- The paper introduces a comprehensive dataset for decentralized prediction markets, capturing full lifecycle data across off-chain metadata, on-chain trading events, and oracle resolutions.
- The methodology integrates heterogeneous data sources using robust entity resolution techniques, achieving over 99.4% linkage accuracy between market events.
- Empirical findings highlight practical applications in sports probability calibration and macroeconomic forecasting, emphasizing the dataset's value for mechanism design and market efficiency research.
A Comprehensive Suite of Datasets for the Full Lifecycle of Decentralized Prediction Markets
Introduction and Motivation
The paper "Unlocking the Forecasting Economy: A Suite of Datasets for the Full Lifecycle of Prediction Market: [Experiments {title} Analysis]" (2604.20421) presents a full-lifecycle, continuously maintained dataset covering decentralized prediction markets on Polymarket. The dataset deeply integrates off-chain market metadata, on-chain fill-level trading events, and oracle resolution data, offering unprecedented granularity and completeness in tracing the formation, trading, adjudication, and settlement of event-based contracts. These capabilities address fundamental challenges in empirical research on information aggregation, incentive design, participant behavior, and price discovery within blockchain-based financial primitives.
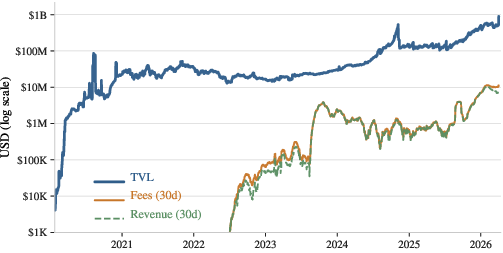
Figure 1: Amount of total value locked (TVL), 30-day rolling fees, and 30-day rolling revenue in the prediction market.
The operational context is a rapidly scaling decentralized prediction ecosystem (as reflected by TVL and fees in Figure 1), with the lifecycle and data flow deeply divergent from conventional asset markets. Notably, decentralized prediction platforms diverge from their CeFi and TradFi counterparts by enabling trade in claims on yet-unrealized random variables, with order-book states, trade execution, and post-trade settlement all staged across smart contracts, external oracles, and off-chain UI/UX layers.
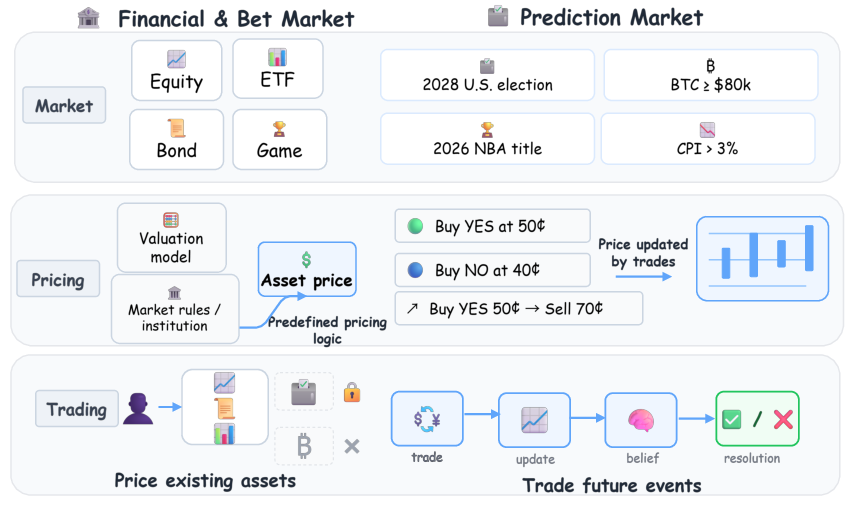
Figure 2: Key differences between traditional financial markets and prediction markets, centering on market scope, pricing logic, and trading process.
Dataset Construction: Canonical, Multi-Layer, and Continuously Synchronized
The central technical contribution is the integration of data across heterogeneous representation, identifier, and timing conventions. The core database interlinks three canonical relations: (1) market metadata (semantic identification and structuring), (2) fill-level trading events (granular on-chain executions), and (3) oracle-resolution events (question initialization, disputes, and settlements). This is nontrivial due to asynchronous event timing, incomplete or lagging off-chain records, ad hoc identifier overlaps, and the necessity for replay-safe, resumable ingestion.
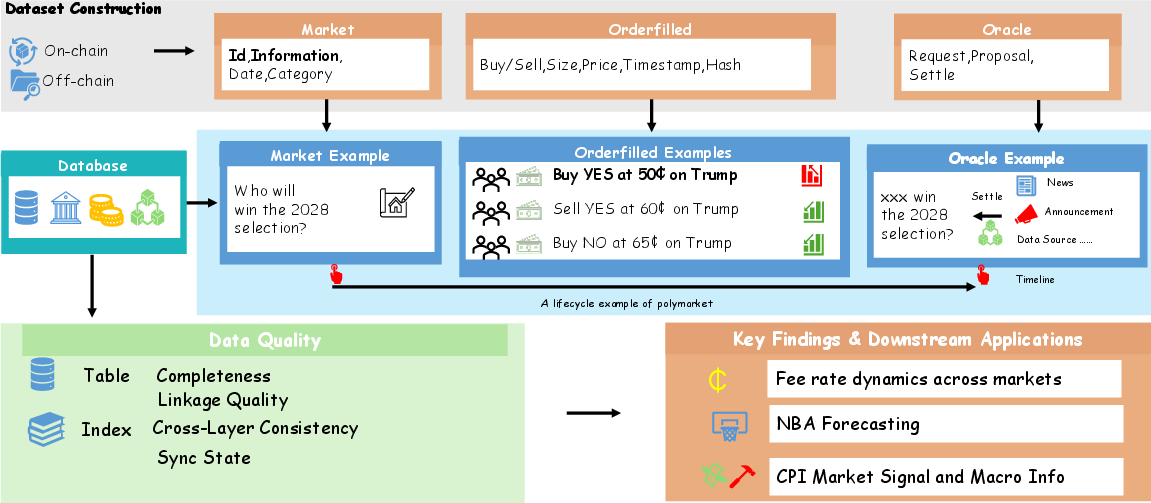
Figure 3: Overview of the pipeline integrating off-chain and on-chain data sources into a three-layer canonical database supporting system evaluation and downstream applications.
The pipeline encapsulates robust procedures for entity resolution, bridging off-chain Gamma API schemas with on-chain contract and token mappings, and leverages on-chain event scans to repair and backfill sparse or missing API coverage. The data system preserves state checkpoints and replay safety for all layers, supporting both historical backfill and incremental live synchronization, and employs auxiliary bridge/cache relations for cross-layer identifier alignment and temporal mapping.
By March 2026, the dataset contains 770,880 market records, 943 million fill events, nearly 2 million oracle events, and over 2.4 million unique trader addresses. Critically, more than 99.4% of trade and settlement events are linked to canonical markets, validating near-complete lifecycle coverage.
Data Quality and Ablation Findings
The dataset’s linkage and entity-resolution efficiency is rigorously evaluated through ablation. On-chain recovery enhances token-entity mapping from 18.75% to 100% in challenging samples, with deterministic, replayable trade and oracle event linkage rates exceeding 99.4%. The bridge layer elevates oracle-to-market association from 73.4% (direct) to over 99.4%, a necessary enabler for credible lifecycle analytics.
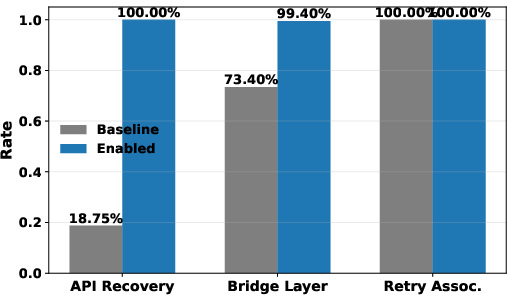
Figure 4: Quantitative quality gains from key ablation mechanisms for market and oracle mapping.
Empirical Observations: Market Structure, Participation, Oracle Risk, Fee Design
Topic analysis reveals that the Polymarket ecosystem is tightly clustered around sports and cryptocurrency speculation in both market count and trading volume, with political and macroeconomic themes forming secondary clusters.
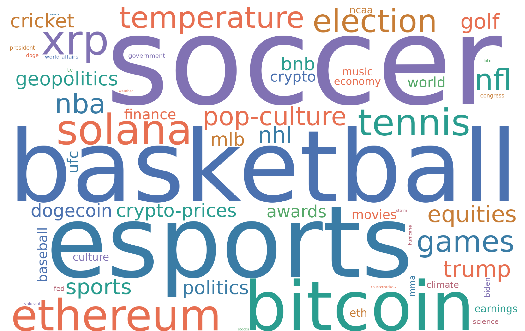
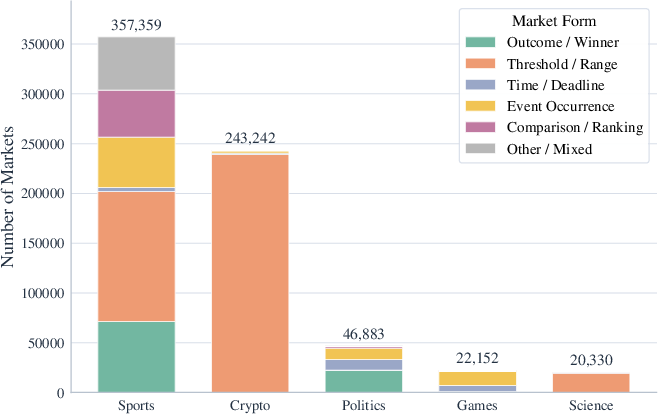
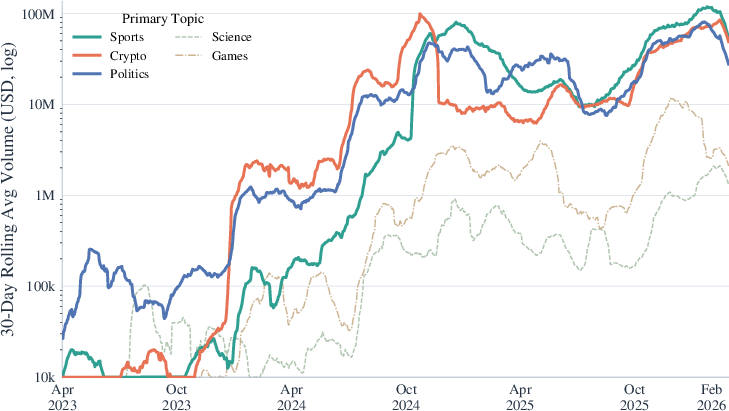
Figure 5: Primary topic keyword cloud shows the dominance of sports and crypto as content and participation foci.
Activity traces indicate sharp, nonstationary dynamics – notably, correlated surges in user onboarding around real-world events (e.g., major elections), followed by rapid growth in both market diversity and transaction counts in 2025-2026.
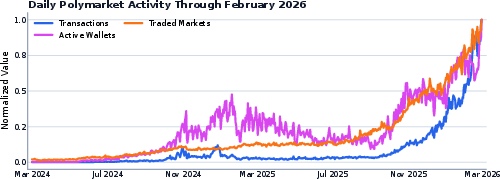
Figure 6: Normalized daily activity (transactions, active wallets, traded markets), capturing the inflection points tying market growth to real-world events.
Oracle disputes, although infrequent (<1% of all markets), trigger nontrivial post-anchor trading: over 99% of markets with a dispute continue to see trades within 24 hours of the event, with reactions differentiating into an immediate ‘speculative entry’ phase and a delayed ‘concentration’ phase.
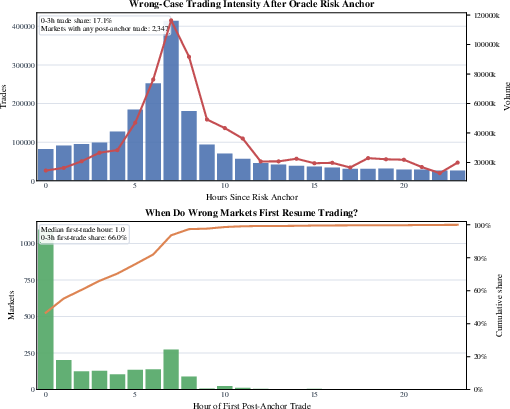
Figure 7: Hourly trading intensity following oracle risk anchor reveals a two-stage reaction in wrong-case markets.
Fee regime analysis confirms that effective fees are not assigned uniformly but reflect strong cross-category heterogeneity, with categories such as Crypto and Sports subject to markedly higher effective rates compared to others, independent of raw trade volume. Correlation between fees and trade volume is low (r∼0.17), indicating discretionary rather than volume-driven fee assignment.
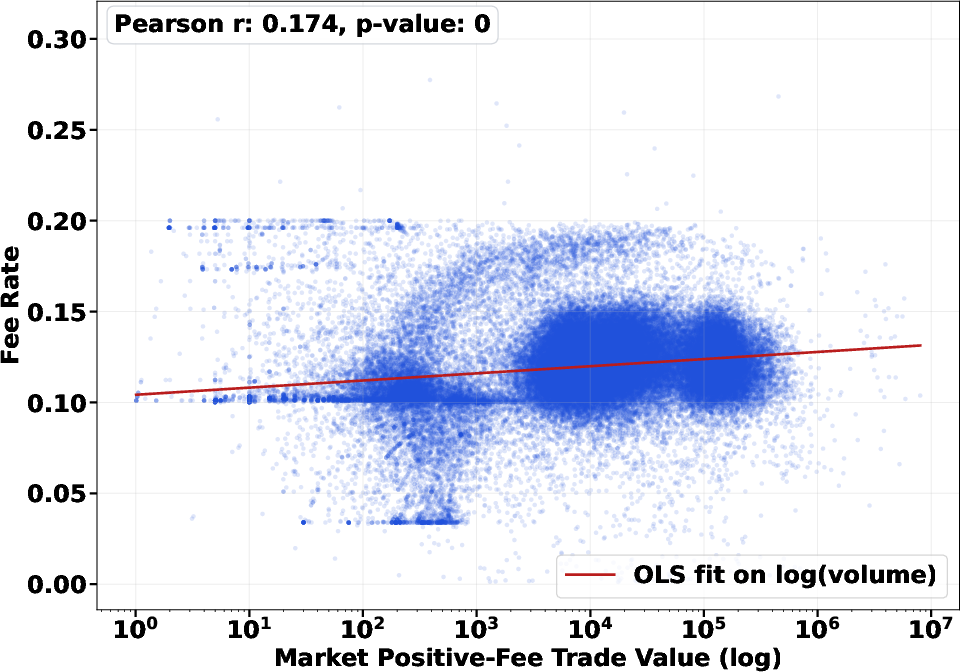
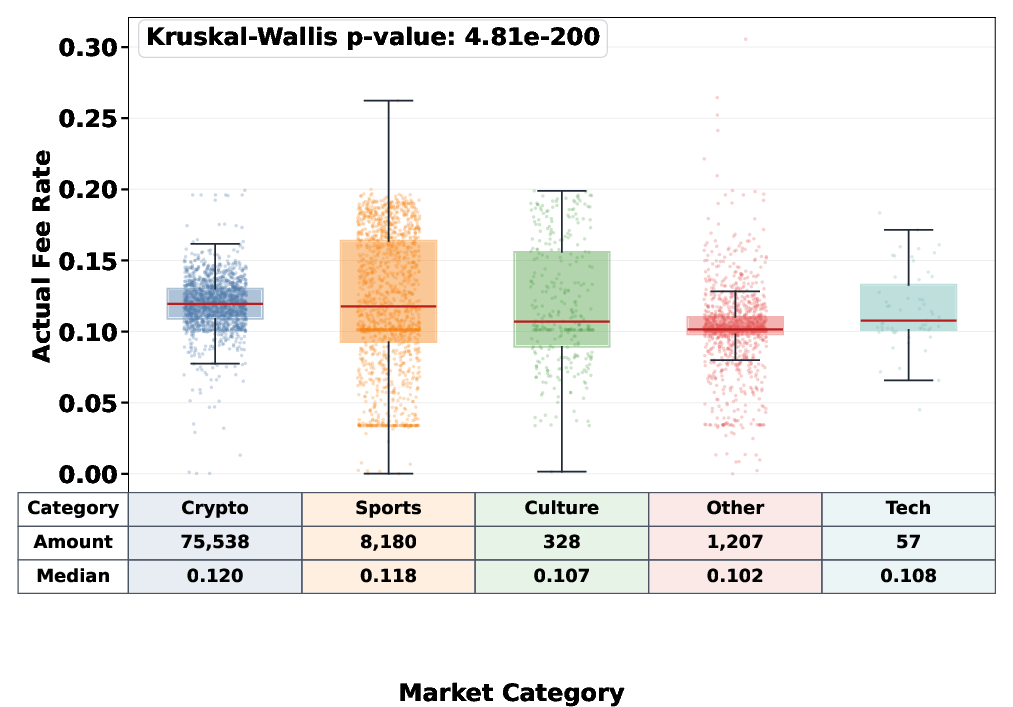
Figure 8: Approximation threshold ≥0.001. Weak empirical correlation between market trading volume and effective fee rates.
Downstream Applications: Market Probability Calibration and Macroeconomic Signaling
NBA Winner Market Calibration
The integrated dataset enables disaggregated analysis of market-implied probabilities versus realized outcomes for sports contests. Analysis of over 4,000 NBA winner markets—after rigorous normalization and volume-weighted probability construction—shows that raw Polymarket-implied probabilities are already well calibrated to physical win frequencies across the support. Isotonic calibration delivers negligible additional correction (Brier score: 0.203, LogLoss: 0.592, ECE: 0.027, MCE: 0.084 on test years), indicating high informational efficiency in these markets.
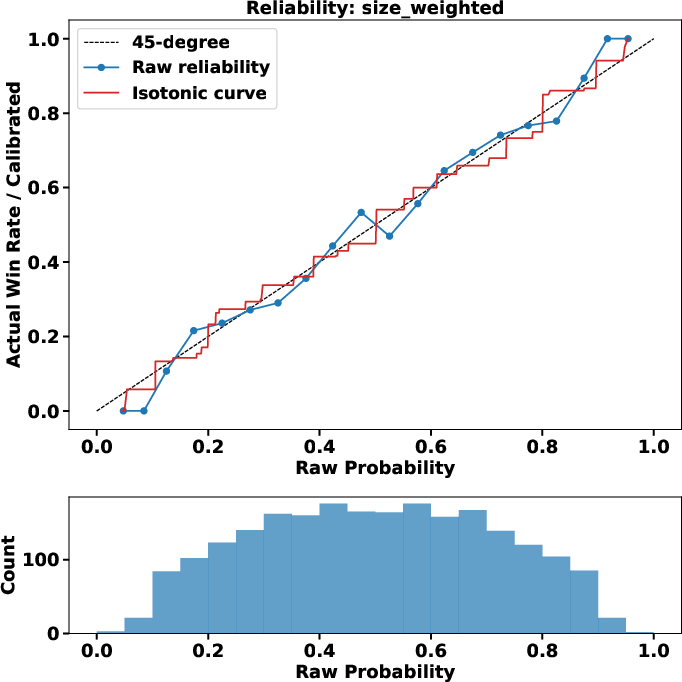
Figure 9: Market-implied probabilities for NBA winners are broadly well calibrated compared to empirical win rates.
CPI Expectation Reconstruction
A second, nontrivial application is the translation of bucketed outcome markets for U.S. monthly CPI into a continuous probability-weighted macroeconomic expectation. By fitting market-implied bucket probabilities to a Gaussian, the Polymarket series provides real-time, high-frequency updates that frequently outpace the Cleveland Fed nowcast in converging to the eventual BLS release, especially in pre-release windows.
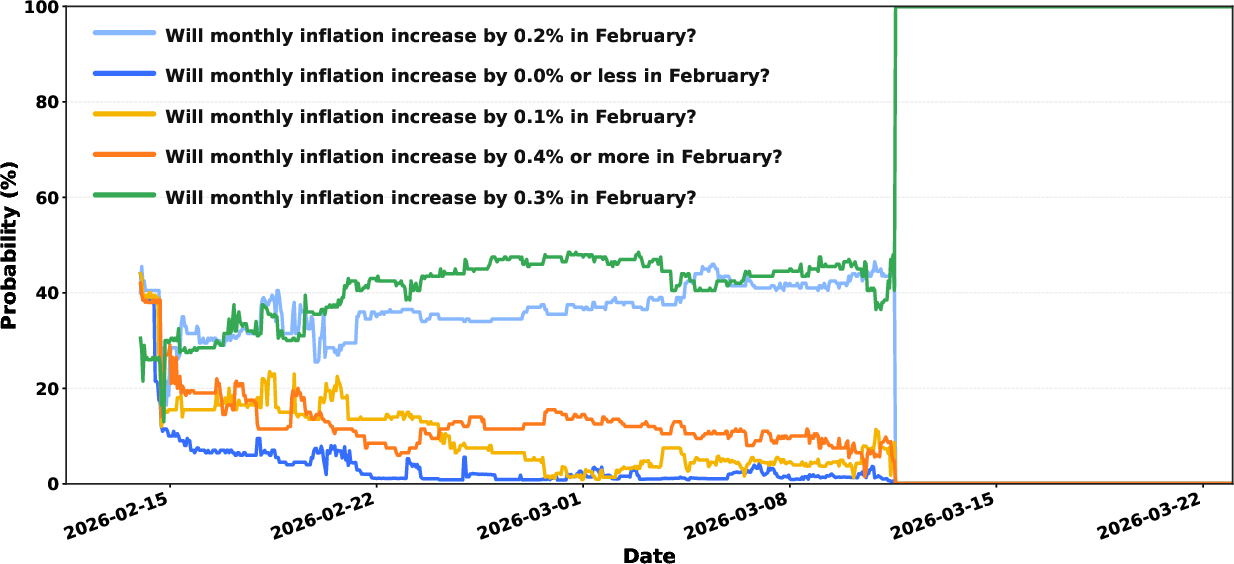
Figure 10: Time-series evolution of market-implied probabilities for discrete CPI outcome buckets illustrates the dynamic collective updating of macro forecasts.
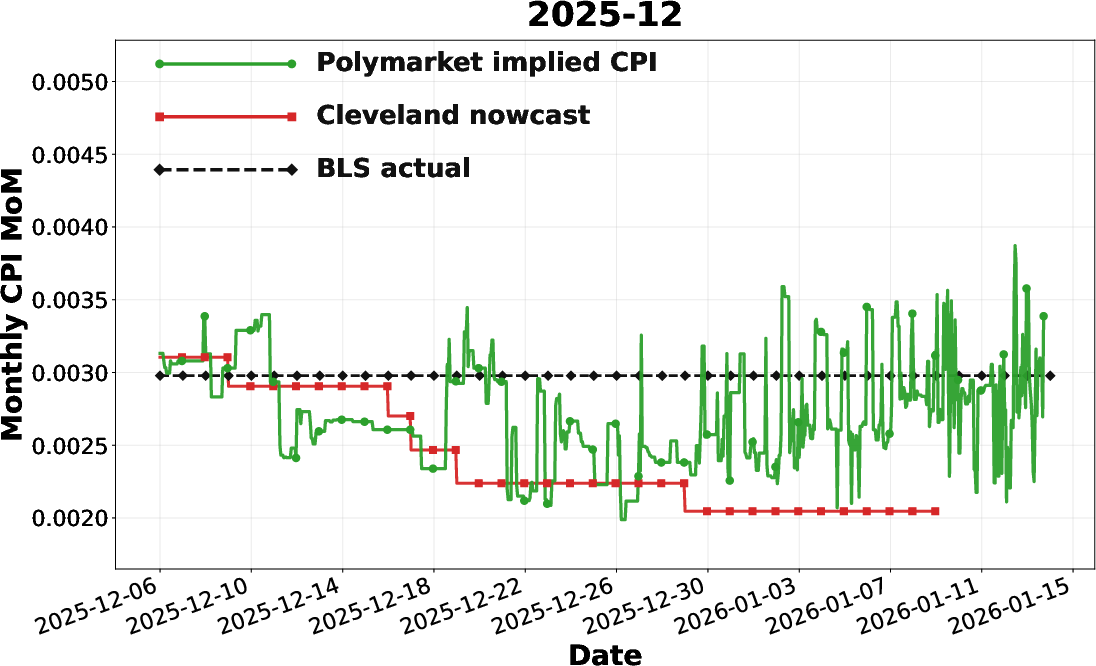
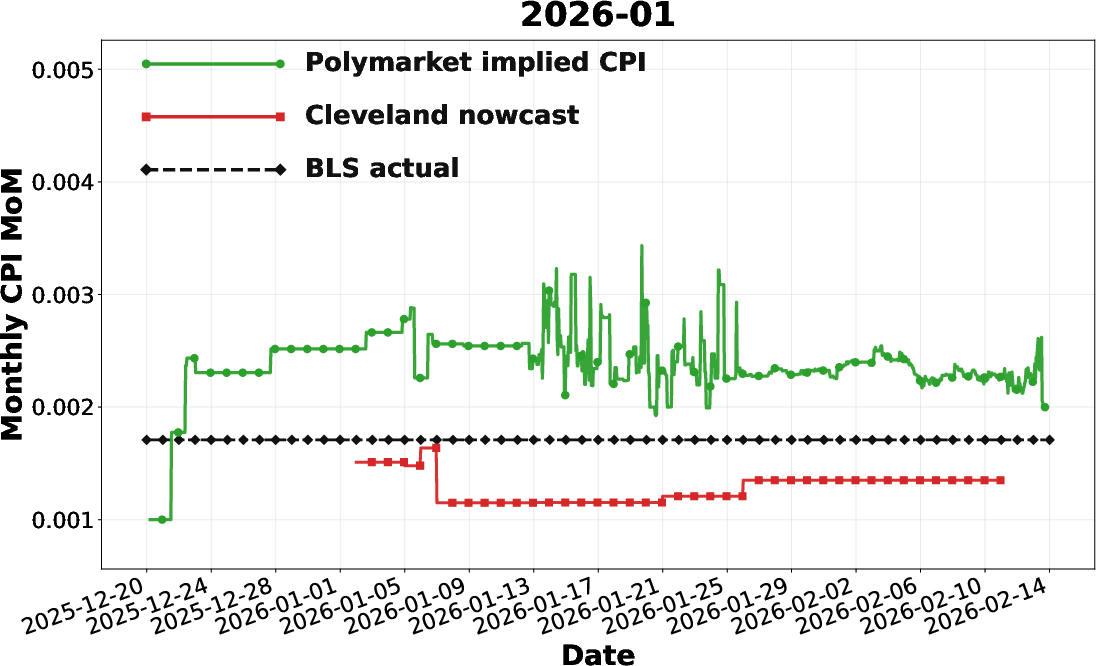
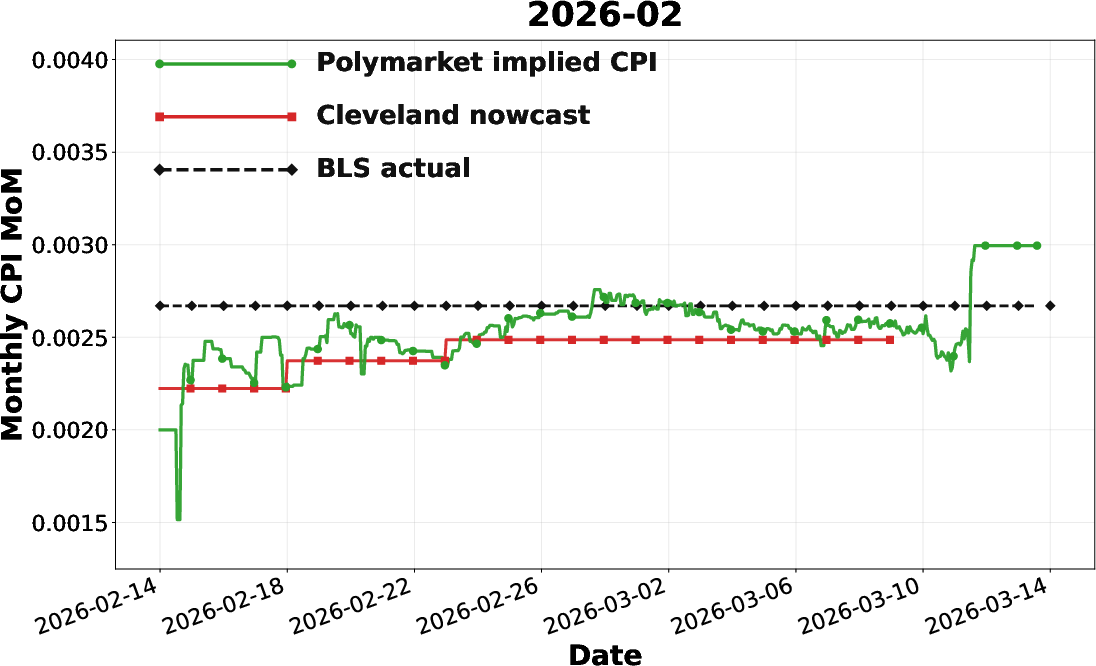
Figure 11: Comparison of Polymarket-implied CPI, Cleveland nowcast, and BLS actual for December 2025, illustrating the market’s early alignment with realized CPI.
Theoretical and Practical Implications
The dataset’s comprehensive, fine-grained structure enables several lines of future theoretical and empirical inquiry. The ability to trace the precise mapping from market creation, through order-book event execution, to oracle and settlement activity enables unambiguous reconstruction of incentives and information flow. This is critical for AI and ML research on mechanism design, modeling agent incentives, developing agent-based simulation frameworks for DeFi and prediction markets, and empirically evaluating aggregation and manipulation hypotheses [saguillo2025unravelling, rahman2025sok]. In practice, researchers and market architects can use this canonical dataset to benchmark market efficiency, participant diversity, response to exogenous shocks, and robustness of settlement schemas in adversarial or disputed regimes.
Conclusion
This work establishes a new standard by delivering the first full-lifecycle, high-resolution public dataset for decentralized prediction markets, systematizing the integration of off-chain, on-chain, and oracle-side data over multiple years of protocol operation (2604.20421). The engineering enables clean, reproducible, and extensible analysis of a rapidly growing class of blockchain-based financial primitives. The dataset’s empirical insights into market structure, fee design, and event settlement, as well as demonstrated downstream applications in sports probability calibration and macroeconomic forecasting, underscore its centrality as a foundation for both academic research and robust market infrastructure development.

