- The paper introduces a novel, dual-stage feedforward pipeline that synchronizes 2D sketches with 3D Gaussian rendering for photorealistic head modeling.
- It leverages transformer-based feature extraction and StyleGAN2 modulation to ensure precise geometry, appearance, and real-time editing with high fidelity.
- The approach achieves superior FID/KID scores and unmatched editing performance, offering a scalable, interactive solution for 3D facial synthesis.
Real-Time 3D Sketch-Driven Face Editing and Generation with Gaussian Splatting
Introduction and Motivation
SketchFaceGS addresses crucial limitations in 3D facial head synthesis by introducing the first real-time, sketch-driven system capable of both generating and interactively editing photorealistic 3D Gaussian head models. The framework builds on 3D Gaussian Splatting (3DGS), which achieves high-quality real-time rendering but historically lacks intuitive and fine-grained control for interactive design, especially from sparse and ambiguous 2D sketches. This work augments 3DGS techniques with a feed-forward, optimization-free pipeline leveraging modern generative priors and novel feature fusion strategies, bridging the conceptual gap between 2D designer input and dynamically editable 3D models.
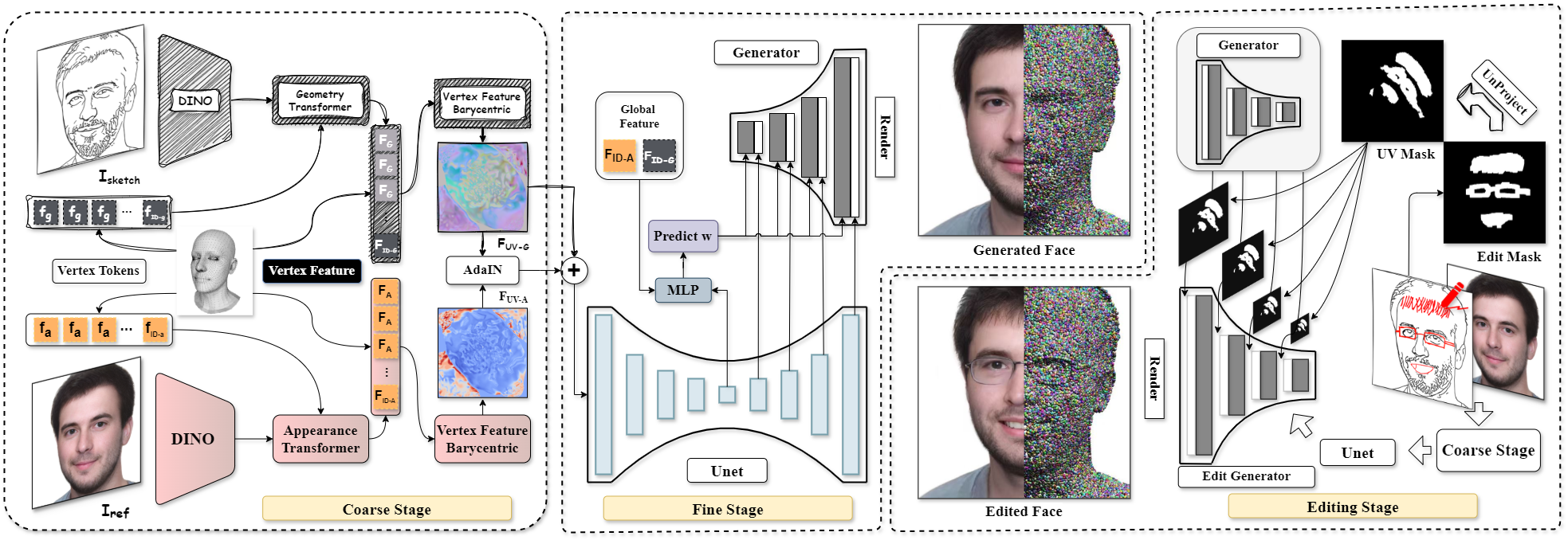
Figure 1: Overview of the SketchFaceGS Framework, illustrating the dual-pipeline for generation from sketch/reference and for real-time, precise, view-consistent editing using UV Mask Fusion and layer-wise feature fusion.
Methodology
Coarse-to-Fine Feed-Forward Generation
The SketchFaceGS framework decomposes generation into two synergistic stages:
- Coarse Stage: Independent Transformer branches extract geometry from the input sketch and appearance from a reference image, producing geometry-consistent UV feature maps. AdaIN-based alignment resolves identity and structure conflicts between sketch and reference modalities, followed by feature-level fusion.
- Fine Stage: A U-Net-based UV feature enhancement module predicts multi-scale modulation parameters for a pre-trained StyleGAN2-based generator (from GGHead). These parameters, including a global identity vector and multi-resolution spatial features, condition synthesis within the StyleGAN backbone, directly producing a UV map encoding Gaussian attributes for 3DGS rendering with photorealistic detail.
This architecture leverages 3D generative priors to map abstract, ambiguous 2D sketches into dense, physically consistent and realistic 3D models in a feed-forward pass, eliminating the need for instance-level optimization.

Figure 2: Photorealistic 3D head synthesis from hand-drawn sketch and reference image (top), with support for detailed local editing (bottom).
Sketch-Driven Real-Time Editing
Interactive editing is achieved by UV Mask Fusion and layer-wise feature fusion:
Training and Losses
A three-stage training strategy is adopted: coarse-stage multi-view learning, fine-stage single-view learning, and an explicit editing objective. Losses include pixelwise L1, perceptual, LPIPS, color-consistency, and adversarial losses to optimize for geometric consistency, photorealism, and local/global identity preservation.
Experimental Evaluation
Quantitative and Qualitative Results
SketchFaceGS establishes new benchmarks in both generation and editing of 3D head models given hand-drawn sketches:
- Generation: Outperforms S3D, SketchFaceNeRF, and Nano-LAM on FID and KID. Numerical results indicate superior photorealism and sketch faithfulness (FID 92.65; KID 4.00), with high fidelity to geometry and appearance under challenging sketch/reference discrepancies.
- Editing: Demonstrates high-quality, real-time, view-consistent editing with substantially lower latency and higher frame rates (0.3s per edit; 243FPS render), eclipsing state-of-the-art approaches that are optimization-based or require costly 2D-to-3D pipelines.

Figure 4: Qualitative comparison for sketch-to-3D generation against S3D, Nano-LAM, SketchFaceNeRF, and SketchFaceGS, illustrating superior geometric and appearance fidelity.

Figure 5: Qualitative comparison for sketch-driven 3D editing. Only SketchFaceGS achieves real-time, artifact-free, sketch-faithful edits across multiple viewpoints.
Quantitatively, SketchFaceGS yields the lowest FID, KID, and highest PSNR/SSIM on unedited regions, indicating both overall generation quality and minimal identity drift in non-edited areas.
Ablation Studies
Ablations on the generation pipeline highlight critical components: removal of the UV feature enhancement or AdaIN alignment leads to oversmoothed results and identity artifacts, while dropping the global identity vectors or using a naive CNN for appearance extraction degrades both photorealism and appearance transfer.

Figure 6: Generation pipeline ablation—full model achieves optimal realism, detail, and identity consistency.
Ablations of editing strategies show that direct 3D Gaussian compositing causes seams and loss of identity, and naive full-head regeneration loses context. Only layer-wise feature fusion provides seamless, structurally and chromatically stable edits under repeated or fine-grained manipulations.

Figure 7: Editing module ablation—layer-wise feature fusion (e) yields the most consistent and artifact-free editing results.
Implications and Future Directions
This work substantially extends intuitive, user-driven 3D head modeling and editing, rendering photorealistic, high-fidelity avatars from sketches with real-time feedback. Practically, this establishes a new paradigm for interactive avatar creation, content design, and digital asset generation, lowering the barrier for non-specialists and enabling robust, iterative workflows.
Theoretically, the unified feed-forward architecture indicates the viability of bridging sparse human inputs and high-dimensional generative priors for dense 3D modeling. The novel UV Mask Fusion and feature space fusion strategies may generalize to other conditional generative modeling tasks, and to multi-modal interactive systems beyond head avatars.
Limitations and future work include sensitivity to extreme out-of-distribution sketches or accessories not captured by the generative prior, and slight identity shifts in the presence of significant geometric/appearance conflict. Extensions to dynamic editing for facial animation, improved identity consistency losses, and augmenting priors for rare attributes are natural next steps.
Conclusion
SketchFaceGS delivers the first real-time, optimization-free framework for sketch-driven generation and editing of photorealistic 3D Gaussian heads. By combining a coarse-to-fine dual-Transformer architecture, a modulation-based generative prior, and layer-wise UV Mask Fusion, it achieves high-fidelity, interactive, artist-friendly 3D modeling with superior quantitative and qualitative performance across benchmarks. This framework is a key advancement in controllable, efficient, and robust human face synthesis and editing in graphics and vision.
