- The paper introduces a dual-path consistency mechanism, combining projection-guided structural guidance and patch-level semantic propagation, to resolve cross-view inconsistencies in text-driven 3D scene editing.
- A novel dataset, CVC-Edit, was constructed to provide robust pairwise consistent supervision for learning cross-view dependencies, enabling superior editing performance in complex 3D scenes.
- The proposed method significantly outperforms state-of-the-art techniques, achieving a 0.0874 CLIP directional similarity and 0.7768 DINO similarity, demonstrating enhanced structural integrity and semantic coherence across multiple viewpoints.
View-Consistent 3D Scene Editing via Dual-Path Structural Correspondence and Semantic Continuity
Text-driven 3D scene editing, enabling modifications to 3D environments via natural language instructions, faces a significant challenge in maintaining cross-view consistency. Current methodologies typically involve a render-edit-optimize sequence where multi-view images are rendered, edited by 2D image editors, and subsequently used to optimize the underlying 3D representation. However, this largely relies on per-view processing, leading to significant inconsistencies across viewpoints in geometry, appearance, and semantic details (Figure 1a). Previous attempts to mitigate this, such as incorporating geometric cues, cross-view interactions, or video priors, often depend on inference-time synchronization, which limits robustness and generalization.

Figure 1: (a) Cross-view discrepancies in per-view edits, highlighted in orange boxes. (b) Our multi-view consistent results, which preserve structural correspondence and semantic continuity across viewpoints.
This research reframes multi-view consistent 3D editing from a distributional perspective, positing that 3D scene editing necessitates joint distribution modeling across viewpoints. The proposed framework explicitly introduces and learns cross-view dependencies within the editing process. A key insight is the distinct nature of structural correspondence and semantic continuity, which rely on different cross-view cues. Consequently, a dual-path consistency mechanism is introduced, comprising projection-guided structural guidance and patch-level semantic propagation for effective cross-view editing. Furthermore, a novel paired multi-view editing dataset, CVC-Edit, is constructed to provide robust supervision for learning cross-view consistency in edited scenes. This methodology achieves superior editing performance with precise and consistent views for complex scenes (Figure 1b).
Cross-View Consistency Framework
The conventional render-edit-optimize pipeline for 3D Gaussian Splatting (3DGS) treats the editing of multiple views as independent single-image editing operations. This approximation, p({I^i}i=1N∣{Ii}i=1N,c)≈i=1∏Np(I^i∣Ii,c), where I^i are edited images, Ii are original images, and c is the text prompt, fundamentally mismatches the objective of generating a set of jointly coherent views corresponding to a single edited 3D scene. The research addresses this by formulating multi-view editing as a consistency-aware process with explicit cross-view dependencies. Utilizing a tractable neighboring-view approximation through the chain rule, the joint distribution is factorized as p(I^i∣Ii,I^i−1,c), where information is progressively propagated across adjacent viewpoints.
This framework is underpinned by a dual-path consistency mechanism addressing two complementary aspects: structural correspondence and semantic continuity. Structural correspondence ensures spatial alignment across viewpoints, preserving local regions, boundaries, and scene layouts under viewpoint changes. Semantic continuity maintains a stable and coherent edited content, such as object identity, attributes, materials, and overall appearance, across views. These distinct requirements are modeled by a projection-guided structural guidance path and a patch-level semantic propagation path, respectively (Figure 2).
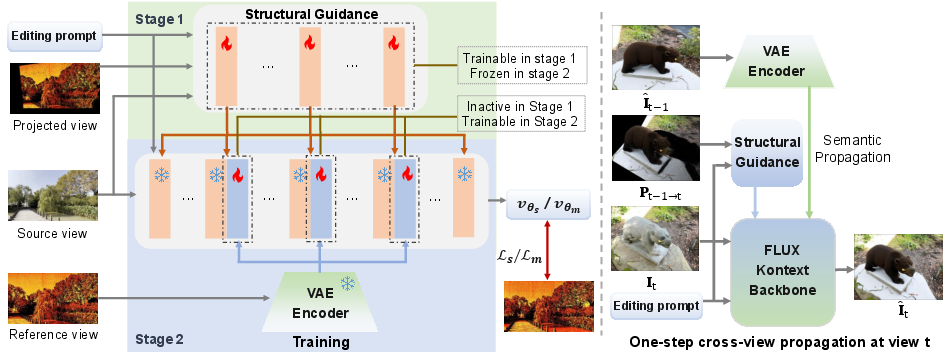
Figure 2: Overview of the proposed framework. Left: two-stage training under a unified architecture, where Stage 1 trains the projection-guided structural guidance path (θs) and Stage 2 freezes it and trains the patch-level semantic propagation path (θm). Right: inference at view t, where Pt−1→t and I^t−1 are fed into the structural guidance and semantic propagation paths respectively, jointly guiding the editing of the current view to produce I^i0 consistent with the reference cues.
Projection-Guided Structural Guidance
To enforce structural consistency, a projection-guided structural guidance path transfers geometry-aware editing cues between neighboring views. This involves reprojecting a previously edited view, I^i1, into the current viewpoint using estimated scene depth, I^i2, and relative camera transformations, I^i3, to generate a projected structural cue, I^i4. This I^i5 provides a physically grounded hypothesis of structural correspondence for the current view.
The projected cue is not used as a deterministic constraint but as a learnable structural prior. It is converted into residual structural features and injected into the diffusion transformer backbone through a dedicated conditioning path. This path, a lightweight network with significantly fewer blocks than the backbone, takes I^i6, I^i7, and I^i8 as input, generating intermediate structural features I^i9. These features are then added to the hidden states of selected backbone blocks via a block-wise residual conditioning strategy: Ii0, where Ii1 indicates the block interval. This design enables multi-level structural control with minimal additional parameters, enhancing geometry-aware guidance while preserving generative flexibility.
Patch-Level Semantic Propagation
While structural guidance ensures geometric alignment, it does not guarantee stable edited content. To address semantic drift across viewpoints, a patch-level semantic propagation path is introduced. This path encodes the edited result of the previous view, Ii2, into spatial patch-level feature tokens using a frozen encoder. These tokens act as a compact semantic reference representing the accumulated editing state.
For each DiT block Ii3, reference features are projected into key Ii4 and value Ii5 representations. The attention mechanism is augmented with a reference-guided term, where the query Ii6 attends to these propagated features: Ii7. The enhanced attention output Ii8 incorporates this semantic context. This mechanism is instantiated in intermediate layers (7th to 40th DiT blocks), where semantic abstraction is most suitable for propagation, thereby stabilizing semantic transfer and improving efficiency. This operation propagates semantic state at a feature level, effectively complementing structural guidance by reducing semantic drift and maintaining consistent appearance properties across views.
Consistency-Aware Multi-View Editing Dataset (CVC-Edit)
A critical component for learning cross-view consistency is the availability of suitable supervision. Standard image editing datasets are insufficient as they lack explicit cross-view relationship encoding. Recognizing that powerful image editors can produce strong pairwise coherence when adjacent views are concatenated and jointly edited, the CVC-Edit dataset is constructed. This dataset provides pairwise consistent supervision for cross-view propagation learning.
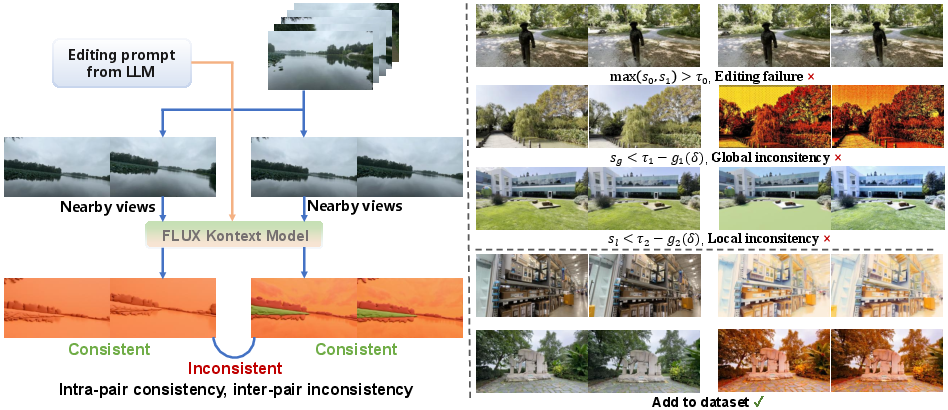
Figure 3: Consistency-aware multi-view editing dataset construction. Left: view pairs with limited viewpoint difference are concatenated and jointly edited by a pre-trained image editing model, providing pairwise consistent supervision. Right top: failed or inconsistent edited pairs are discarded according to edit validity, global consistency, and local consistency. Right bottom: the retained pairs form the final training set for cross-view consistency learning.
Dataset construction begins by sampling pairs of frames Ii9 with limited viewpoint difference from video sequences. These concatenated image pairs are then jointly edited using a pre-trained image editing model and a text instruction c0. To improve reliability, a multi-criteria filtering strategy based on DINOv3 features is applied (Figure 3). This filtering includes:
- Edit Validity: Discards pairs where c1, indicating insufficient editing.
- Global Consistency: Filters based on cosine similarity of global DINOv3 features: c2.
- Local Consistency: Filters using bidirectional patch matching similarity of local DINOv3 features: c3.
Adaptive thresholds, conditioned on viewpoint difference c4, are employed for consistency metrics. The refined CVC-Edit dataset, comprising 280K samples, provides robust supervision for both structural guidance and semantic propagation pathways.
Training and 3DGS Update
The framework is trained in two stages using the latent flow-matching formulation of FLUX Kontext (2604.17801). The original backbone is frozen throughout.
Stage 1: Trains the projection-guided structural guidance path (c5). The flow-matching objective c6 is minimized, where c7 is an intermediate latent state and c8 is the target velocity field. This stage focuses on learning reliable projection-guided structural control.
Stage 2: Freezes the structural guidance path and trains the patch-level semantic propagation path (c9). The objective p(I^i∣Ii,I^i−1,c)0 is minimized, improving cross-view semantic consistency.
During inference, a sequential multi-view editing process propagates both structural guidance and semantic propagation. For the first view, the edited result is generated directly. For subsequent views, the projected cue p(I^i∣Ii,I^i−1,c)1 and encoded patch-level semantic features from p(I^i∣Ii,I^i−1,c)2 are fed into their respective paths, guiding the current view's editing. After all views are edited, the resulting images update the 3D Gaussian Splatting representation.
Experimental Results
The framework was evaluated against state-of-the-art methods (GaussCtrl, DGE, EditSplat, ViP3DE) using CLIP text-image similarity, CLIP directional similarity, and DINO similarity for cross-view consistency. The proposed method significantly outperforms baselines across all metrics. For instance, it achieved a CLIP directional similarity of 0.0874, compared to the next best of 0.0656 for DGE, and a DINO similarity of 0.7768, surpassing DGE's 0.7501 (Table 1).
<br>
| Method |
Year |
CLIPp(I^i∣Ii,I^i−1,c)3 p(I^i∣Ii,I^i−1,c)4 |
CLIPp(I^i∣Ii,I^i−1,c)5 p(I^i∣Ii,I^i−1,c)6 |
DINO p(I^i∣Ii,I^i−1,c)7 |
| GaussCtrl |
2024 |
0.2287 |
0.0478 |
0.7278 |
| DGE |
2024 |
0.2384 |
0.0656 |
0.7501 |
| EditSplat |
2025 |
0.2366 |
0.0612 |
0.7353 |
| ViP3DE |
2026 |
0.2278 |
0.0588 |
0.7488 |
| Ours |
2026 |
0.2561 |
0.0874 |
0.7768 |
<br>
Table 1: Quantitative comparison with other 3D editing methods. CLIPp(I^i∣Ii,I^i−1,c)8: CLIP text-image similarity; CLIPp(I^i∣Ii,I^i−1,c)9: CLIP directional similarity.
Qualitative comparisons (Figure 4) further demonstrate the superior ability of the proposed method to maintain structural integrity and semantic consistency, particularly for complex scene-level edits. Other methods frequently exhibit inconsistent appearance, structural distortions, or artifacts across viewpoints.

Figure 4: Qualitative comparison with state-of-the-art methods under various editing prompts. The leftmost column shows source images, while the right columns show rendering images from edited 3DGS. Our method achieves more consistent, coherent, and faithful editing results across viewpoints, particularly for complex scene-level editing instructions.
Ablation Studies
Ablation studies confirmed the Necessity of each component (Table 2). Direct editing, without any consistency modeling, clearly leads to cross-view inconsistencies (Figure 5).

Figure 5: Visual comparison between Direct Editing and our full model. Direct Editing performs per-view editing independently, causing appearance inconsistency across viewpoints, while our full model produces more coherent results.
Removing the structural guidance path results in weakened structural stability and less reliable geometric correspondence (Figure 6).
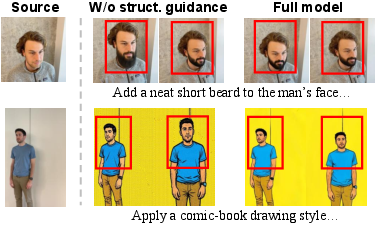
Figure 6: Visual comparison between w/o structural guidance and the full model. Removing the structural guidance path weakens structural stability across viewpoints, leading to less reliable geometric correspondence and local misalignment.
The absence of the semantic propagation path leads to less complete and inconsistent semantic edits across views (Figure 7).

Figure 7: Visual comparison between w/o semantic propagation and the full model. W/o semantic propagation, the edits become less complete and less consistently across viewpoints, whereas the full model yields more coherent semantic changes.
<br>
| Method |
CLIPθs0 θs1 |
CLIPθs2 θs3 |
DINO θs4 |
| Direct Edit |
0.2269 |
0.0463 |
0.7423 |
| w/o struct. transfer |
0.2403 |
0.0733 |
0.7592 |
| w/o sem. mem. inject |
0.2442 |
0.0742 |
0.7633 |
| Full Model |
0.2561 |
0.0874 |
0.7768 |
<br>
Table 2: Ablation study on the key components of our method. The full model achieves the best overall performance, showing that both structural guidance and semantic propagation contribute to consistent multi-view editing.
Analysis of design choices revealed that a balanced architecture for the structural guidance path (3 double blocks + 6 single blocks) provided optimal performance. Similarly, injecting semantic propagation in intermediate layers (7th-40th DiT blocks) achieved the best results, indicating a suitable balance between semantic propagation and stable multi-view editing.
Conclusion
This research introduced a novel cross-view consistency framework for 3D scene editing. By reformulating multi-view editing as a cross-view dependent process aligning with the joint distribution of consistent scene edits, the framework addresses pervasive multi-view inconsistency issues. The proposed dual-path mechanism, integrating projection-guided structural guidance and patch-level semantic propagation, along with the CVC-Edit dataset, enables robust learning of cross-view consistency. Empirical evidence demonstrates superior editing quality and consistency against existing methods.
The implications of this research are significant for various applications requiring high-fidelity 3D content creation, such as virtual production, digital asset editing, and immersive environment design. By robustly maintaining consistency across views, the framework opens avenues for more complex and realistic scene modifications. Future developments in AI could leverage this approach to explore dynamic 3D scene editing, incorporating temporal consistency for video scenarios, and potentially extending to real-time interactive 3D content creation. Additionally, integrating more sophisticated 3D native priors could further enhance coherence and reduce reliance on 2D diffusion model approximations.

