Tempered Sequential Monte Carlo for Trajectory and Policy Optimization with Differentiable Dynamics
Abstract: We propose a sampling-based framework for finite-horizon trajectory and policy optimization under differentiable dynamics by casting controller design as inference. Specifically, we minimize a KL-regularized expected trajectory cost, which yields an optimal "Boltzmann-tilted" distribution over controller parameters that concentrates on low-cost solutions as temperature decreases. To sample efficiently from this sharp, potentially multimodal target, we introduce tempered sequential Monte Carlo (TSMC): an annealing scheme that adaptively reweights and resamples particles along a tempering path from a prior to the target distribution, while using Hamiltonian Monte Carlo rejuvenation to maintain diversity and exploit exact gradients obtained by differentiating through trajectory rollouts. For policy optimization, we extend TSMC via (i) a deterministic empirical approximation of the initial-state distribution and (ii) an extended-space construction that treats rollout randomness as auxiliary variables. Experiments across trajectory- and policy-optimization benchmarks show that TSMC is broadly applicable and compares favorably to state-of-the-art baselines.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper presents a new way to make robots (or any system with physics) figure out good actions over time. The authors combine two big ideas:
- use math that treats “finding a good controller” like “figuring out the most likely explanation” (this is called casting control as inference), and
- use a smart sampling method (Tempered Sequential Monte Carlo, or TSMC) that mixes random exploration with gradient-based moves to find low-cost, high-quality solutions.
In short: they propose a principled method that explores widely like sampling methods, but also moves smartly using gradients from a differentiable simulator, so it’s less likely to get stuck in bad solutions.
What questions are the authors asking?
- How can we design a single algorithm that works both for:
- trajectory optimization (finding a good fixed sequence of actions), and
- policy optimization (training a policy that maps states to actions),
- under a simulator where everything is differentiable?
- Can we combine the strengths of random search (explores broadly) and gradient-based methods (moves efficiently) to handle tough problems with many local traps?
- Can we sample effectively from very “sharp” and “bumpy” target landscapes, where many different good solutions might exist?
How does their method work?
Key idea: Treat control as inference
Instead of picking one “best” controller directly, the authors define a whole distribution over possible controllers. Controllers that lead to lower cost (better performance) are given higher probability. Think of a “landscape” where valleys are good (low cost). The method builds a probability that piles up in the valleys.
- They start from a simple “prior” distribution (like “reasonable guesses”).
- They “tilt” this prior toward good controllers using a “temperature” knob λ:
- High temperature = smoother, more exploratory (many controllers have similar probability).
- Low temperature = sharper, more focused on the very best controllers.
- This creates what they call a Boltzmann-tilted distribution: better (lower-cost) controllers get exponentially more weight.
The sampler: Tempered Sequential Monte Carlo (TSMC)
Sampling from a sharp, bumpy landscape is hard. TSMC tackles this by:
- Tempering (like cooling metal): it creates a sequence of easier-to-harder distributions, starting from the simple prior and slowly “turning up” the influence of cost.
- Particles (like a crowd of candidates): it keeps a set of many candidate controllers (particles) and updates their weights based on how well they perform.
- Resampling: it keeps the good candidates (with higher weights) and drops the poor ones, so computation focuses on promising areas.
- Rejuvenation with HMC (Hamiltonian Monte Carlo): this is a smart way to move particles around using gradient information from the simulator—imagine sliding along the slopes of the landscape to make big, efficient jumps without getting lost.
Together, these steps explore widely early on, then zoom in carefully on good solutions as the “temperature” cools.
Making it work for policies too
For a policy (a rule that maps any state to an action), you have to care about many starting points, not just one. The authors provide two practical tricks:
- Deterministic approximation: replace the “random initial states” by a fixed set of starting points, average their costs, and use that as a stable, differentiable target. This keeps everything deterministic so TSMC can work as-is.
- Extended-space approach: treat the random starting states as part of each particle. Then alternate:
- Update the controller using HMC while holding the starting states fixed.
- Refresh the starting states (randomly, with a check that prefers lower cost).
- This keeps the sampler principled while handling randomness.
What did they find?
The authors tested their method on both trajectory optimization and policy optimization tasks.
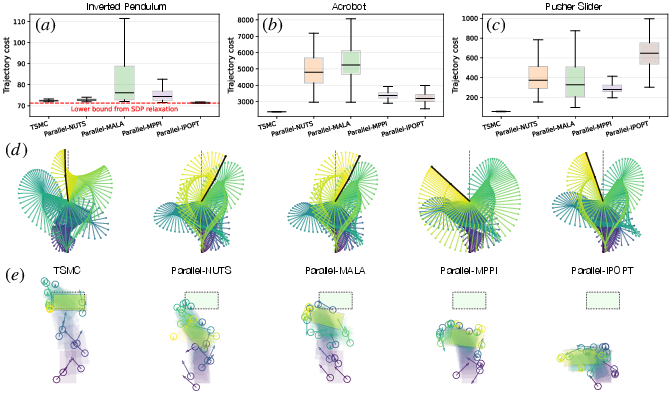
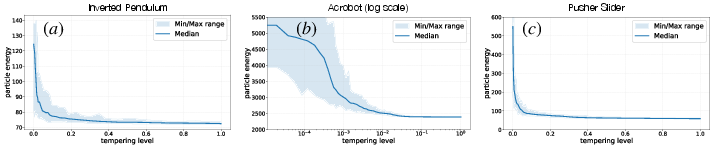
- Trajectory optimization (fixed sequence of actions):
- Inverted pendulum: TSMC found solutions very close to a certified best possible lower bound, matching or beating strong baselines (like advanced gradient-based solvers and other samplers).
- Acrobot (two-link pendulum): TSMC clearly outperformed other methods; it was the only one to reliably swing the system to the upright target.
- Pusher–slider (contact-heavy, nonsmooth): TSMC again did best and was the only method to reach the goal pose among the tested approaches.
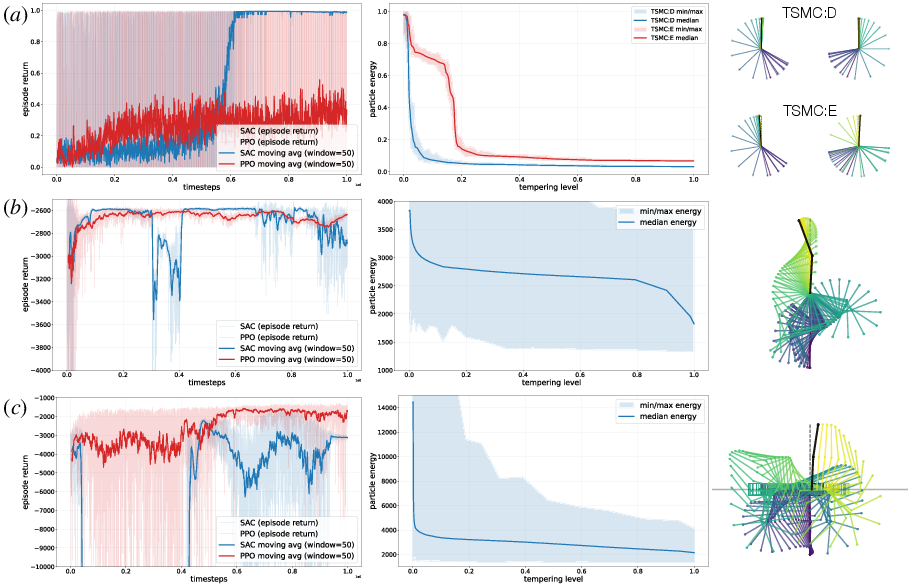
- Policy optimization (learning a policy for many starting states):
- Inverted pendulum with sparse rewards: TSMC variants achieved performance comparable to a strong reinforcement learning baseline (SAC) and better than PPO within the tested time.
- Other classic control tasks (e.g., acrobot, double pendulum on a cart): TSMC showed solid performance and favorable trends (the paper shows tempering progress and example rollouts).
Why this matters:
- Sampling-only methods often need tons of trials.
- Gradient-only methods can get stuck in bad local minima.
- TSMC blends both: it explores broadly and moves efficiently using gradients, handling tough, multimodal landscapes better.
Why is this important?
- Robustness: By not betting everything on one starting guess, and by gradually “cooling” toward the best solutions, TSMC reduces the chance of getting trapped in poor local minima.
- Generality: The same framework works for both single-trajectory problems and full policies covering many starting situations.
- Efficiency: Using gradients from differentiable simulators (which are increasingly available) helps the sampler make bigger, smarter moves.
- Practical performance: Across several benchmarks, TSMC matched or exceeded strong existing methods, especially on harder, more “bumpy” problems.
A brief note on limitations and future potential
- The approach assumes you can compute gradients through the simulator (differentiable dynamics). For some contact-rich environments, getting stable, useful gradients is still a challenge in current toolchains.
- The extended-space method targets a slightly different, risk-sensitive version of the original objective (though this gap shrinks with larger batches).
Overall, this work points to a promising direction: combining principled sampling with gradient information to make robots (and other dynamic systems) plan and learn more reliably in complex situations.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, organized to guide future research.
- Finite-sample and non-asymptotic guarantees for TSMC in this setting are absent (e.g., error bounds on estimators, conditions for mode coverage, sample complexity vs. dimensionality, degeneracy rates along the tempering path).
- Choice of temperature λ and its effect on solution quality is not principled; there is no guidance on selecting λ, annealing endpoints, or stopping rules to ensure concentration near global optima as .
- Scalability to high-dimensional policies is untested: experiments use small MLPs (two layers, 32 units) and modest horizons; it remains unclear how TSMC performs with large neural policies (e.g., millions of parameters), long horizons, or high-dimensional action spaces.
- Mass-matrix preconditioning in HMC is fixed to identity; the benefits/necessity of geometry-aware choices (e.g., adaptive diagonal/full mass matrices, RMHMC, Fisher preconditioning) for mixing in high dimensions are not explored.
- Sensitivity to hyperparameters (number of particles N, ESS threshold ρ, HMC step size and adaptation, number of tempering levels, NUTS settings) is not systematically analyzed; practitioners lack ablation studies or default heuristics.
- Computational cost vs. performance trade-offs are not quantified: there are no wall-clock or flop-normalized comparisons, making it unclear when TSMC is competitive given its resample–move overhead and HMC costs per particle.
- Mode exploration and coverage are not measured; the paper does not quantify how many modes are discovered or retained at low temperatures, nor how tempering-path design affects mode loss.
- The tempering path is limited to a simple geometric bridging; alternative or adaptive bridges (e.g., mixture bridges, learned/flow-based paths, variance-minimizing bridges) are not investigated for harder multimodal targets.
- Comparison to stronger trajectory-optimization baselines is limited: iLQR/DDP, CEM/MPPI variants with better temperature schedules, and recent gradient-based TO methods using differentiable simulators are not evaluated.
- For policy optimization, comparisons to model-based RL and value-gradient methods that explicitly leverage differentiable dynamics (e.g., MBPO-style, value gradients, modern differentiable MPC) are missing.
- The deterministic approximation for PO (replacing μ with an empirical ) risks overfitting to the fixed initial-state set; strategies to select/update the set, assess generalization to the true μ, or bound the induced bias are not provided.
- The extended-space PO variant targets a risk-sensitive marginal (expectation of an exponential) rather than the intended Boltzmann tilt; there is no quantitative bound on the discrepancy or guidance on choosing to control this bias.
- No experiments validate the PO extended-space method with disturbance/noise; extensions to stochastic dynamics are discussed but untested, leaving open the practical efficacy with process/measurement noise.
- The acceptance rate and mixing behavior of the auxiliary-variable refresh for initial states in the extended-space method are unreported; potential slow mixing with independent proposals from μ is unaddressed (e.g., blocked/tempered refresh, correlated proposals).
- The impossibility or difficulty of unbiased weighting with is noted but not addressed algorithmically; exploration of debiased or pseudo-marginal SMC/HMC alternatives (e.g., correlated pseudo-marginal, Poisson estimators, Rhee–Glynn) is left open.
- Handling of non-smooth dynamics remains ad hoc (e.g., Gumbel–Softmax relaxations for contact); rigorous treatment of non-smoothness (subgradient, proximal dynamics, event-driven adjoints) and its impact on gradient quality and sampler stability is not explored.
- The impact of differentiable contact relaxations on solution fidelity is unknown; there is no analysis of how relaxation temperatures, smoothing choices, or rounding back to discrete modes affect optimality and stability of the resulting trajectories.
- The method assumes differentiable dynamics; robustness to model mismatch or learned differentiable world models (and the effect of model errors on the target distribution and sampler) is not studied.
- Constraint handling is implicit via costs; there is no framework for hard state/control constraints, manifold constraints, or HMC on constrained spaces (e.g., reflective HMC, constrained HMC), nor analysis of constraint-violation rates in proposals.
- Real-time or MPC use is not considered; how to warm-start TSMC across receding horizons, reuse particles, or amortize computation to meet control-loop deadlines is an open question.
- Only one task (inverted pendulum) has a certified lower bound; for other tasks, global optimality is unknown, and there is no mechanism to estimate optimality gaps or provide certificates.
- The prior (e.g., AR priors for controls) is hand-chosen; there is no study of prior design’s impact on performance, nor adaptive/learned priors tailored to system structure or policy architectures.
- Annealing-endpoint selection is not formalized; criteria to terminate tempering (e.g., based on ESS, energy gaps, or diagnostics of mode collapse) and their effect on solution quality are missing.
- Diagnostics and failure modes (e.g., HMC divergence, extremely large gradients in contact-rich settings) are acknowledged but not addressed; mitigation strategies (gradient clipping, smoothing schedules, line-search HMC) remain unexplored.
- Broad applicability to contact-rich benchmarks is limited by current differentiable simulators (e.g., MJX issues, large gradients in Brax); integration with emerging differentiable contact solvers or alternative adjoint techniques is an open engineering and research direction.
- Generalization to stochastic or risk-aware objectives is only hinted at; rigorous links to stochastic optimal control (e.g., risk-sensitive costs, path-integral control) and the consequences for policy behavior are not elaborated.
- The effect of resampling scheme choice (multinomial vs. stratified/systematic/residual) on variance, mode retention, and bias is not studied.
- Theoretical analysis of convergence to global minimizers as (e.g., probability of sampling ε-optimal controllers as a function of N, schedule, and dimensionality) is not provided.
- Fairness of compute budgets in comparisons is unclear (e.g., number of MPPI steps, NUTS iterations, and IPOPT wall-time/cores); normalized performance-per-compute comparisons are needed to contextualize gains.
- No hardware experiments are performed; robustness to real-world disturbances, sensing noise, and model discrepancies, as well as safety considerations during exploration, remain untested.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now using the paper’s methods and insights, along with sectors, indicative tools/workflows, and key feasibility assumptions.
- Robotics (manufacturing, lab automation) — Offline trajectory optimization for non-contact or smoothly modeled tasks
- Use case: Generate diverse, low-cost open-loop trajectories for pick-and-place, point-to-point motion, or swing-up style tasks (e.g., manipulators, pendulum-like mechanisms).
- Tools/workflow: JAX-based TSMC + BlackJax/NUTS; differentiable dynamics in Brax/Dojo or custom JAX simulators; parallel GPU sampling to produce a portfolio of near-optimal trajectories; select best or ensemble.
- Assumptions/dependencies: Differentiable dynamics available; costs and controllers are differentiable; compute budget for particle-based sampling; temperature/ESS tuning stable.
- Robotics (manipulation) — Quasi-static pushing and other relaxed-contact tasks
- Use case: Plan contact-rich maneuvers where a differentiable relaxation (e.g., Gumbel–Softmax for contact modes) is acceptable and useful for finding multiple feasible strategies (e.g., pushing on different faces).
- Tools/workflow: TSMC with relaxed discrete decisions; automatic differentiation through rollout; post-processing to discretize contact modes and re-simulate for validation.
- Assumptions/dependencies: Relaxed contact model is an adequate surrogate; careful smoothing/annealing schedules; validation in a high-fidelity or non-relaxed simulator.
- Control engineering (process control, mechatronics) — Auto-tuning controller parameters
- Use case: Optimize parameters of PID or neural controllers against differentiable plant models, sampling multiple good settings to improve robustness and avoid local minima.
- Tools/workflow: Define costs (tracking error, energy use), set Gaussian prior on parameters, run TSMC to obtain low-cost parameter samples; pick best or deploy an ensemble.
- Assumptions/dependencies: Differentiable surrogate or reduced-order plant model; adequate gradient quality; offline compute; stable regularization/temperature selection.
- Model-based RL (education/classical control benchmarks) — Policy optimization under initial-state uncertainty
- Use case: Train state-feedback policies for tasks like inverted pendulum, acrobot, double pendulum using TSMC:D (deterministic empirical initial-state set) or TSMC:E (extended-space) for robust performance over initial states.
- Tools/workflow: MLP policy in JAX; fixed mini-batch of initial states for TSMC:D; batched initial conditions for TSMC:E; HMC rejuvenation with backprop through rollouts.
- Assumptions/dependencies: Differentiable dynamics; stable gradient magnitudes; batch size B large enough to capture variability; risk-sensitive bias in TSMC:E understood and acceptable.
- Robotics and control research (academia) — Multimodal “control-as-inference” baseline
- Use case: Benchmark against MPPI, CEM, NLP/SQP (e.g., IPOPT) on nonconvex tasks; analyze failure modes due to local minima; study annealing and gradient-informed sampling.
- Tools/workflow: Plug-and-play TSMC with adaptive tempering and NUTS; replicate paper’s baselines; ablate prior design and temperature schedules.
- Assumptions/dependencies: Access to differentiable simulation; reproducible compute; community toolchain (JAX/BlackJax) available.
- Software engineering (tooling) — Add-on module for JAX control stacks
- Use case: Provide a TSMC kernel for trajectory/policy search in JAX control libraries as an alternative to MPPI or gradient-only solvers.
- Tools/workflow: Wrap TSMC (importance reweighting, resampling, HMC/NUTS moves) as an API; expose priors, annealing, ESS targets; integrate with differentiable simulators.
- Assumptions/dependencies: User base with JAX simulators; moderate GPU resources; API design that hides tuning complexity but exposes expert controls.
- Robust initialization for local solvers (industrial automation)
- Use case: Use TSMC to generate diverse, low-cost initializations for IPOPT/SQP or shooting methods, reducing the chance of poor local minima and speeding convergence.
- Tools/workflow: Run short TSMC tempering schedule to produce a shortlist; pass top-k candidates to a local solver; compare time-to-solution and optimality gap.
- Assumptions/dependencies: Compatible dynamics/costs between TSMC and local solver; ability to warm-start; compute budget for a brief sampling phase.
- Safety-oriented controller selection (QA in labs and testbeds)
- Use case: Evaluate multiple candidate controllers sampled by TSMC against edge-case initial conditions to select safer controllers before hardware deployment.
- Tools/workflow: Use TSMC:E to bias toward controllers stable across many initial states (risk-sensitive marginal); validate top candidates on a richer test set.
- Assumptions/dependencies: Simulator-to-reality gap manageable; coverage of critical initial states; acceptance of risk-sensitive surrogate in selection.
Long-Term Applications
These scenarios need further research, scaling, or ecosystem maturation (e.g., differentiable contact solvers, real-time performance).
- Real-time, sampling-based MPC (robotics, autonomous systems)
- Use case: Replace or augment MPPI/CEM in onboard MPC with TSMC for sharper, multimodal targets; adaptively explore and exploit with gradient-informed proposals.
- Tools/products/workflows: JIT-compiled TSMC on GPU/TPU; warm-start particles across MPC steps; sparse updates to maintain real-time budgets.
- Assumptions/dependencies: Significant systems engineering; fast differentiable simulators; hardware acceleration; low-latency random number generation; scheduler integration.
- Contact-rich locomotion and dexterous manipulation (robotics)
- Use case: Learn/control complex behaviors where multiple contact mode sequences exist (e.g., legged locomotion gaits, in-hand manipulation).
- Tools/workflow: Mature differentiable contact physics (MJX/Dojo successors); mode-tempering or learned priors over contact sequences; extended-space over contact randomness/disturbances.
- Assumptions/dependencies: Stable, accurate, differentiable contact; gradient norms well-conditioned; robust annealing across discrete-continuous spaces.
- Autonomous driving/planning (automotive, mobility)
- Use case: Multimodal trajectory generation (evasive maneuvers, lane changes) under uncertain initial conditions and agent behaviors, leveraging risk-sensitive surrogates for safety margins.
- Tools/workflow: Differentiable traffic simulators/digital twins; TSMC:E over scenario batches; constraint-softening in costs for comfort/safety; controller ensemble selection.
- Assumptions/dependencies: Differentiable simulators capturing interactions; scenario generation fidelity; hard safety constraints need formal handling beyond soft costs.
- Aerospace guidance and entry–descent–landing (aerospace/defense)
- Use case: Generate diverse feasible trajectories under tight fuel/time budgets where multiple valleys in cost landscape exist.
- Tools/workflow: Differentiable high-fidelity guidance models; TSMC for offline design; later distill best trajectories/policies into flight software.
- Assumptions/dependencies: Differentiable models and verified surrogates; certification pathways for sampling-derived controllers; stringent validation.
- Energy and building systems (energy efficiency, HVAC)
- Use case: Robust policy/trajectory optimization for demand response and HVAC schedules using differentiable surrogates (e.g., learned thermal models).
- Tools/workflow: System identification to learn differentiable building/grid models; TSMC policy search with extended-space over weather/occupancy batches; risk-sensitive planning.
- Assumptions/dependencies: Accurate differentiable surrogates; policy interpretability; integration with legacy BMS/EMS; safe exploration constraints.
- Digital twins with optimization-in-the-loop (industrial operations)
- Use case: Use TSMC within differentiable digital twins to co-optimize controller parameters and trajectories under uncertainty; maintain particle sets as uncertainty-aware solutions.
- Tools/workflow: Twin calibration via differentiable learning; TSMC:E over exogenous factors; continuous re-optimization as the twin updates.
- Assumptions/dependencies: High-fidelity differentiable twins; data pipelines; compute orchestration; change management for production systems.
- Safety certification and stress testing (policy and regulation)
- Use case: Regulators or internal safety teams require probabilistic stress tests: evaluate a distribution over controllers (not a single solution) across a curated scenario bank to estimate risk.
- Tools/workflow: TSMC-generated controller distributions; adversarial or rare-event initial states as extended-space variables; reporting of coverage and tail risks.
- Assumptions/dependencies: Standardized scenario libraries; acceptance of probabilistic evidence; tooling for explainability and traceability.
- Multi-agent coordination (swarm robotics, logistics)
- Use case: Optimize joint or decentralized policies where many coordination modes exist; sample diverse equilibria or cooperative strategies.
- Tools/workflow: Differentiable multi-agent simulators; structured priors over coordination patterns; hierarchical tempering; policy distillation post-sampling.
- Assumptions/dependencies: Scale challenges (high-dimensional θ); simulator fidelity; communication and partial observability modeling.
- World-model based sim2real pipelines (robotics, AR/VR)
- Use case: Combine learned differentiable world models with TSMC to search for robust policies; then distill into smaller networks for deployment; employ domain randomization in extended-space.
- Tools/workflow: Train world models (JAX/PyTorch); TSMC:E over randomization parameters; policy distillation or imitation learning from particle elites.
- Assumptions/dependencies: World-model accuracy and stability; transferability to real systems; safeguards for model bias.
- Amortized inference for controller sampling (software, platforms)
- Use case: Train a fast sampler or conditional policy that approximates the Boltzmann target across tasks/temperatures to reduce run-time cost of TSMC.
- Tools/workflow: Meta-learning or normalizing flows conditioned on task/context; offline TSMC to generate supervision; deployment as a service in control stacks.
- Assumptions/dependencies: Coverage of training tasks; calibration of learned samplers; monitoring for distribution shift.
- Constrained and safe RL/control (cross-sector)
- Use case: Incorporate constraints (safety, resource) as penalties or barrier terms within the energy; use TSMC to explore feasible low-cost regions more reliably than gradient-only methods.
- Tools/workflow: Cost shaping with barrier/penalty annealing; constraint satisfaction checks on sampled solutions; fallback to conservative controllers.
- Assumptions/dependencies: Soft constraints may be insufficient; may require projection or feasibility restoration steps; certification workflows.
- Healthcare/biomedical scheduling (long-horizon planning with surrogates)
- Use case: Optimize treatment schedules or rehabilitation controllers using differentiable patient or device models (e.g., prosthetic control with differentiable musculoskeletal models).
- Tools/workflow: Learned differentiable physiological models; TSMC policy search with extended-space across patient variability; clinician-in-the-loop selection.
- Assumptions/dependencies: Model fidelity, ethics and IRB approvals; explainability; rigorous clinical validation cycles.
Notes on cross-cutting assumptions
- Differentiability is central: dynamics, costs, and policies must be differentiable or have high-quality differentiable surrogates.
- Compute and tooling: particle methods benefit from GPU/TPU acceleration; robust implementation of HMC/NUTS and adaptive tempering is required.
- Temperature, prior, and ESS schedule matter: performance and stability depend on sensible priors, annealing schedules, and weight-degeneracy control.
- Risk-sensitive bias in TSMC:E: the extended-space marginal induces an exponential-utility objective; its impact must be understood or mitigated (e.g., larger batch sizes B, calibration).
- Sim-to-real transfer: for real-world deployment, validate in high-fidelity simulators and on hardware; consider uncertainty, constraints, and safety layers.
Glossary
- Adjoint method: A reverse-mode sensitivity technique that computes gradients via backward recursion of costates for dynamical rollouts. Example: "using the adjoint method."
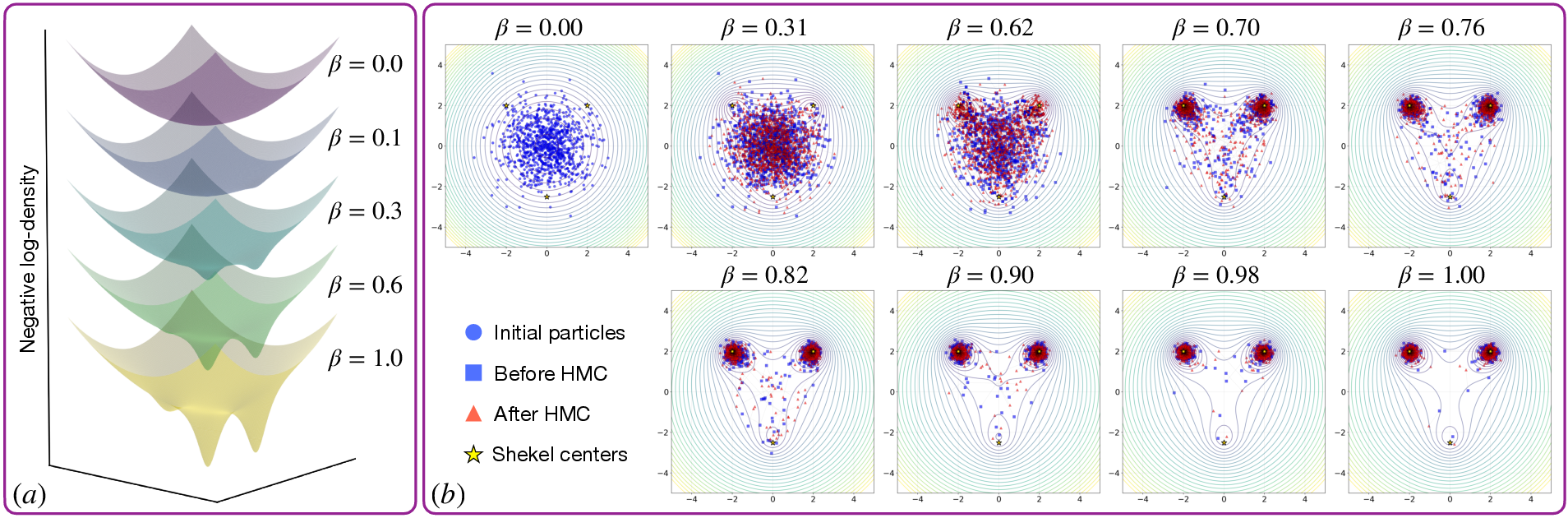
- Annealing: A gradual deformation of a distribution (or objective) by adjusting a temperature parameter to move from an easy to a hard target. Example: "an annealing scheme that adaptively reweights and resamples particles along a tempering path"
- Autoregressive prior: A time-series prior where each control depends on previous controls, encouraging smoothness. Example: "We use a first-order autoregressive prior"
- Boltzmann-tilted distribution: A distribution obtained by exponentially weighting a prior with negative energy (cost) divided by temperature. Example: "sampling from the Boltzmann-tilted distribution"
- Categorical distribution: A discrete probability distribution over a finite set of categories or indices. Example: "from the categorical distribution with probabilities"
- Cross-entropy method: A sampling-based optimization algorithm that iteratively updates a proposal toward low-cost regions via elite samples. Example: "the cross-entropy method"
- Detailed balance: An MCMC condition ensuring the target distribution is invariant under the Markov transition. Example: "to enforce detailed balance with respect to the target density"
- Dirac measure: A probability measure concentrated at a single point (a point mass). Example: "(a Dirac measure)"
- Effective sample size (ESS): A diagnostic measuring weight degeneracy in importance sampling or SMC, indicating the equivalent number of uniformly weighted samples. Example: "effective sample size (ESS)"
- Energy function: The expected trajectory cost used to define the exponential tilt of the prior in the Boltzmann formulation. Example: "Define the energy function"
- Extended-space construction: A pseudo-marginal approach that augments parameters with auxiliary variables (e.g., initial states) so standard samplers can target a marginal of interest. Example: "an extended-space construction that treats rollout randomness as auxiliary variables."
- Gibbs posterior: A posterior-like distribution formed by exponentiating negative empirical risk (energy) times an inverse temperature and multiplying by a prior. Example: "a.k.a. the Gibbs posterior"
- Gumbel--Softmax trick: A differentiable relaxation for sampling from categorical distributions, enabling backpropagation through discrete choices. Example: "the Gumbel--Softmax trick"
- Hamiltonian: The sum of potential (negative log-density) and kinetic energy that defines dynamics for HMC proposals. Example: "defines the Hamiltonian"
- Hamiltonian dynamics: Continuous-time dynamics derived from Hamilton’s equations used to propose long-distance moves in HMC. Example: "simulating Hamiltonian dynamics"
- Hamiltonian Monte Carlo (HMC): An MCMC method that uses Hamiltonian dynamics and a Metropolis step to efficiently explore target distributions. Example: "Hamiltonian Monte Carlo (HMC)"
- Importance sampling: A technique that reweights samples from a proposal distribution to estimate expectations under a target distribution. Example: "Importance Sampling."
- Kullback--Leibler (KL) divergence: An information-theoretic measure of discrepancy between two probability distributions. Example: "Kullback--Leibler (KL) divergence"
- Leapfrog integrator: A symplectic numerical scheme used in HMC to simulate Hamiltonian dynamics while preserving volume and reversibility. Example: "symplectic leapfrog integrator"
- Mass matrix: A positive-definite matrix defining the momentum covariance in HMC, shaping proposal trajectories. Example: "is a mass matrix"
- Metropolis--Hastings: An accept/reject mechanism that ensures MCMC proposals leave the target distribution invariant. Example: "Metropolis--Hastings accept/reject step"
- Metropolis-adjusted Langevin algorithm (MALA): An MCMC method using gradient-informed proposals with a Metropolis correction. Example: "Metropolis-adjusted Langevin algorithm (MALA)"
- Model predictive path integral control (MPPI): A sampling-based control method that updates controls by weighting rollouts with exponentiated negative costs. Example: "model predictive path integral control (MPPI)"
- NUTS: An adaptive HMC variant that selects trajectory length by avoiding U-turns in parameter space. Example: "the NUTS sampler"
- Partition function: The normalizing constant of an exponential-family-like distribution ensuring probabilities sum (integrate) to one. Example: "normalizing constant (partition function)"
- Pseudo-marginal methods: Techniques that run MCMC on an augmented space using unbiased estimators so that the desired marginal is targeted exactly in law. Example: "Pseudo-marginal methods address intractable expectations"
- Quasi-static model: A model assuming instantaneous force/motion balance (negligible inertia), often used in contact mechanics. Example: "the quasi-static model"
- Resampling: An SMC step that replaces a weighted particle set with an approximately unweighted one by sampling ancestors according to weights. Example: "Resampling converts this weighted set into an approximately unweighted one"
- Reverse-mode automatic differentiation: A gradient computation technique that backpropagates sensitivities, efficient for scalar-valued objectives. Example: "reverse-mode automatic differentiation"
- Risk-sensitive (exponential utility) objective: An objective that averages exponentiated costs, emphasizing higher costs more strongly than the mean. Example: "a risk-sensitive (exponential utility) objective"
- Semidefinite programming (SDP) relaxations: Convex optimization relaxations using semidefinite constraints to bound or approximate nonconvex problems. Example: "semidefinite programming (SDP) relaxations"
- Shekel function: A multimodal benchmark function with multiple local minima used to test optimization/sampling algorithms. Example: "negative Shekel function"
- State-feedback policy: A control law mapping the current state directly to the control input. Example: "state-feedback policy"
- Tempered Sequential Monte Carlo (TSMC): An SMC framework that introduces a sequence of tempered targets with reweighting, resampling, and MCMC rejuvenation. Example: "tempered sequential Monte Carlo (TSMC)"
- Tempering path: A sequence of intermediate distributions interpolating between a prior and a target by varying an inverse-temperature parameter. Example: "a tempering path"
- Variational integrator: A structure-preserving time discretization derived from a variational principle, offering good energy behavior for mechanical systems. Example: "variational integrator"
Collections
Sign up for free to add this paper to one or more collections.

