- The paper demonstrates that randomly initialized networks can learn meaningful representations through a minimalist peer-to-peer self-distillation framework.
- The methodology isolates SSL dynamics by randomly assigning teacher and student roles, using either MSE or a salient loss to yield significant accuracy gains on CIFAR-10.
- The study highlights that optimal learning hinges on careful tuning of learning rates and model capacity, challenging traditional SSL architectural norms.
Peer-to-Peer Self-Distillation in Randomly Initialized Networks
Introduction and Motivation
The paper "Randomly Initialized Networks Can Learn from Peer-to-Peer Consensus" (2604.18390) investigates the role of self-distillation within SSL by isolating its effects and minimizing architectural components traditionally deemed essential. Standard self-distilled SSL frameworks—such as BYOL, DINO, and SimSiam—employ mechanisms including predictor/projector layers, loss asymmetries, and view augmentations to stabilize training and enhance representation quality. These practices, though empirically successful, lack rigorous theoretical justification and obscurate the contribution of core self-distillation dynamics.
This work systematically removes typical SSL constructs. Peer networks, randomly initialized and devoid of standard pretext tasks or architectural asymmetries, are trained in a minimalist setup: each batch randomly assigns the student and teacher roles among peers, and learning proceeds strictly via comparison of embeddings. The aim is to understand whether peer-to-peer self-distillation—without augmentation, predictor heads, or EMA teachers—can generate meaningful representations beneficial for downstream tasks.
Methodological Framework
The proposed methodology, named DINOHerd, involves a group of N untrained neural network peers. For each batch, a student and T teachers are selected at random. Each receives an identical input view. The student’s embedding is updated to minimize divergence from the mean teacher output, with gradients propagated exclusively through the student.
A central aspect is the absence of architectural asymmetry: unlike BYOL or DINO, both teacher and student have identical architectures, and the teacher's weights remain static during each batch via stop-gradient.
Loss functions explored include MSE and a custom salient loss, which isolates and penalizes only the most divergent embedding dimension per sample. Stability and non-collapse of representations are ensured by the batch-wise random assignment of teacher/student roles and careful tuning of learning rates.
Numerical Results and Learning Dynamics
Quantitative evaluation focuses on CIFAR-10 classification. Using 16 peers trained for 10 epochs, learned representations show improvements relative to random baselines across KNN (+4.36%), linear probe (+26.46%), and MLP probe (+33.55%) metrics. These gains manifest despite complete absence of supervised labels or contrastive view augmentation.
Group dynamics are visualized by tracking the linear probe accuracy of each peer during training. Representations improve consistently for all networks, stabilizing after ~500 batches. All networks benefit, even without explicit class-level supervision or negative pairs.
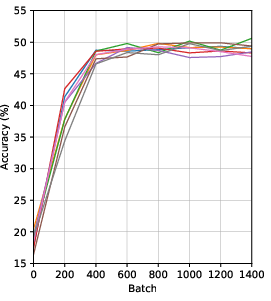
Figure 1: Linear probe accuracy trajectories for 8 peers, demonstrating uniform improvement from random initializations.
Hyperparameter Sensitivity and Ablation Studies
Peer and Teacher Count
Increasing the number of peers slows convergence but does not prevent eventual attainment of similar downstream accuracy. Varying teacher count shows negligible impact; single or multiple teachers yield comparable results.
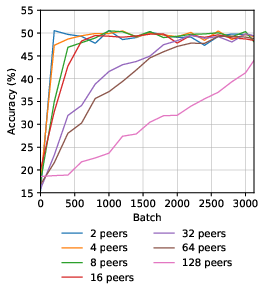
Figure 2: Effect of peer count variation on linear probe accuracy.
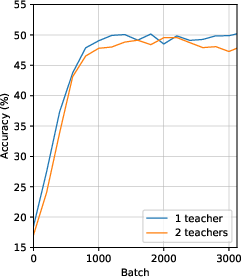
Figure 3: Linear probe accuracy as a function of teacher count.
Aggregating multiple peer outputs (ensemble) induces modest gains in classification accuracy, implying diversity in learned representations across peers. The benefit plateaus with additional peers, indicating diminishing returns.
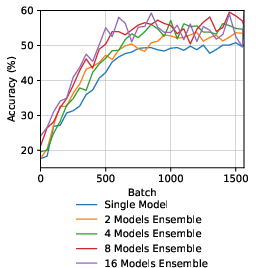
Figure 4: Downstream probe accuracy improves with ensemble of peer outputs but saturates quickly.
Architecture and Loss Function
Smaller architectures learn more discriminative features than deeper ones within this framework. The salient loss offers no notable advantage over MSE; representation alignment does not rely on abrupt changes in latent space.
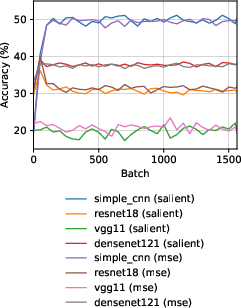
Figure 5: Linear probe accuracy with varying architecture and loss function, highlighting superior performance in smaller CNNs.
Learning Rate Sensitivity
Optimal representation learning occurs at very low learning rates (e.g., 1e−8). Higher rates produce instability and degraded representation quality.
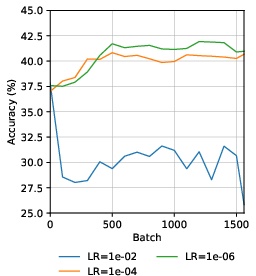
Figure 6: KNN accuracy with varying learning rate, showing rapid decline as rates increase.
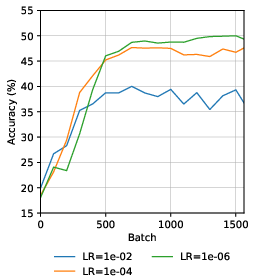
Figure 7: Linear probe accuracy under different learning rates, confirming sensitivity and the necessity for gradual updates.
Analysis of Learned Representations
Comparative analysis of cosine distances between embeddings from random and trained networks reveals a global expansion of representation space. This expansion is especially pronounced among initially close samples. Such emergent behavior may partially explain the success of non-contrastive SSL methods in avoiding representational collapse without explicit negative samples.
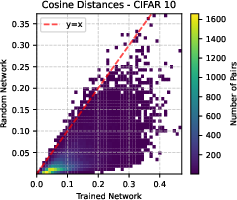
Figure 8: Heatmap of cosine distances between CIFAR-10 embeddings pre- and post-training, indicating increased inter-sample separation.
Practical and Theoretical Implications
The presented findings directly challenge the presumed necessity of architectural and training heuristics in SSL. Meaningful representations emerge from pure peer-to-peer consensus among randomly initialized networks, contingent primarily on hyperparameter selection (notably learning rate) and model capacity.
Practically, this minimalistic approach heralds potential for extremely lightweight, label-free representation learning setups with reduced engineering complexity. The development of swarm-like representation ensembles could improve robustness and coverage in downstream applications.
Theoretically, the observed expansion and separation in embedding space under consensus learning demands further investigation. The mechanism appears to induce implicit regularization and avoids collapse without any explicit coding rate or contrastive constraints.
Future Directions
Key open questions include: (i) the precise nature of expansion behavior, (ii) the transferability of learned embeddings to more complex domains, and (iii) theoretical modeling of peer-to-peer alignment and its relationship to semantic congruence. Extending to larger-scale datasets and architectures is a primary avenue for research, as is the integration with semi-supervised or multi-modal regimes.
Conclusion
This paper demonstrates that randomly initialized networks, trained only by peer-to-peer consensus, learn representations sufficient for non-trivial downstream task performance. The representation quality scales with careful adjustment of learning rates and simple convolutional architectures. The minimalism of this self-distillation setup opens new questions on the theoretical foundations of SSL and the role of emergent expansion in representation space. Further analysis and generalization of these insights may inform future developments in efficient representation learning, collective model training, and ensemble learning paradigms.