- The paper demonstrates that multimodal LLMs perceive numeric content with over 99% accuracy but experience significant multiplication failures as arithmetic load increases.
- It introduces an 'arithmetic load' metric—calculated as the product of digit count and non-zero digit count—that strongly predicts computational performance.
- Using forced-completion loss probes and LoRA adapters, the study reveals distinct internal arithmetic strategies sensitive to operand representation and modality.
Multiplication Competence and Heuristic Preferences in Multimodal LLMs
Controlled Benchmark Design and Scope
The paper introduces a systematic evaluation of multimodal LLMs' arithmetic performance with an emphasis on multiplication across text, image, and audio inputs (2604.18203). Existing arithmetic benchmarks lack factorial pairing across modalities, thereby confounding genuine computational limits with perceptual differences. To address this, the authors construct a reproducible benchmark varying operand digit length, non-zero digit count (digit sparsity), numerical versus alphabetic representation, and input modality, with each instance paired across modalities.
A central innovation is the definition of "arithmetic load" C, calculated as the product of total digit count and total non-zero digit count in both operands. This scalar is mechanistically motivated as a proxy for operation count and correlates strongly with empirical accuracy, offering a compact summary of computational burden that is agnostic to surface representation.
Empirical Trends in Multimodal Computation
Evaluations reveal that LLMs retain near-perfect (>99%) accuracy in perceiving numerical content across modalities, yet fail systematically in exact multiplication as arithmetic load increases. Paired experiments with Gemini 2.5 Flash, Qwen3-VL (30B/235B), GPT-4o/5.4, and xAI Grok demonstrate a sharp monotonic decline in multiplication accuracy for high C: performance often degrades to nearly zero past C=100–$360$, depending on model and modality. Logistic regression fits show arithmetic load is consistently predictive of correctness, with R2 above 0.5 for most model-modality pairs.
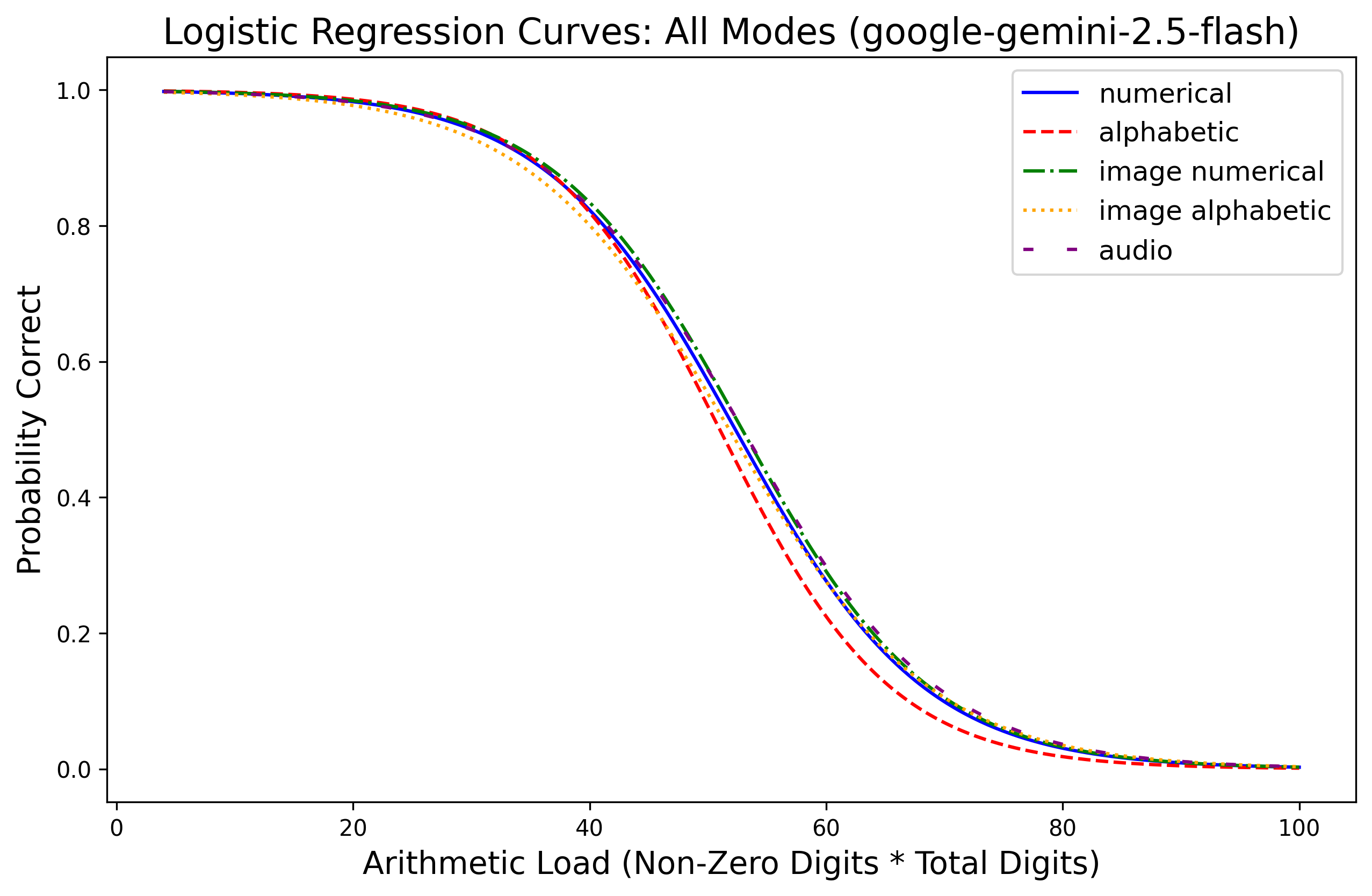
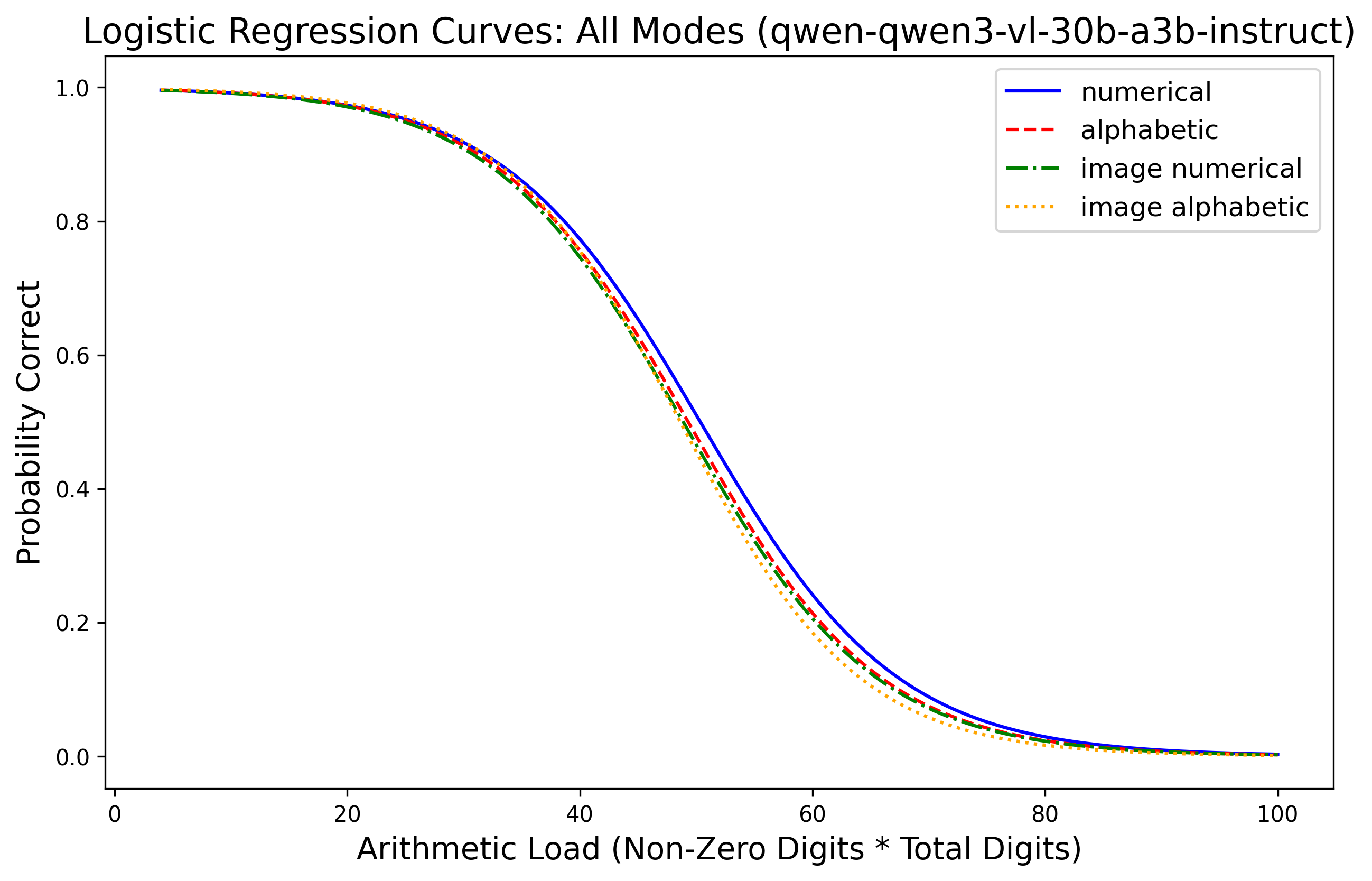
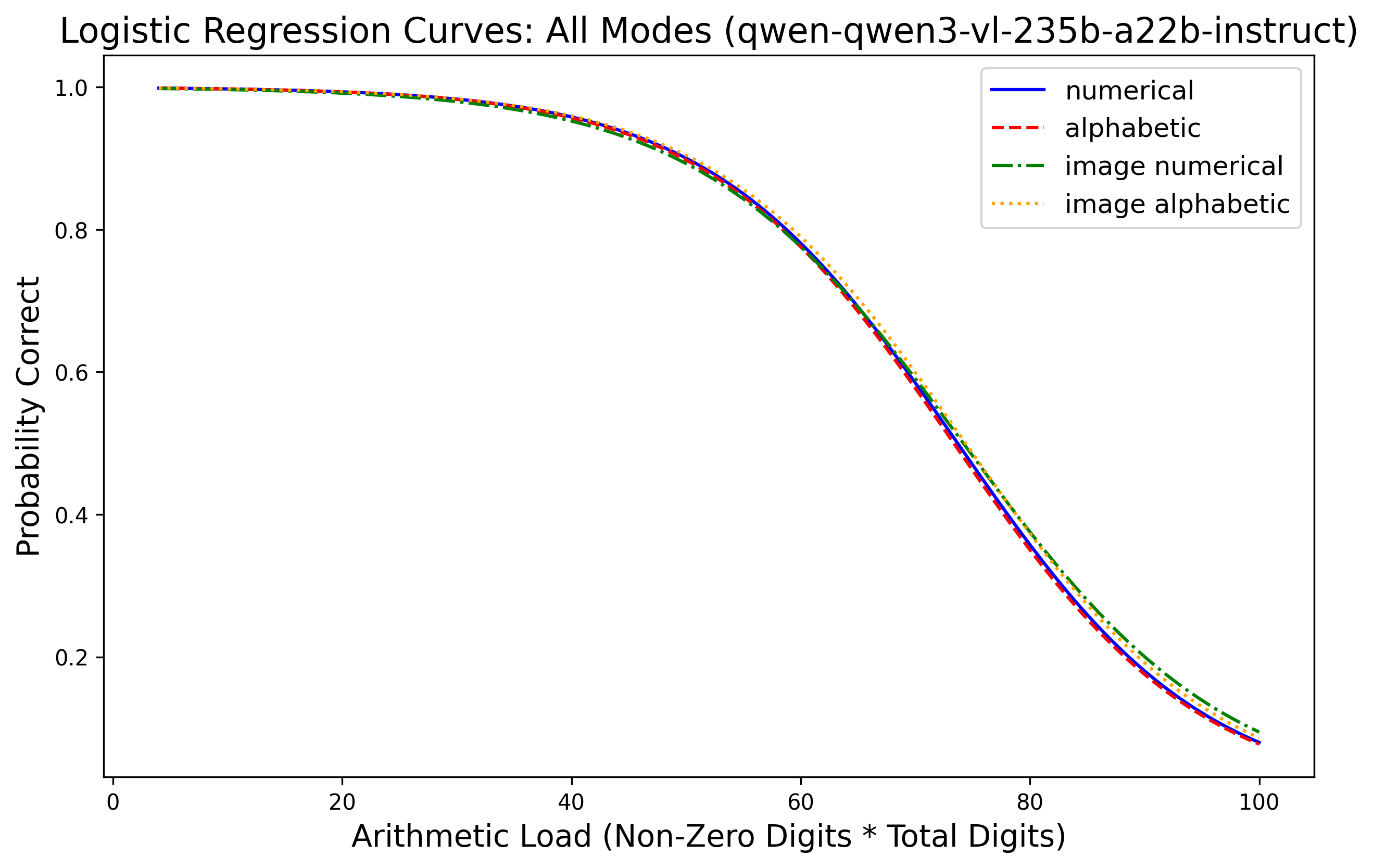
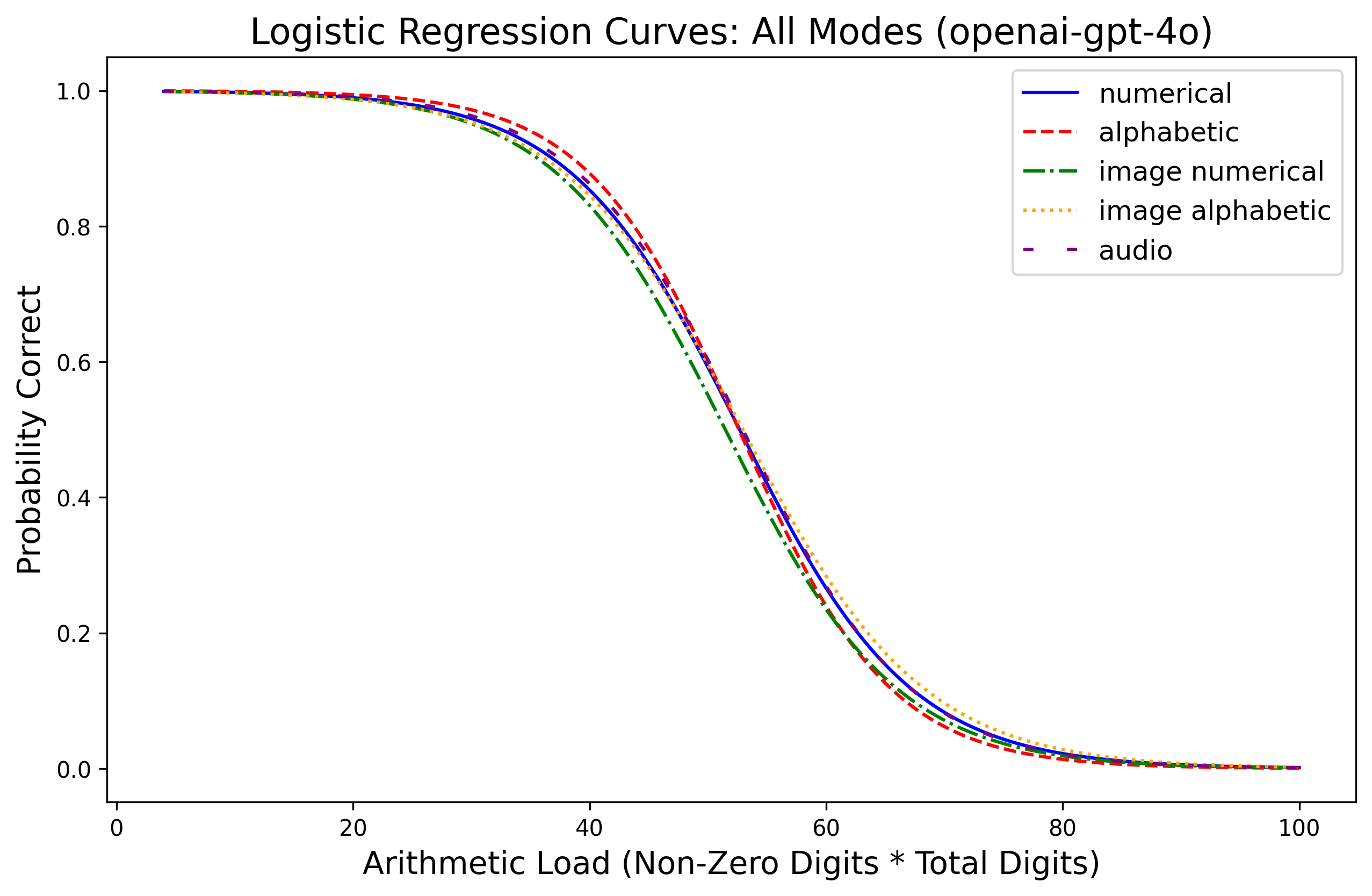
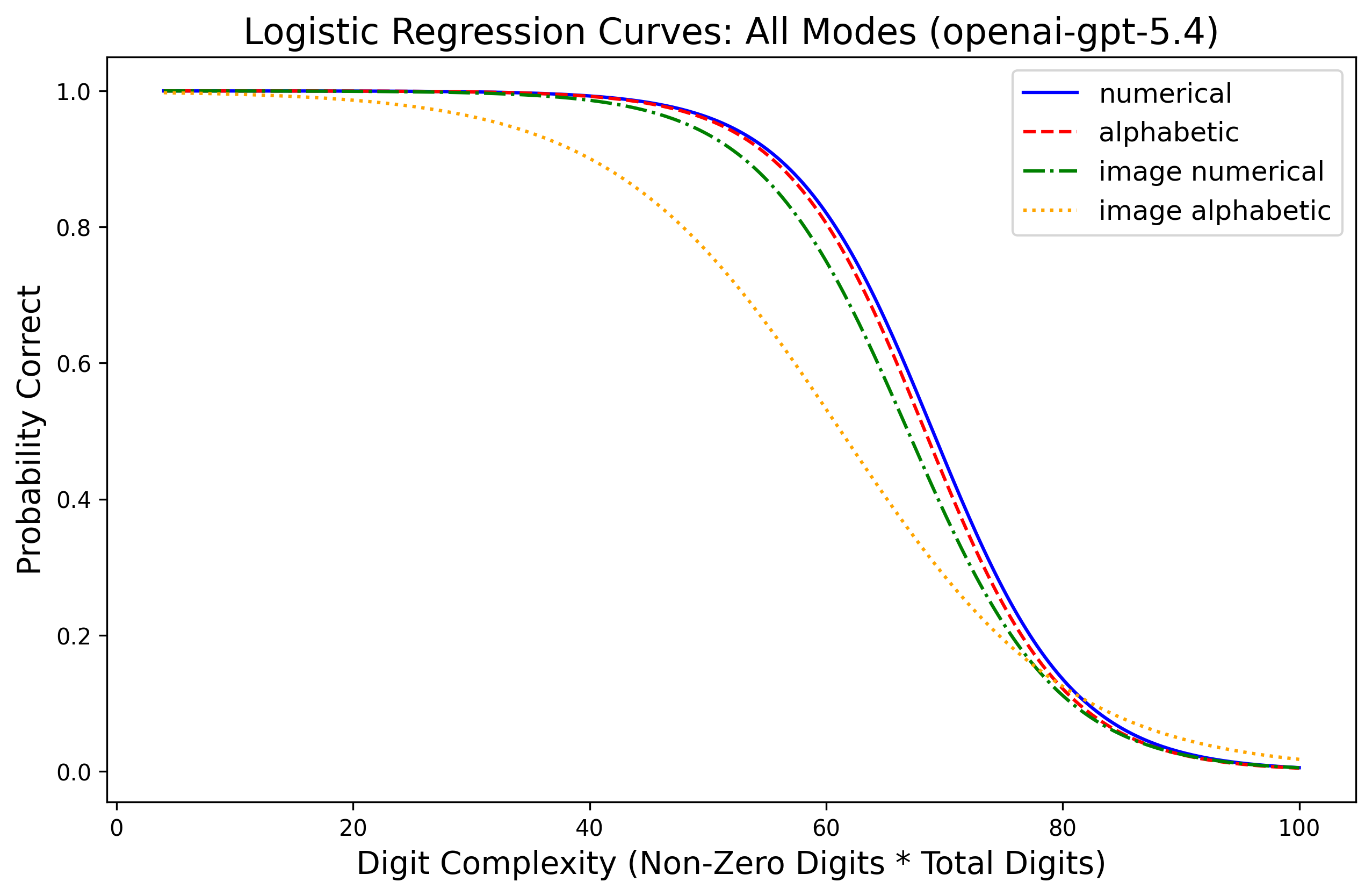
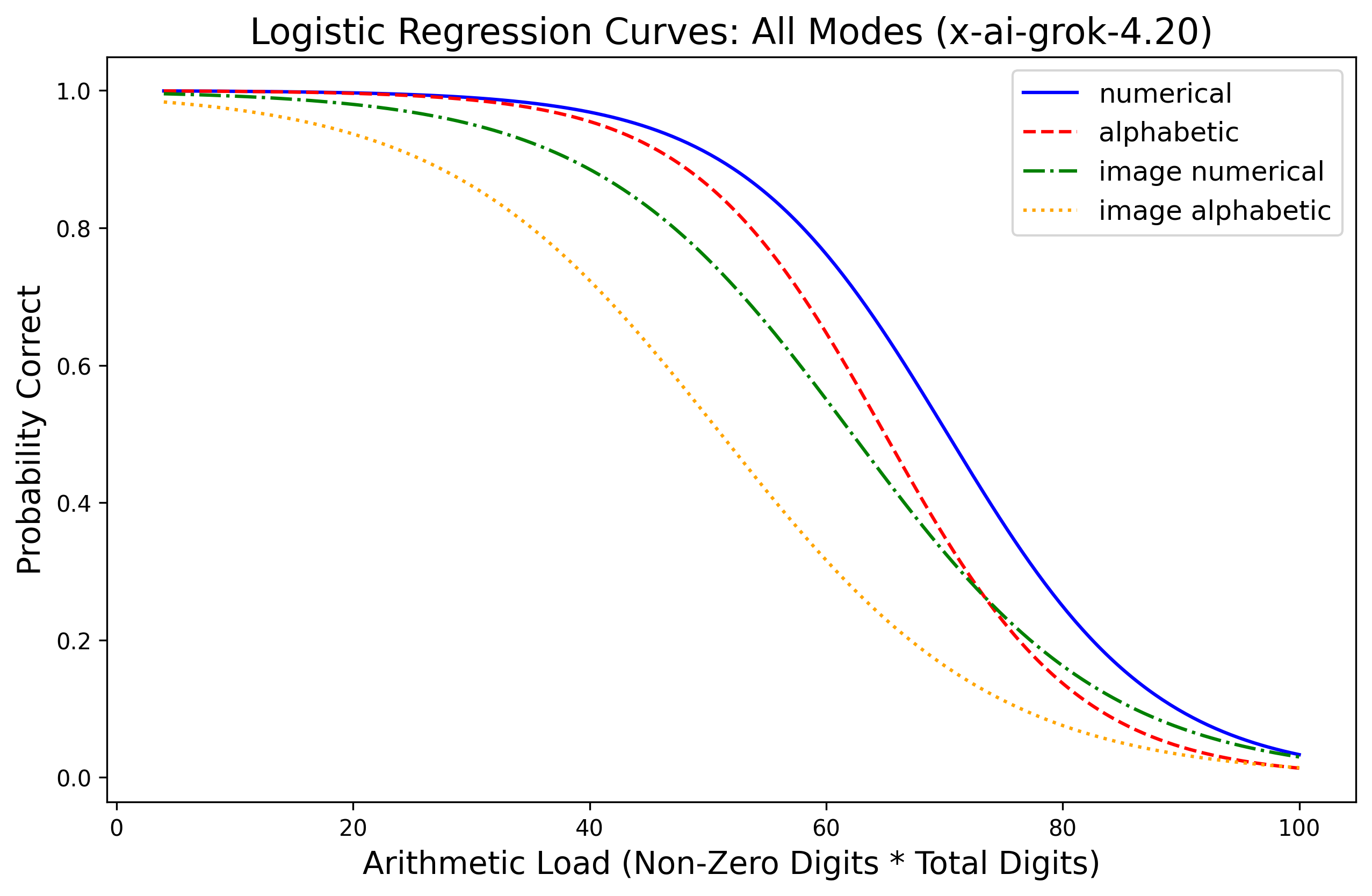
Figure 1: Probability of correct answer as a function of arithmetic load C (total digits × non-zero digits) across input modalities for Gemini 2.5 Flash, Qwen3-VL, GPT-series, and Grok.
Modality effects are secondary: text input yields the highest baseline, while image and audio incur moderate penalties, particularly for alphabetic representations. Importantly, degradation patterns are governed primarily by arithmetic load rather than perceptual factors, as models achieve >99% accuracy in matched perception checks even at maximal C. Thus, computational limits—not input recognition—underlie arithmetic failures.
Internal Arithmetic Heuristics and Strategy Probing
To dissect models' procedural tendencies, the paper develops a forced-completion loss probe. This methodology evaluates token-level cross-entropy under heuristic-specific continuation prefixes corresponding to three canonical multiplication strategies: columnar (OT, long multiplication), distributive decomposition (DD), and rounding-compensation (RC). For both Qwen3-VL-30B and 235B, DD is favored in text and image; RC and OT show lower compatibility except when operand cues are adversarially shifted.
Loss-based fingerprinting shows that shifting template style increases readout noise but does not collapse heuristic margins. Contrastive step probes confirm deep procedural grounding, as models robustly prefer correct intermediate steps over plausible incorrect alternatives, with preference rates near 100% and significant loss gaps for target-aligned items.
Adapter-based behavioral nudges are performed by training LoRA (Hu et al., 2021) heuristic adapters. Inducing strategy-specific reasoning via LoRA produces mostly degraded accuracy, indicating the base model's internal router is better optimized for arithmetic than any single heuristic. Pairwise cosine similarity between adapter effective updates demonstrates near-orthogonality, implying distinct parameter subspaces for each procedure (e.g., >0 between OT and DD in 30B, >1 in 235B).
Practical and Theoretical Implications
The findings establish strong constraints on the deployment of multimodal LLMs in agentic workflows. While perception is robust across input channels, exact multiplication remains sensitive to digit structure and operation count, regardless of input form. Models exhibit procedural preferences that are modulated by operand cues and channel, suggesting internally routed arithmetic strategies over a brittle superposition of heuristics.
From a theoretical perspective, arithmetic load provides a concise axis for evaluating LLM computational competence, transcending modality effects and surface representation. The forced-completion probe and LoRA nudges offer a scalable means to dissect and alter internal reasoning pathways, linking behavioral data to geometric properties of parameter space.
Practically, these results call for caution when deploying multimodal LLMs in settings requiring exact arithmetic, particularly for high-load operations, and underscore the value of explicit tool invocation or external verification. The precise characterization of strategy alignment and parameter separation offers a foundation for more robust arithmetic-specific adaptation, adversarial testing, and the design of verifiable computation modules in agentic systems.
Conclusions
The paper demonstrates that multimodal LLMs are limited by computational—not perceptual—factors in multi-digit multiplication, with performance sharply governed by arithmetic load. Models systematically prefer decomposition-based reasoning, and LoRA-induced procedural nudges reveal distinct parameter subspaces but fail to improve accuracy. These results quantify computational bounds, strategy alignment, and modality effects, laying groundwork for future research on modular arithmetic competence, explicit tool routing, and internal algorithm interpretability in foundation models.