- The paper introduces AdaTracker, which learns an adaptive in-context policy that generalizes across diverse robotic embodiments without retraining.
- It employs an embodiment context encoder with auxiliary objectives to capture robot-specific constraints, ensuring robust visual tracking.
- Empirical results show AdaTracker outperforms SOTA methods with high success rates and rewards in both simulations and real-world deployments.
Adaptive In-Context Policy Learning for Cross-Embodiment Embodied Visual Tracking
Problem Definition and Motivation
Embodied Visual Tracking (EVT) requires agents to maintain the target within their field of view while navigating in complex and dynamic 3D environments. The core challenge arises from significant embodiment-induced distribution shifts: robot platforms vary substantially in camera viewpoint, physical geometry, actuation, and motion constraints. Existing EVT methods typically address this by training and deploying a separate policy for each embodiment, severely hindering scalability and preventing effective cross-embodiment generalization.
This paper introduces AdaTracker, an offline RL-based framework for active visual tracking that learns a single, adaptive in-context policy capable of robust zero-shot generalization across a broad spectrum of robotic platforms (e.g., wheeled robots, quadrupeds, aerial robots), without any retraining or manual recalibration.
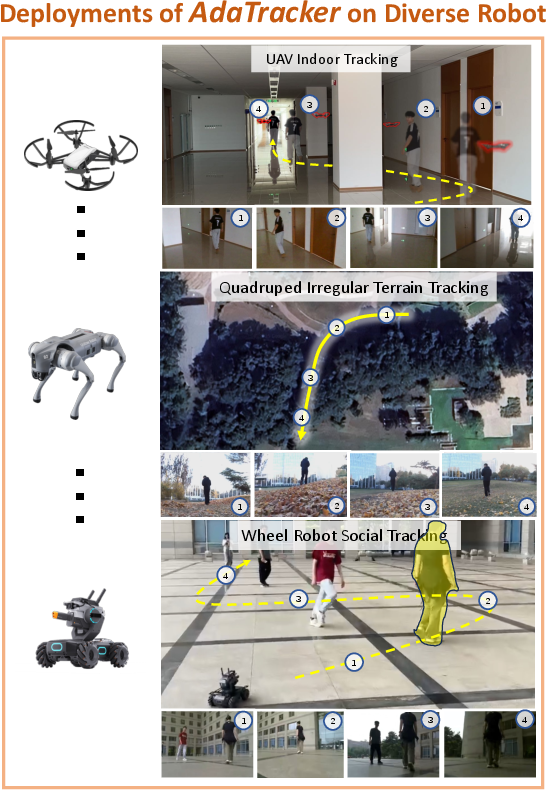
Figure 1: AdaTracker enables a single, unified policy to perform Embodied Visual Tracking (EVT) across heterogeneous robotic platforms with diverse viewpoints and motion dynamics, achieving cross-embodiment generalization and robust real-world tracking without retraining or recalibration.
Core Methodology
The central innovation in AdaTracker is the explicit modeling of embodiment context. AdaTracker incorporates a history-aware Embodiment Context Encoder that summarizes recent perception and action histories into a compact latent vector, capturing key robot-specific constraints (such as camera height and actuation latency). This latent representation is dynamically updated during rollouts and conditions the recurrent policy to allow rapid adaptation to previously unseen embodiments.
The framework consists of two principal components:
- Embodiment Context Encoding:
- Utilizes semantic segmentation masks (from VFM models) and recent action histories to encode perception and control feedback, rendering inputs morphology-invariant.
- Trains with two auxiliary objectives:
- Supervised context identification (predicting camera height and reward to bind the context to physical and performance attributes).
- Self-supervised temporal consistency (regularizing context drift within trajectories for rapid and stable embodiment inference).
- Context-Conditioned Policy Learning:
- The recurrent policy (LSTM-based) receives current perceptual representation and the inferred context latent.
- Policy optimization is performed via Conservative Q-Learning in the Soft Actor-Critic framework on an offline dataset aggregated across diverse embodied rollouts.
The entire network, including the context encoder, is trained end-to-end to maximize generalization to novel embodiments at test time.
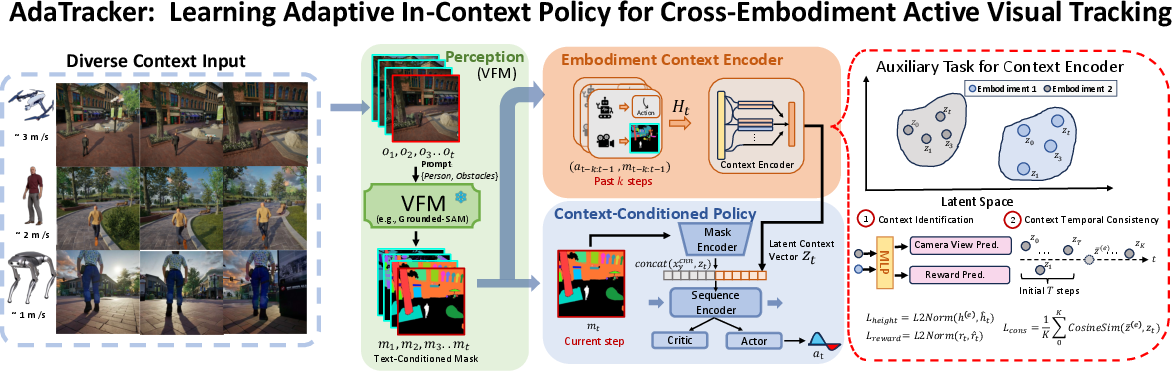
Figure 2: The policy architecture leverages an Embodiment Context Encoder and auxiliary objectives to infer a latent context, conditioning a recurrent policy for adaptive cross-embodiment active tracking.
Empirical Evaluation
Simulation Experiments
AdaTracker is rigorously evaluated on both in-distribution and out-of-distribution embodiments spanning multiple environments. The results show:
- Zero-shot generalization: AdaTracker achieves a mean success rate (SR) of 0.91, mean accumulated reward (AR) of 209, and long episode lengths (EL) over a set of 16 heterogeneous embodiments, significantly outperforming recent SOTA methods including both classical (PID + Video Tracker) and offline RL (Offline EVT, TrackVLA) approaches.
- Robustness to extreme embodiment shift: Unlike TrackVLA and Offline EVT, which degrade in either viewpoint or dynamics robustness, AdaTracker maintains SR ≥ 0.90 and high AR even under extreme camera heights and high-speed configurations.
- Ablation results: Removal of context identification, temporal consistency, or the context encoder leads to a substantial drop in tracking performance, confirming the necessity of these components for stable cross-embodiment adaptation.
Real-World Transfer
Locked policies are deployed without any retraining on three physical robots: wheeled, quadruped, and aerial platforms. AdaTracker maintains consistently high mean rewards (MR up to 0.86) and success rates (SR = 1.0 on ground robots; 0.8 on aerial), while the previous best method fails drastically, especially on more challenging embodiments (MR for drone: AdaTracker 0.83 vs Offline EVT 0.42, and SR: 0.8 vs 0.0).
Theoretical and Practical Implications
AdaTracker demonstrates that explicit, context-driven in-policy adaptation is critical for scalable embodied intelligence. Embodiment mismatches, previously requiring separate policies and extensive retraining, can be mitigated by dynamically inferred, history-aware latent conditioning. This approach scales gracefully without needing manual parameterization, descriptor engineering, or large-scale sim2real domain randomization.
The mid-level action abstraction (velocity command interface) further enhances portability, allowing the same learned policy to be directly applied to diverse robotic platforms with their own low-level controllers.
In practice, AdaTracker markedly reduces engineering overhead, data collection costs, and deployment complexity for cross-platform tracking systems, directly transferring from large-scale synthetic datasets to real-world deployment.
Relation to Prior Work and Open Directions
AdaTracker advances the state of the art over previous cross-embodiment transfer frameworks that either require explicit embodiment descriptors [10611477], rely on system identification [lee2020context], or leverage in-context RL but lack explicit task conditioning or goal alignment [grigsby2024amago, 11128272].
The findings support a broader view that goal-oriented, auxiliary-task-driven representation learning is essential for closed-loop control robustness in the presence of distributional shift. This connects AdaTracker conceptually to goal-conditioned RL [liu2022goal] and prompts future work in multi-task, context-conditioned embodied policies.
Future directions include extending the approach to unify policies across manipulation and navigation, leveraging the mid-level interface, and scaling up to even more diverse robots and embodied tasks using web-scale pretraining paradigms.
Conclusion
AdaTracker establishes that adaptive in-context policy learning with explicit, auxiliary-task-driven embodiment inference enables a single tracking policy to achieve robust, zero-shot generalization across morphologically and dynamically diverse robotic platforms. This architecture efficiently bridges the embodiment gap both in simulation and in real-world applications, paving the way for broadly generalizable vision-based control systems in practical robotics (2604.20305).

