- The paper introduces DQPOPE, a method that estimates the full return distribution using deep quantile process regression.
- It establishes theoretical guarantees with sample complexity bounds, matching pointwise value estimation efficiency.
- Empirical results in CartPole and healthcare domains demonstrate robust performance under heavy-tailed and real-world conditions.
Distributional Off-Policy Evaluation via Deep Quantile Process Regression
Introduction and Motivation
The off-policy evaluation (OPE) problem in reinforcement learning (RL) focuses on estimating the value of a target policy using data collected under a different behavior policy. Traditional OPE techniques estimate only the expected return, neglecting the full structure of the return distribution. With the rise of distributional RL (DRL), which models the entire return distribution and thus captures underlying stochasticity, there is a growing need for distributional approaches to OPE in both theory and practice. This paper introduces Deep Quantile Process regression-based Off-Policy Evaluation (DQPOPE), a method that estimates the full return distribution in OPE scenarios by leveraging deep neural networks for quantile process regression.
Methodological Framework
Quantile Process Regression for Return Distributions
DQPOPE builds on the observation that, rather than modeling merely a finite set of discrete quantiles as in QR-DQN and related approaches, one can represent the full quantile function as a continuous input to a deep neural network. This quantile process approach directly addresses the infinite-dimensionality of the distribution estimation problem by reducing it to a sequence of finite-dimensional supervised regressions.
DQPOPE iteratively approximates the distributional Bellman operator in the quantile domain. At each iteration, a deep network is trained to minimize the quantile regression (check) loss over randomly sampled quantile levels, with target values computed using samples propagated through the previous iteration's estimated quantile function. This procedure is illustrated as equivalent to distribution iteration in DRL, but formulated as a quantile process training loop, yielding an efficient and theoretically tractable estimation scheme.
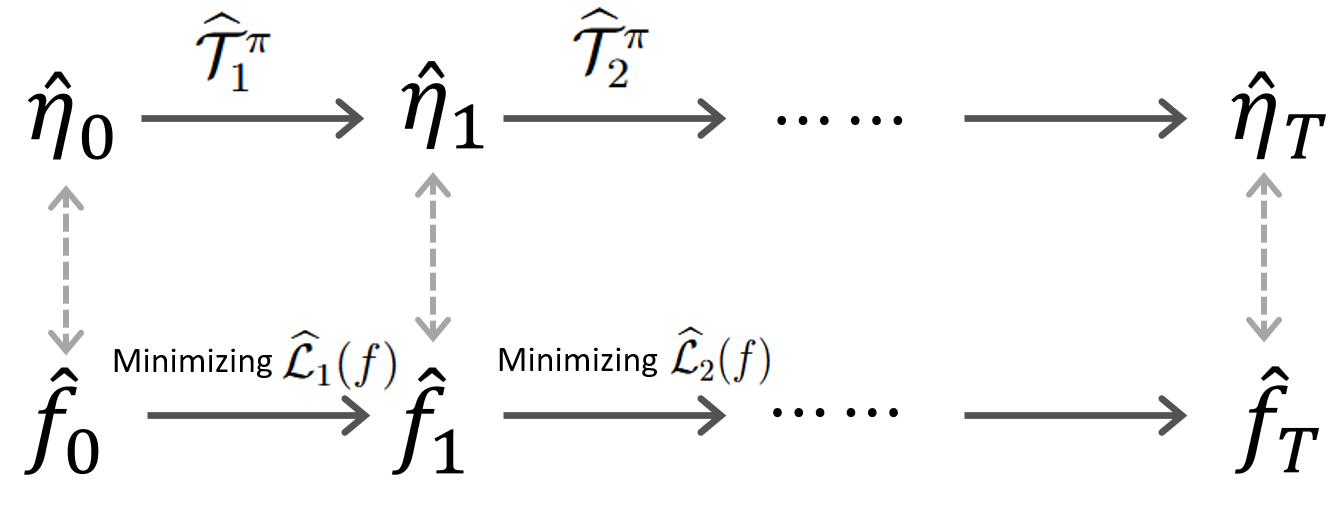
Figure 1: Equivalence between distribution iteration in DRL and quantile process training via deep quantile process regression.
A key implementation distinction is that DQPOPE can draw exact samples from the learned distribution for any quantile level by treating the level as a continuous input, avoiding the pseudo-sample and discretization error issues that degrade the representational power or computational efficiency of prior quantile-based DRL approaches.
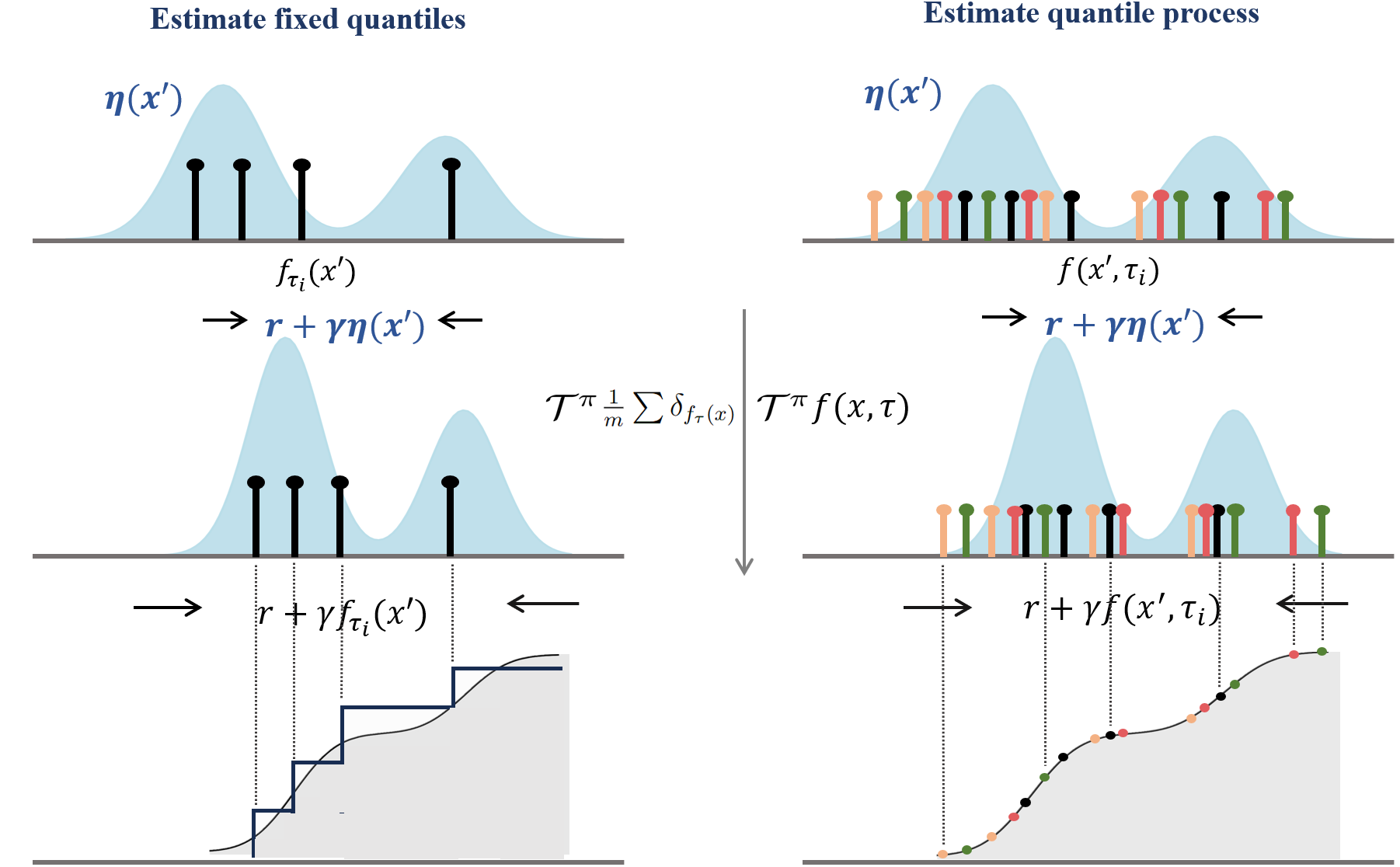
Figure 2: Quantile process regression learns the mapping of the distributional Bellman operator, capturing the return distribution over continuous quantile levels and precisely reconstructing the CDF.
Theoretical Analysis
Statistical and Sample Complexity Guarantees
DQPOPE’s theoretical analysis yields non-asymptotic generalization and sub-optimality bounds for return distribution estimation under deep ReLU network approximation. The main results are:
- Slow-rate bound: With minimal local convexity assumptions, the one-step Bellman error decays at n−β/(4β+2d) and the overall sub-optimality scales similarly—slower than classical value estimation but still exhibiting polynomial decay as sample size increases.
- Fast-rate bound: Under additional local smoothness and strong convexity, the excess quantile regression risk achieves the minimax-optimal non-parametric rate n−2β/(2β+d). Crucially, estimating the entire return distribution is shown to be as sample-efficient as pointwise value estimation, matching the sharp rates known for mean estimation. This extends prior DRL sample complexity theory beyond tabular or generative settings to practical, high-dimensional, network-based OPE.
These results rigorously establish that quantile process regression for return distributions does not require more data than traditional OPE methods targeting only the mean, despite the greater modeling complexity. The bounds further exhibit mild dependence on horizon and distributional shift coefficients, often improving over previous value-based OPE sample complexity results.
Empirical Evaluation
Sample Complexity in the CartPole Domain
To empirically validate theoretical rates, DQPOPE was evaluated for distributional OPE with varying sample sizes and behavior-target policy mismatches in CartPole. The error in the Wasserstein metric decayed polynomially with larger datasets. As the fraction of data collected under the target policy increased (reducing the distribution shift), estimation improved, reflecting tight alignment with statistical theory.
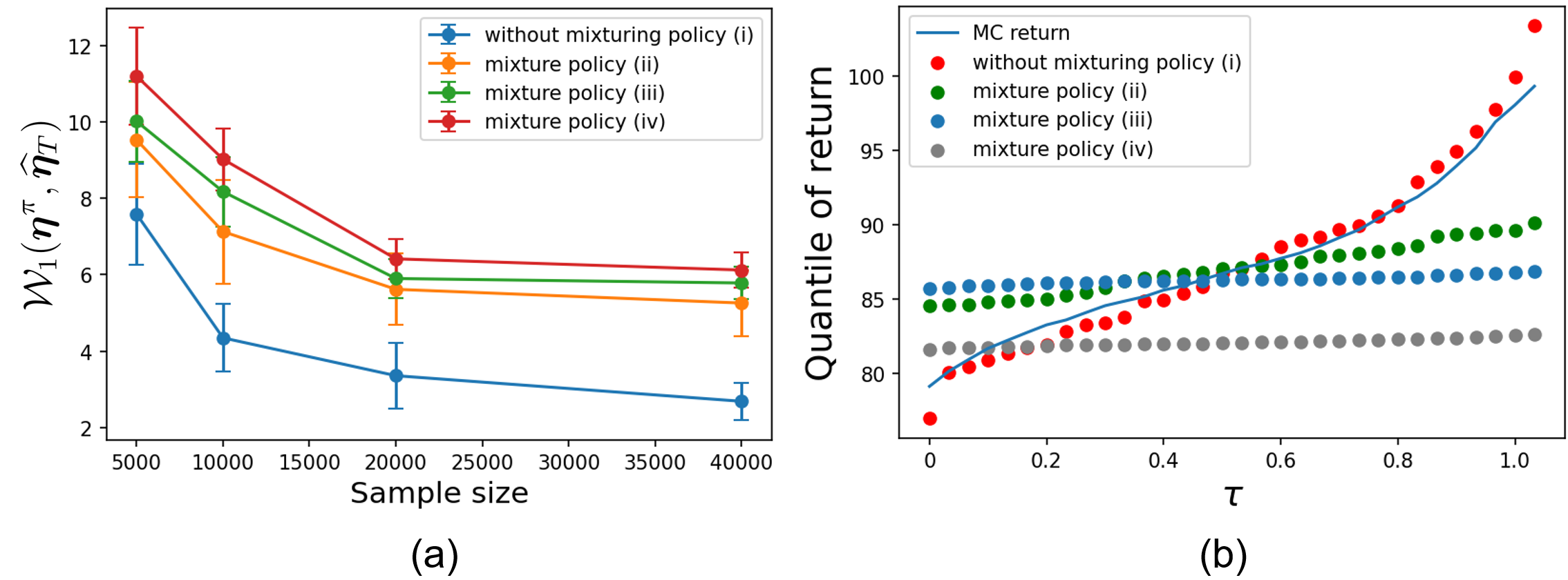
Figure 3: (a) Error versus sample size under different behavior/target policy mixtures. (b) Quantile estimation for true and estimated return distributions across settings.
Robustness and Value Estimation under Heavy Tails
In a controlled synthetic environment with varying reward tail heaviness (Student-t distributions), DQPOPE was compared to DOPE (standard value-based OPE). Policy value estimation error (MSE) was consistently lower for DQPOPE, with gaps widening as reward tails became heavier. Furthermore, increasing the number of quantiles reduced MSE, highlighting the robustness of quantile-based estimators in the presence of outliers.
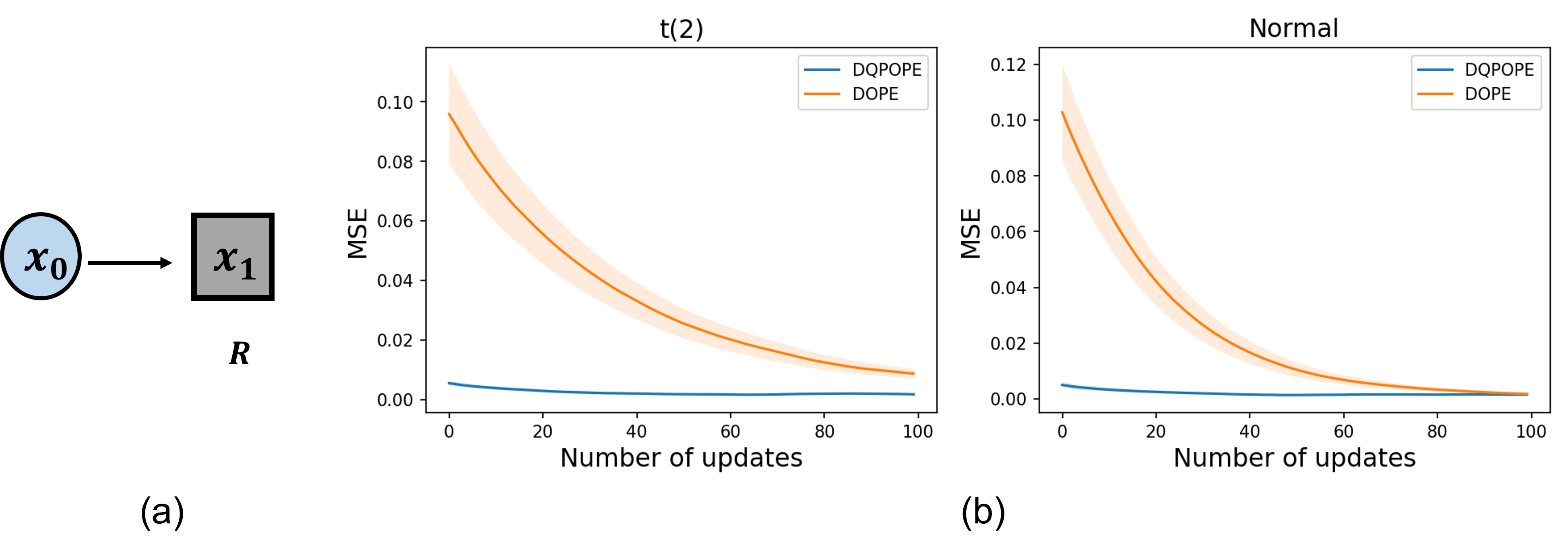
Figure 4: (a) Two-state synthetic environment. (b) MSE versus training updates for t(2) and Gaussian reward distributions.
Evaluation on MIMIC-III: OPE in Healthcare
DQPOPE, DOPE, and DQOPE (finite-quantile method) were evaluated on sequential treatment policy OPE tasks using the MIMIC-III medical dataset. DQPOPE more accurately separated target policies (e.g., DDQN vs. random/high-/low-dose baselines) and yielded lower-variance value estimates even under substantial policy mismatch and patient heterogeneity. Policy actions inferred from DQPOPE aligned more closely with actual practice, suggesting the benefit of full return distribution modeling under real-world data complexity and uncertainty.
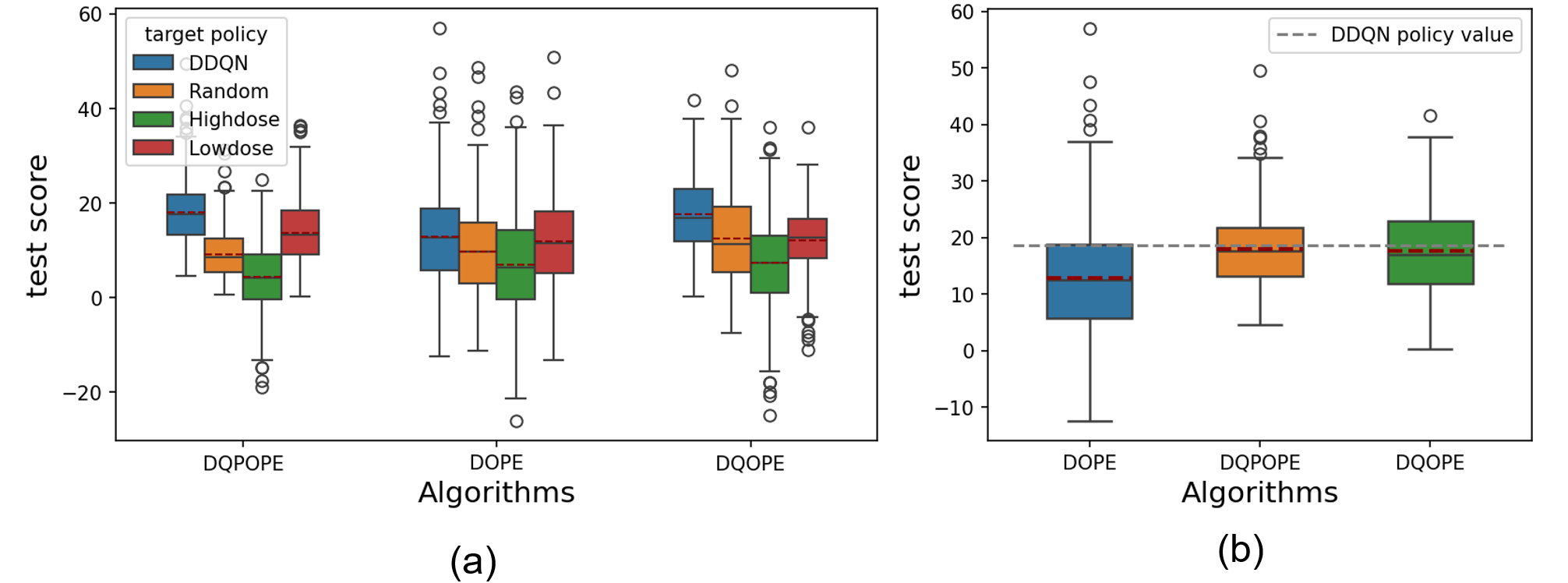
Figure 5: (a) Comparison of policy value estimate distributions for multiple algorithms and target policies. (b) Boxplots show tighter concentration and superior separation of DQPOPE estimates.
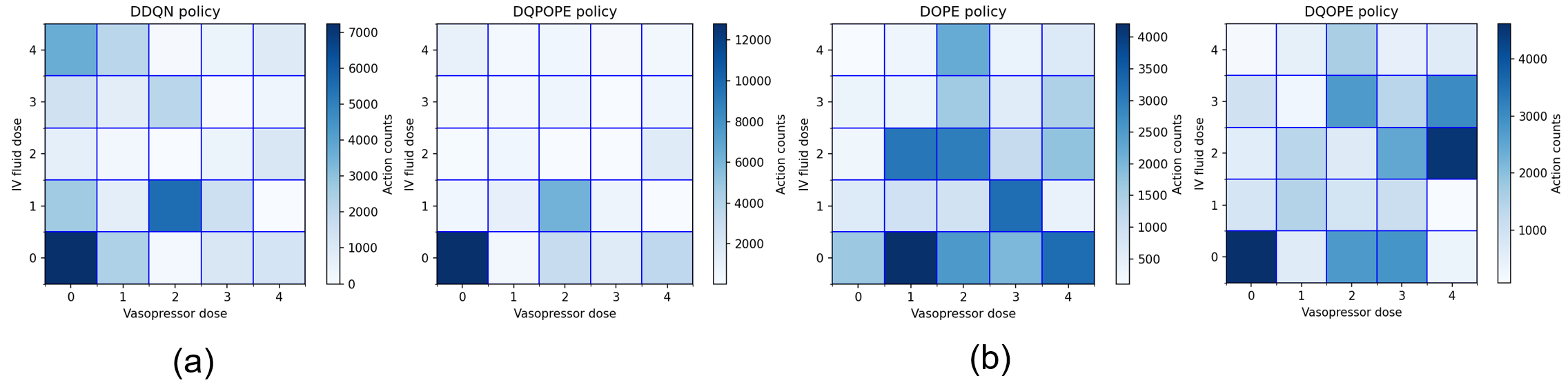
Figure 6: Action frequency heatmaps for various policy estimators vs. the DDQN reference policy reveal improved action alignment for DQPOPE.
Implications and Future Directions
This work demonstrates that quantile process regression, realized via deep neural networks, provides a principled, tractable framework for distributional OPE that avoids discretization pathologies and pseudo-sample overheads of prior quantile DRL approaches. Theoretical analysis reveals no loss in sample efficiency for estimating entire distributions compared to pointwise means, while practical experiments confirm robust, low-variance estimation under challenging data regimes.
Strong claims in the paper include:
- The full return distribution can be estimated via DQPOPE as efficiently (in sample complexity) as its mean.
- Quantile process regression directly resolves practical and theoretical limitations of both finite-quantile and parametric (e.g., categorical or diffusion) distributional OPE algorithms.
Practically, improved robustness and uncertainty quantification are critical for reliable off-policy deployment in high-stakes domains (e.g., healthcare, finance). Theoretically, the analysis opens avenues for more sophisticated distributional algorithms—such as risk-sensitive or tail-dependent control—grounded by provable efficiency.
Future developments include:
- Extending DQPOPE-style quantile process regression to policy optimization and control settings (beyond evaluation).
- Investigating generalization to undirected observation spaces and partially observed RL.
- Integration with uncertainty-aware exploration and safe deployment paradigms.
- Development of scalable “quantile process” critics and actors in deep continuous control domains.
Conclusion
DQPOPE establishes a rigorous bridge between stochastic process theory and modern DRL by formulating distributional OPE as quantile process regression via deep networks. Its theoretical guarantees, practical tractability, and empirical effectiveness collectively advance both methodology and understanding of distributional reinforcement learning in offline and high-dimensional settings.