- The paper introduces a dual-stream model that disentangles semantic contributions from both reference video and modification text to improve retrieval performance.
- It employs directional anchor calibration and evidence-driven alignment to effectively distinguish target videos from closely similar negative candidates.
- Experiments on datasets like WebVid-CoVR and FashionIQ demonstrate state-of-the-art recall enhancements and robust cross-domain generalization.
ReTrack: Evidence-Driven Dual-Stream Directional Anchor Calibration for Composed Video Retrieval
Introduction and Motivation
The proliferation of multimodal video data introduces the challenge of retrieving specific videos based not on a unimodal query but on composed queries—pairs consisting of a reference video and modification text that articulates the desired change. The Composed Video Retrieval (CVR) paradigm formalizes this requirement but exposes limitations in established approaches. Notably, prior methods overly bias the composed feature representation toward the reference video’s visual signal, underweighting the modification text, and suffer from uncertainty when negative candidates are closely aligned to the query composition (Figure 1).
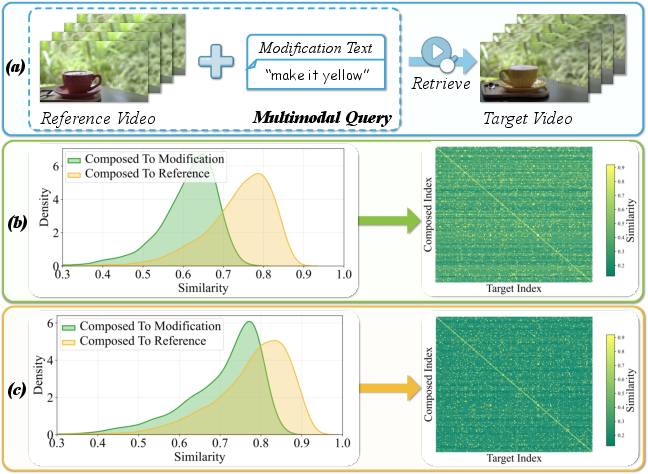
Figure 1: (a) Typical CVR example structure. (b) Existing approaches exhibit directional bias, causing the composed feature’s similarity to the target video to be indistinguishable from negatives. (c) ReTrack mitigates bias, establishing clear separation to all negatives.
Three core challenges in CVR are identified: (1) disentangling the semantic contributions of each modality (video and text), (2) explicitly calibrating the direction and geometry of the composed feature in embedding space, and (3) robustly quantifying retrieval certainty amid visually and semantically similar candidate targets.
ReTrack Architecture
ReTrack is an evidence-driven dual-stream anchor calibration model, purpose-built to directly address these three methodological gaps.
1. Semantic Contribution Disentanglement
ReTrack utilizes a Q-Former backbone for representation and leverages a Transformer decoder to extract the semantic contributions from both the reference video and modification text independently. Rather than naïve vector arithmetic, this modality-aware separation enables calibration with respect to each channel and modality, forming a basis for downstream correction of the composed feature’s representation.
2. Composition Geometry Calibration
Directional bias—excess weighting of one modality—is addressed by generating directional anchors based on the disentangled contributions. These anchors capture the influence strength of each semantic channel, implemented via adaptively learned point weights. ReTrack employs a two-stage calibration: distance-oriented alignment uses a batch-based classification objective to cluster the composed feature with the ground-truth target; direction-oriented calibration reconstructs the composed feature by embedding the directionality information encoded in the dual anchors (visual and textual), ensuring geometric proximity and optimal angular alignment with the true target.
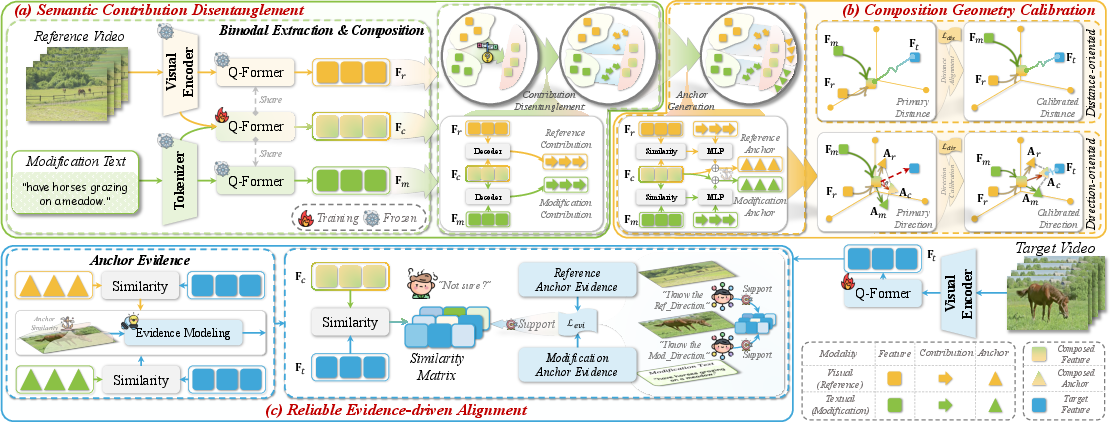
Figure 2: ReTrack’s architecture with modules for semantic contribution disentanglement, composition geometry calibration, and reliable evidence-driven alignment.
3. Reliable Evidence-Driven Alignment
To mitigate the uncertainty due to semantically similar negatives, ReTrack draws on principles from Dempster-Shafer Theory (DST) and Evidential Deep Learning (EDL). By quantifying evidence for correspondence between directional anchors and target candidates, the model infers a channel-wise reliability score. The correlation reliability is computed for both video and text streams individually; a regularization loss enforces agreement between reliability and compositional similarity, adaptively attenuating the influence of ambiguous channels or candidates and ensuring robust alignment in the presence of hard negatives.
Experimental Results
Composed Video Retrieval
On the WebVid-CoVR dataset, ReTrack outperforms both pretrained (BLIP, CLIP) and dedicated CVR models (CoVR, CoVR-2, FDCA, CoVR_Enrich), setting new state-of-the-art metrics: 63.85% R@1 and 85.7% mean recall, an improvement of >2.5% over prior bests without any reliance on auxiliary enrichment data (2604.17898).
Composed Image Retrieval
Evaluated on FashionIQ and CIRR (canonical CIR benchmarks), ReTrack not only surpasses all dedicated CIR models but also demonstrates cross-task generalization, establishing new bests across recall metrics, e.g., 52.91% R@10 and 77.54% R@50 (Dresses category, FashionIQ). These results verify the broad applicability of the feature disentanglement and evidence-driven calibration regime to other multimodal retrieval contexts.
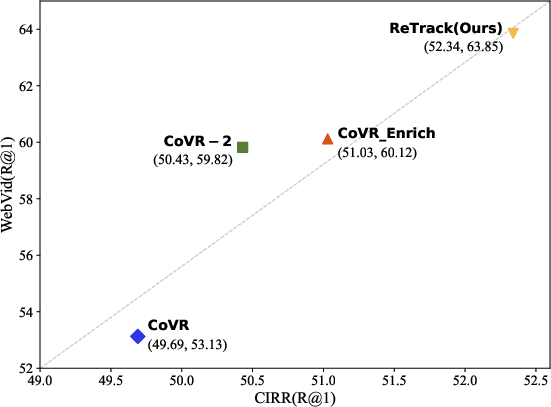
Figure 3: Comparative R@1 performance for CIR and CVR benchmarks. ReTrack achieves superior accuracy along both axes, indicating strong multiclass and multimodal generalization.
Analytical and Ablation Studies
Extensive ablation isolates the efficacy of each module. Removal of semantic contribution disentanglement or direction-oriented calibration leads to a marked degradation in both recall and mean accuracy. The evidence-driven loss is indispensable for robust retrieval amid strong negative candidates. The model shows stable sensitivity to trade-off hyperparameters κ and λ, with empirical optima well-behaved (Figure 4).
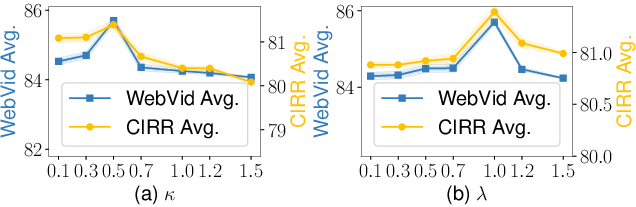
Figure 4: Performance sensitivity analysis for loss hyperparameters κ and λ on WebVid-CoVR and CIRR.
Qualitative Analysis
Case studies highlight the failure cases of previous approaches, wherein prevalent scene elements in the reference video or excessive textual bias corrupt the compositional feature. By contrast, ReTrack leverages evidence quantification to robustly filter out irrelevant background or over-specified cues, consistently retrieving targets that conform to all aspects of the compositional query (Figure 5).
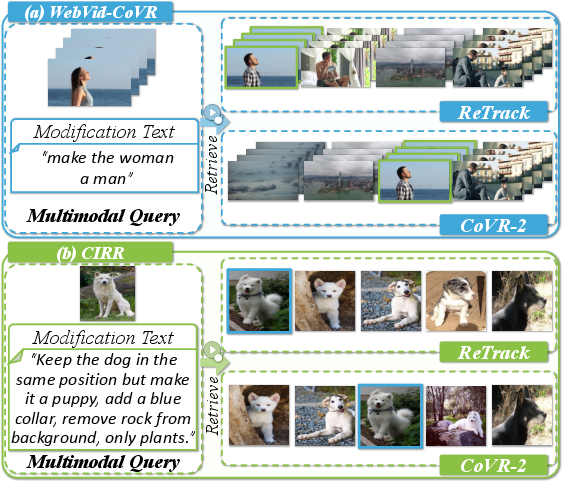
Figure 5: Case study on WebVid-CoVR and CIRR, demonstrating that ReTrack correctly aligns to target even with background/scene distractions or complex modifications.
Further, expanded case analyses show the model’s resilience across datasets/domains—even when ground-truth annotations are ambiguous or visual content is under-specified, the calibrated features yield more semantically precise retrievals (Figures 6, 7).

Figure 6: More visual examples on the CVR task, illustrating successful directional calibration and robust handling of compositional shifts.

Figure 7: Additional CIR cases downstream, showcasing ReTrack’s applicability and generalization across domains.
Practical and Theoretical Implications
The directional anchor calibration paradigm enables more interpretable and controllable integration of distinct multimodal cues—potentially adaptable to other tasks involving multimodal compositional queries, e.g., dialog-based retrieval, instruction-based synthesis, or cross-modal reasoning. The evidence-driven alignment mechanism, incorporating DST and EDL, introduces a robust framework for channel-wise uncertainty modeling and explicit reliability control—critical directions for future adaptive and uncertainty-aware retrieval systems.
ReTrack’s secondary construction of composed features, channel-wise calibration, and quantification of alignment reliability define a new operational basis for composed multimedia retrieval, with implications for both system-level design and theoretical modeling of multimodal composition.
Conclusion
ReTrack advances the state of the art in composed video (and image) retrieval, addressing long-standing bottlenecks in multimodal feature fusion, directional bias, and uncertainty quantification. Its evidence-driven dual-stream architecture fuses calibrated semantic anchors with reliability-aware alignment, yielding consistently superior retrieval accuracy and robust generalization across benchmarks and modalities. Future work may expand upon its interactive compositional framework, enabling multi-turn or contextually adaptive multi-modal retrieval scenarios.

