- The paper presents a novel framework achieving zero‐shot wide‐baseline matching for event cameras without target-domain adaptation.
- It employs multi-timescale voxel encoding combined with a Temporal Aggregation Transformer to fuse fine spatial detail with robust motion handling.
- Experimental results show a 37.7% improvement in matching performance and enhanced 3D reconstructions for event-based vision systems.
Match-Any-Events: Zero-Shot, Motion-Robust Feature Matching for Event Cameras
Event cameras provide high temporal resolution and robustness to challenging illumination and fast motion, yet struggle with wide-baseline matching, especially under zero-shot settings. Unlike frame-based image matching—where deep learning methods have enabled robust correspondence across dramatic viewpoint changes—event-based matching has been hampered by non-uniform motion profiles, hand-crafted event encodings, a lack of diverse datasets, and prohibitively expensive attention mechanisms. This work introduces the first model that achieves generalizable, zero-shot wide-baseline correspondence for event cameras, without requiring target-domain adaptation or fine-tuning.
Methodology
The proposed pipeline integrates multi-timescale event encoding, efficient spatiotemporal feature aggregation, sparsity-aware token selection, and progressive matching. The core architectural innovations and training datasets are summarized below.
Multi-Timescale Event Representation
Instead of 2D event frames or time surfaces, the event stream is converted into a voxel representation with logarithmic temporal binning. This preserves fine temporal information and enables scalable tokenization for transformer architectures. Each event stream is divided into multiple bins across time, yielding rich spatiotemporal tokens that retain dynamic texture and motion data.
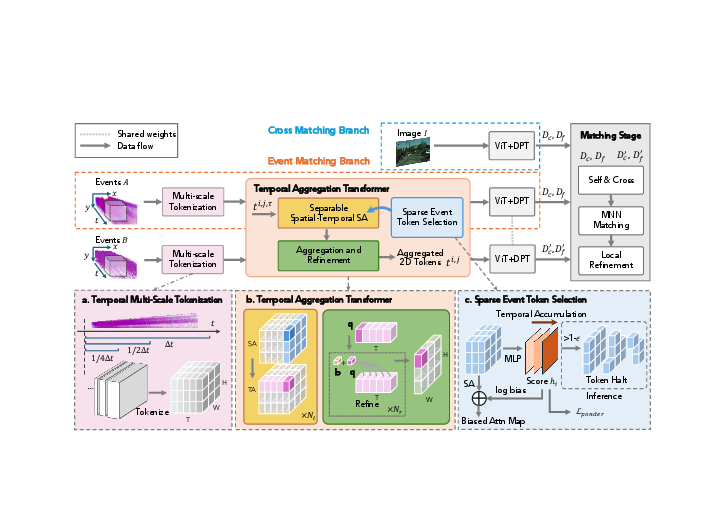
Figure 1: The event matching pipeline: event slices are binned to multi-scale voxels, processed by separable temporal aggregation transformer and sparsity-aware token selection, then iteratively matched with ViT+DPT features.
The Temporal Aggregation Transformer (TAg) module decomposes attention into separable spatial and temporal components. Spatial attention operates within each temporal bin, while temporal attention aggregates across bins for each spatial location. This reduces attention complexity from O((THW)2) to O(T(HW)2+HWT2). Aggregation is performed via querying features from the finest temporal resolution and fusing keys from coarser scales. This enables both sharp spatial details and robustness to varying motion speeds.
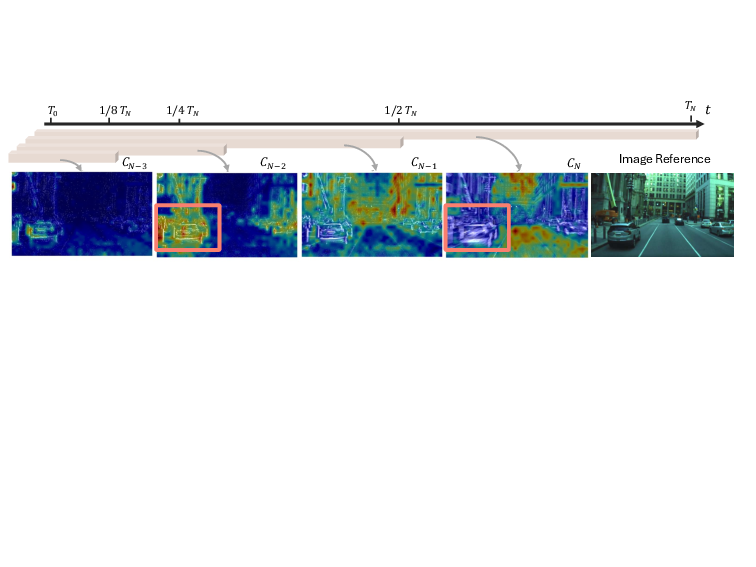
Figure 2: Visualization of temporal attention weights; the network attends to texture-rich regions at short temporal scales and low-texture regions at longer scales.
Sparsity-Aware Event Token Selection (SETS)
Given the sparsity of event data, the SETS module adaptively prunes redundant tokens by learning halting scores at each temporal step. These scores modulate the spatial attention map, suppressing uninformative regions and reducing computational cost. The ponder loss, which penalizes unnecessary processing, enforces efficiency without sacrificing predictive accuracy.

Figure 3: Visualization of halted tokens at each temporal step; spatially blurry regions are increasingly pruned as temporal information accumulates.
Iterative Matching and Loss Functions
Matching proceeds in a coarse-to-fine manner: coarse features are alternately cross- and self-attended, then refined using mutual nearest neighbors (MNN). The loss combines coarse/fine cross-entropy, L2 refinement for subpixel accuracy, and the ponder loss from SETS.
Datasets and Wide-Baseline Supervision
Two new datasets are introduced:
- E-MegaDepth: Synthetic event streams generated from the MegaDepth dataset with diverse viewpoint changes and motions, comprising ∼3M pairs for training.
- ECM (Event Cross Matching): Real hetero-stereo event-image dataset with synchronized RGB and event streams, annotated using bundle-adjusted poses and dense depth from the latest foundation models.
These datasets provide large-scale supervision for wide-baseline matching unavailable to prior works.
Experimental Results
Comprehensive evaluation across ECM, M3ED, and EDS datasets demonstrates state-of-the-art performance:
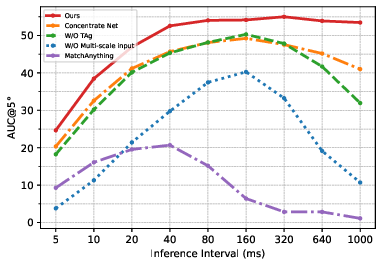
Figure 5: Match-Any-Events accurately matches across wide baselines between images and events.
Structure-from-Motion and 3D Reconstruction
Using event-only data, the model enables robust incremental SfM pipelines, delivering denser and more accurate reconstructions and camera poses compared to previous event-based methods.


Figure 6: Structure-from-Motion with event matching; Match-Any-Events (right) yields more consistent camera poses and denser point clouds than SuperEvent (left).
Discussion and Implications
The work addresses persistent bottlenecks in event-camera matching: scalable architectural design, synthetic and real supervision for wide-baseline correspondence, and efficiency under sparse, noisy data. The zero-shot generalization marks a significant step toward foundation models for event-based multimodal matching, critical for visual SLAM, loop closure, and cross-modal sensor fusion. The presented approach sets a new standard for event matching, both theoretically in terms of model design and practically in supporting robust, real-world deployments.
Figure 2: Temporal attention adapts dynamically across spatial and temporal scales, enabling robustness to varying motion and texture.
Figure 3: SETS efficiently prunes tokens over time, focusing computation on informative regions.
Future Directions
The generalizable, zero-shot paradigm for wide-baseline event matching opens several avenues:
- Extending foundation models for event cameras to semantic correspondence and object recognition tasks
- Scaling up synthetic and real-world data generation for more diverse scenarios (e.g., outdoor, industrial environments)
- Hardware-efficient transformer deployments via further token selection and pruning
- Deep integration of event and frame modalities for unified, multimodal SLAM and perception
Conclusion
Match-Any-Events introduces the first scalable, generalizable event matching framework with robust zero-shot performance across wide baselines and modalities. The combination of efficient spatiotemporal transformers, adaptive token selection, and broad supervision achieves superior matching, pose estimation, and 3D reconstruction. The work has significant implications for multimodal sensor fusion, real-time robotics, and foundational event-based vision models in AI.

