- The paper introduces FLiP as a factorized linear projection model to recover lexical information from multilingual and multimodal embeddings.
- It demonstrates strong parameter efficiency and improved keyword extraction accuracy compared to baseline methods like SpLiCE.
- FLiP reveals cross-modal and cross-lingual semantic linearity, while highlighting an English bias in embedding spaces.
FLiP: Factorized Linear Projection for Multimodal Multilingual Sentence Embedding Interpretability
Introduction and Motivation
The paper "FLiP: Towards understanding and interpreting multimodal multilingual sentence embeddings" (2604.18109) introduces the Factorized Linear Projection (FLiP) model as a systematic approach to diagnosing and interpreting sentence embedding spaces. FLiP serves to recover lexical content from multilingual (LaBSE), multimodal (SONAR), and API-based (Gemini) embedding spaces, facilitating insight into what semantic information is encoded and how it is distributed across modalities and languages. Unlike prior interpretability techniques focused primarily on English or on single modality embeddings, FLiP generalizes across modalities (text, speech) and languages (high/mid-resource), providing a unified diagnostic tool that does not rely on downstream task-centric evaluation.
Methodological Framework
FLiP is situated within the linear representation hypothesis paradigm, advocating for interpretable linear projections to probe semantic structure in embedding spaces. It reframes interpretability as a linear keyword extraction task, employing:
- Log-linear Model: Mapping sentence embeddings to vocabulary space via a single linear mapping (projection matrix W and bias b).
- Factorization: Decomposition W=AB, where A is the word embedding matrix and B projects modality-specific embeddings to a latent space. Factorization (with explicit low-rank and L1 regularization) enhances parameter efficiency and imposes strong implicit regularization.
- Cross-modal and Cross-lingual Training: By integrating speech and text embedding pairs in the training objective, FLiP probes whether semantic concepts align linearly across modalities and languages, compensating for variability and measuring semantic transfer.
Keyword extraction for unseen embeddings is performed by computing logits via the factorized linear projection and selecting top-k indices associated with vocabulary words. The bias term b learns a log-unigram prior, modulating retrieval of frequent words and affecting named entity recall.
Experimental Setup
FLiP and baselines (non-factorized linear projection; SpLiCE) are evaluated using:
- Common Voice (MCV) corpus for speech-text pairs (EN, DE, FR)
- Europarl and Samanantar for parallel bitexts (EN-{DE, FR, BN, HI, TA, TE})
- Standard, span-aware, and Jaccard metrics for keyword extraction performance
- Comparison with SpLiCE using matched concept vocabulary and span-aware accuracy
Embeddings are extracted from SONAR, LaBSE, and Gemini models, each representing distinct training paradigms and modalities. Vocabulary is standardized at b0k unigrams; speech and text embeddings are matched via cross-modal training.
Results: Semantic Linearity and Diagnostic Insights
Factorization and Rank
FLiP demonstrates that factorizing the projection matrix yields substantial regularization benefits, significantly outperforming non-factorized models at all ranks. At rank b1, FLiP recalls b2 of text lexical items and b3 for speech embeddings, closely approaching full-rank performance with fewer parameters.
Modality Alignment
Cross-modal probing reveals robust semantic linearity within languages: keyword extraction accuracy is consistent between text-only and speech-only FLiP models, particularly in SONAR's unified space. Training on speech embeddings slightly enhances transferability to text, evidence that SONAR's multimodal alignment is effective.
Cross-Lingual Semantic Linearity
FLiP identifies a pronounced English bias in embedding spaces: training on EN embeddings allows transfer to related languages (DE, FR) but results in significant accuracy drops for less-related languages (e.g., EN-TA, EN-TE). Conversely, non-English embeddings do not yield comparable transfer, confirming a degradation in semantic linearity as linguistic distance increases.
Vocabulary Effects
Using non-target vocabularies exacerbates performance degradation, especially for linguistically distant languages and bilingual training regimes. For EN-TA, accuracy drops from b4 to b5 when switching from EN to TA vocabulary, illustrating the dominance of English as the conceptual anchor in SONAR and similar models.
Model Comparison
SONAR consistently outperforms LaBSE and Gemini across all vocabulary/embedding pairs, but all show the same trend: highest keyword recall with English vocabulary and embeddings, declining for non-English settings.
Named Entity Recall Dynamics
FLiP can recover named entities from embeddings with high fidelity, but retrieval is sensitive to the bias term (log-unigram prior). Removing the bias enhances information-centric retrieval by down-weighting frequent stop words, improving recall for entities as b6 increases.
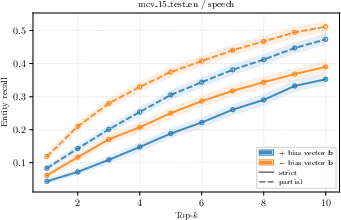
Figure 1: Named-entity recall as function of top-b7 extracted keywords and the effect of bias vector on the logit scores.
Comparison with SpLiCE
FLiP achieves span-aware accuracy of b8 (text) and b9 (speech), nearly double that of SpLiCE (text W=AB0, speech W=AB1) using identical concept vocabularies. Thus, FLiP provides a superior, task-agnostic interpretability mechanism without relying on vocabulary heuristics.
Implications and Future Directions
FLiP establishes that semantic information in sentence embeddings is largely linearly recoverable, with well-trained multimodal encoders (notably SONAR) yielding W=AB2 recall of lexical content. This reinforces the linear representation hypothesis at scale for multilingual, multimodal scenarios. The English bias observed underscores critical challenges for genuinely language-agnostic embeddings, raising the need for more equitable multilingual training and diagnostic tools. Practically, FLiP enables rapid intrinsic model diagnosis and interpretability, supporting model debugging, bias analysis, and semantic probing without downstream task reliance.
In future developments, the FLiP paradigm could be extended to compositional concept probing, adaptive cross-lingual factorization, and integration with continuous semantic spaces beyond unigrams (multi-word expressions, structured knowledge). Further, FLiP-style diagnostics may become indispensable for benchmarking new generative and retrieval-centric models, driving representation learning toward greater transparency and fairness.
Conclusion
FLiP is a robust, efficient method for interpreting multimodal and multilingual sentence embedding spaces, revealing strong semantic linearity and substantial English bias in current encoder architectures. Through explicit factorization and cross-modal/cross-lingual probing, FLiP achieves parameter-efficient, high-fidelity lexical recovery from embeddings and offers superior interpretability compared to existing baselines. Its adoption as a diagnostic tool can drive progress in multilingual representation learning and fairer cross-modal modeling, with direct implications for both research and practical deployment in multilingual AI systems.

