moore-Lewis methods, significantly enhances compliance detection accuracy across domains.
- It models regulatory compliance as a Natural Language Inference task, effectively categorizing entailment, neutral, and contradictory pairs for increased explainability.
- Empirical findings reveal that optimal selection ratios prevent negative transfer, highlighting the need for careful calibration when augmenting source domain data.
Cross-Domain Data Selection and Augmentation for Automated Regulatory Compliance Detection
Introduction
Automatic detection of regulatory compliance within software systems presents considerable challenges due to the heterogeneity and complexity of legal texts. Existing models, while effective within a single regulatory domain, suffer significant performance degradation when transferred across domains, predominantly because of non-trivial shifts in legal terminology, structure, and reasoning styles. The paper "Cross-Domain Data Selection and Augmentation for Automatic Compliance Detection" (2604.21469) addresses this by systematically evaluating data selection strategies for augmenting compliance datasets, aiming to mitigate negative transfer and enhance cross-domain generalization. The study frames compliance detection as a Natural Language Inference (NLI) task and benchmarks several principled data selection methods to control the quality of cross-domain augmentation.
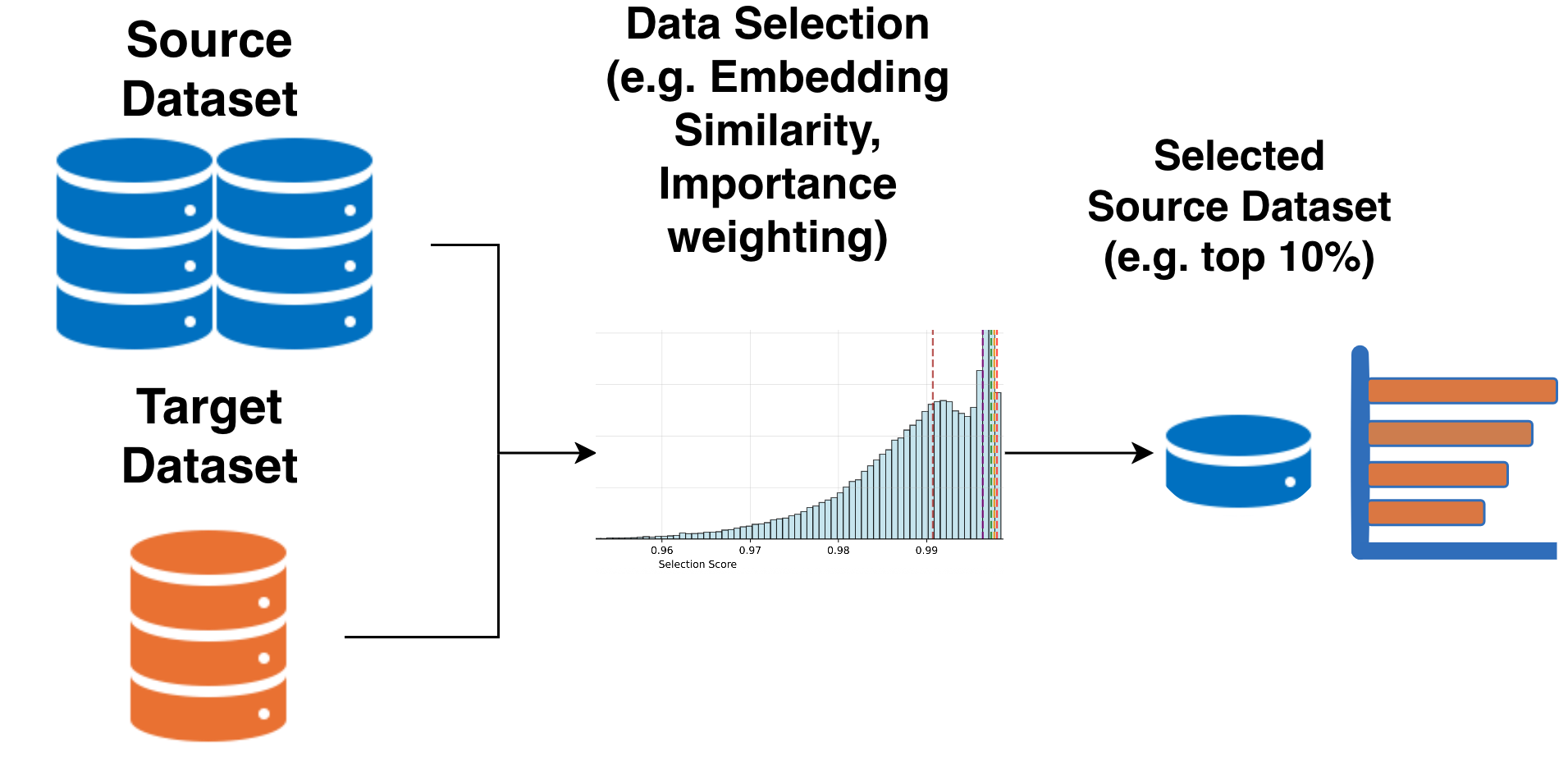
Figure 1: Pipeline illustrating the evaluation of multiple data selection methods to subset a large source domain (e.g., GDPR) for effective transfer to a smaller target domain (e.g., HIPAA) and prevent negative transfer.
Compliance as Natural Language Inference
The compliance detection task is modeled as NLI, where regulatory requirements serve as premises and corresponding statements from Data Processing Agreements (DPAs) or policy documents serve as hypotheses. The classification is formulated into entailment (compliance), neutral, or contradictory (non-compliance) pairs. This approach leverages the verbal structure of legal requirements, enabling the model to generalize over explicit textual entailments and facilitating data-driven explainability.
Data Selection Strategies
The paper explores four data selection strategies for cross-domain augmentation:
- Random Sampling: Baseline method with uniform sampling from source domain.
- Moore-Lewis Cross-Entropy Difference: Ranks source data based on differential cross-entropy scores from LLMs trained separately on source and target domains, prioritizing samples statistically similar to the target.
- Importance Weighting (Density Ratio): Trains a classifier to estimate density ratio between target and source instances, then uses these estimates to select source samples with high target-likelihood.
- Embedding-Based Retrieval: Utilizes pretrained encoder representations (e.g., RoBERTa-large), selecting source examples with high cosine similarity to target-domain instances.
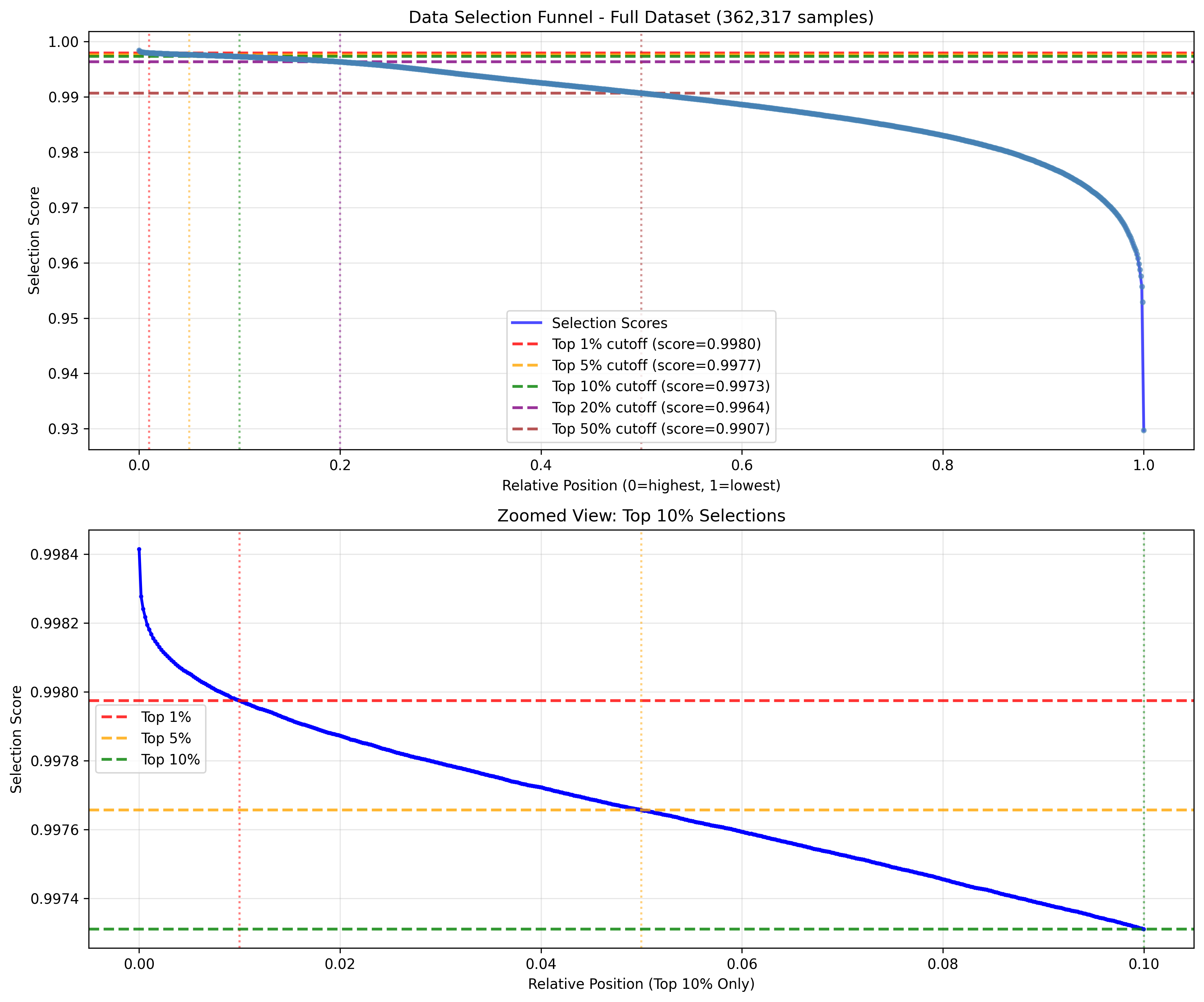
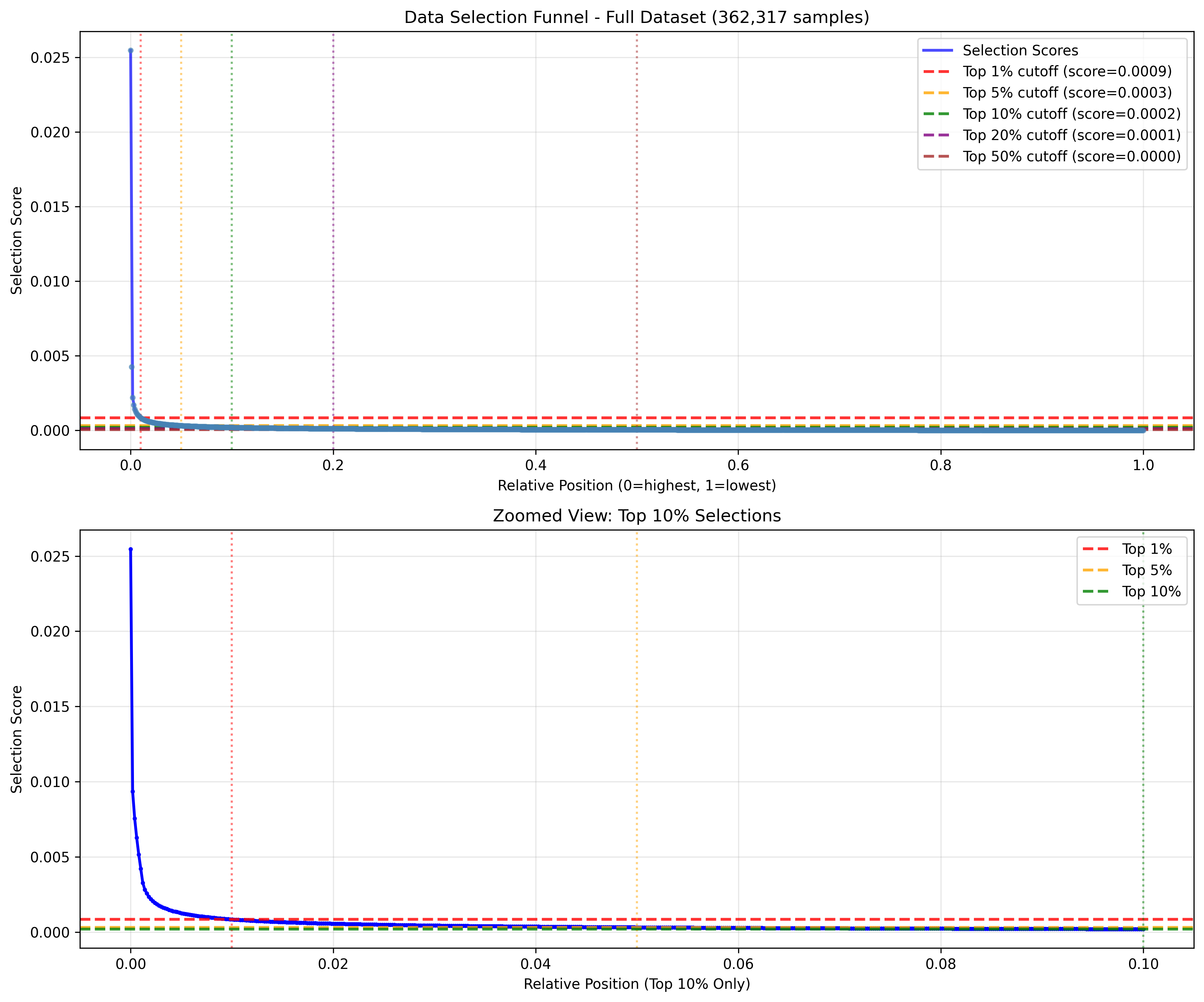
Figure 2: Visualization of data selection scores and position rankings for the embedding similarity method.
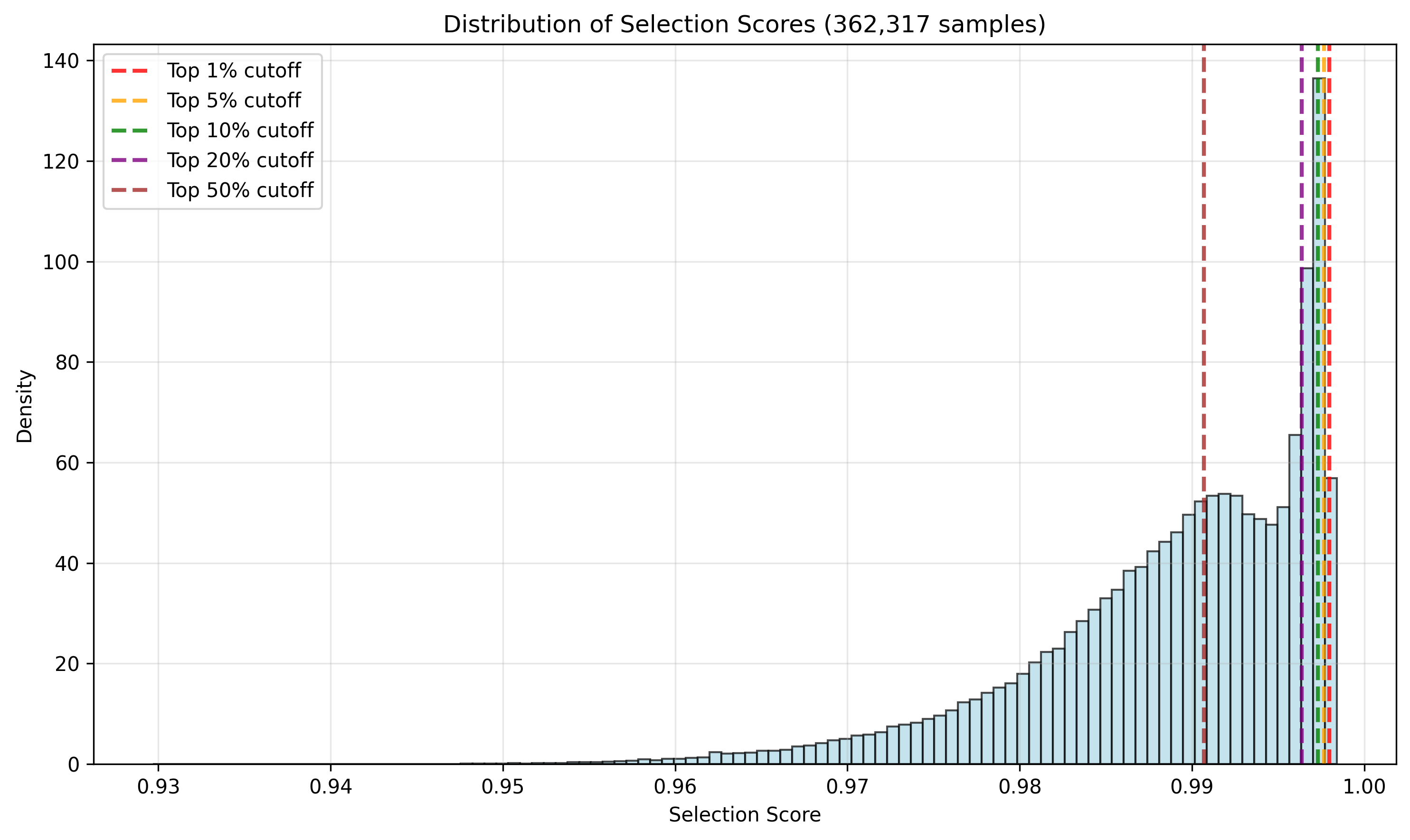
Figure 3: Distribution of embedding similarities between source and target datasets using RoBERTa-large, illustrating the discriminative signal for neighbor selection.
Additionally, a random sampling baseline and full (unfiltered) augmentation serve as controls to measure the effects of indiscriminate data addition.
Experimental Design
Datasets
The experiments are anchored on a large GDPR-DPA dataset as the source domain and a much smaller, annotated HIPAA dataset as the target. The regulatory shift between GDPR (focused on data protection within the EU) and HIPAA (healthcare data privacy in the US) ensures a strong domain mismatch, making this a stringent test for cross-domain transfer approaches.
Evaluation Protocol
Two primary scenarios are considered:
- In-domain: Models are trained and tested within the same domain, establishing an upper performance bound.
- Cross-domain: Models are trained on GDPR-DPA (with selectable augmentation) and evaluated on HIPAA, measuring transfer effectiveness under various selection ratios (from 1% up to 90%).
Encoder-based models (BERT-large, RoBERTa-large, Legal-BERT) are trained via multi-class NLI fine-tuning; decoder-based LLMs (GPT-2-XL, Llama-3) are evaluated under zero- and one-shot prompting to quantify the gap with discriminative models in compliance scenarios.
Empirical Findings
In-domain Performance
Fine-tuned encoder models achieve strong F1 scores on in-domain (GDPR-DPA) tests (Legal-BERT: 0.86, BERT: 0.85), but performance degrades sharply on the out-of-domain (HIPAA) test (F1 ≤ 0.56 for all models). Decoder LLMs, even with prompting, are substantially weaker, barely above random-chance on both domains. This underscores the intractability of unsupervised domain transfer without explicit adaptation.
Cross-Domain Data Selection Results
Systematic augmentation using data selection methods delivers substantial improvement over target-only training, but the relationship between selection ratio and performance is non-monotonic. The most salient observations include:
The paper makes a strong empirical claim that augmenting with a small, carefully selected subset of source-domain data—using importance weighting or Moore-Lewis selection—substantially outperforms using the full source dataset or random sampling, with importance weighting yielding the best peak F1.
Negative Transfer Analysis
Qualitative review and lexical statistics reveal that the uppermost-ranked source samples according to selection scores correspond to meaningful alignment regarding domain-relevant concepts (e.g., mappings between inactivity timeouts in GDPR and HIPAA security controls). By contrast, as selection thresholds widen, generic or superficial legal phrasing contaminates the augmented dataset, inducing spurious lexical overlap without true semantic transfer, thereby causing negative transfer and empirical loss. The analysis supports capping source augmentation at low percentiles and using signal metrics sensitive to semantic alignment rather than surface overlap.
Implications and Future Directions
Practical Implications
- Principled data selection is crucial to safe and effective cross-domain transfer in regulatory compliance detection tasks; naively increasing training set size with uncontrolled cross-domain data can degrade model reliability.
- Embedding-based and density ratio techniques are comparatively robust, but their operational benefits are sensitive to selection ratios, and both require careful calibration.
- These findings generalize to compliance systems targeting regulatory heterogeneity, where annotated target data are scarce—demonstrating a pathway to scalable, explainable compliance verification.
Theoretical Implications and AI Research Outlook
This work reinforces the centrality of distributional alignment and domain adaptation theory within NLP for legal and regulatory text analysis. The observation of non-monotonic transfer curves and catastrophic negative transfer at particular augmentation ratios has direct theoretical relevance for transfer learning research, renewable in broader multi-domain adaptation scenarios.
Future investigations should expand empirical analysis to other legal regimes (e.g., finance, safety standards), develop compliance-specific representations (such as domain-aware LMs), and explore synthetic augmentation strategies (e.g., paraphrasing, backtranslation, structure-guided generation). Further, analysis of internal model representations and explanation faithfulness is required for high-stakes compliance automation systems to enhance trust and traceability.
Conclusion
The study provides a comprehensive and data-driven framework for cross-domain compliance detection, demonstrating that targeted selection of cross-domain data—especially via importance weighting and Moore-Lewis entropy difference—enables superior model transferability while mitigating negative transfer. These insights hold direct implications for the design of cross-regulatory compliance automation and transfer learning methodologies in NLP, and suggest promising directions for principled, scalable, and trustworthy AI systems in high-stakes legal contexts.