- The paper proposes NOVA-ARC, a novel framework using hyperbolic geometry and prosodic tokenization for unsupervised non-verbal-to-verbal transfer in SER.
- Methodology employs prototype-based alignment with optimal transport, achieving up to 92.40% accuracy in cross-lingual emotion transfer using voc2vec representations.
- Experiments over six datasets demonstrate significant gains over Euclidean baselines, highlighting benefits for low-resource and multilingual settings.
Prosody as Supervision: Unsupervised Non-Verbal-to-Verbal Transfer for Multilingual Speech Emotion Recognition
This work confronts a persistent challenge in speech emotion recognition (SER): the limitation of labeled verbal speech as a supervisory signal, particularly in low-resource and multilingual settings where emotional annotation is both costly and unevenly distributed across languages. The core hypothesis underpinning this study is that non-verbal vocalizations (e.g., laughter, sobs, sighs) provide a more language-agnostic and affectively rich source of supervisory signal than verbal utterances, due to their paralinguistic acoustic nature and cross-lingual physiological universality.
Instead of the conventional verbal-to-verbal SER paradigm, the study proposes unsupervised non-verbal-to-verbal transfer. The target formulation is as follows: models are trained to recognize emotions from labeled non-verbal vocalizations (NVV) and adapted to unlabeled verbal speech (UVS) in possibly different languages—eschewing the need for target-language emotion labels. The approach is further motivated by the limitations of existing domain adaptation methods, which, despite recent advances (e.g., adversarial alignment, vector quantization, and multimodal fusion), are still dependent on verbal-labeled supervision, and thus suffer from poor robustness in truly low-resource and cross-lingual contexts.
Proposed Framework: NOVA-ARC
The principal contribution is NOVA-ARC—Non-Verbal to Verbal Adaptation via hyperbolic Alignment, Radial calibration, and Codebook tokens. The architecture introduces several technical innovations for geometry-aware, paralinguistic-centric domain adaptation in SER.
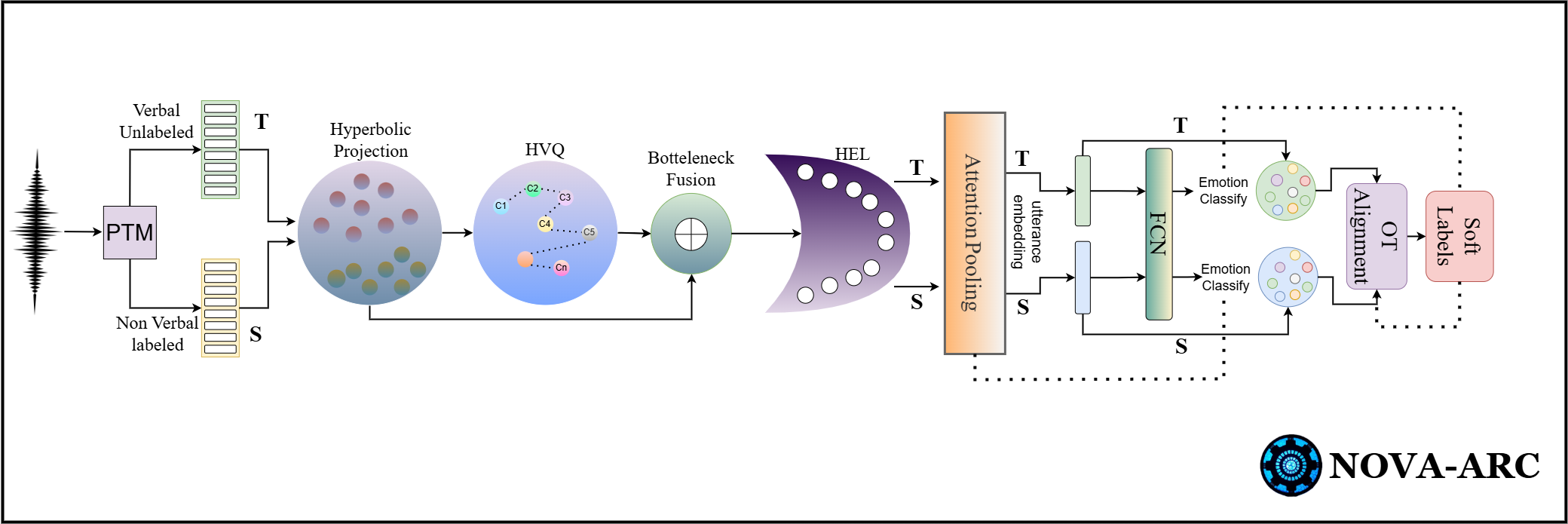
Figure 1: Overview of the NOVA-ARC framework integrating hyperbolic prosody tokenization, prototype-based optimal transport, and hierarchical alignment for non-verbal-to-verbal emotion transfer.
Model Architecture and Geometry
The system uses a plug-and-play acoustic encoder (voc2vec, WavLM, wav2vec 2.0, or MMS-1B) to extract frame-level features from audio, which are then projected into the Poincaré ball model to enable efficient modeling of hierarchical affective structures. Hyperbolic geometry is chosen to reduce distortion when capturing nested relationships among emotions—consistent with findings that hierarchical structure is fundamental in affective expression and recognition.
Prosodic patterns are discretized via a hyperbolic vector-quantized (VQ) codebook, generating discrete paralinguistic tokens. Continuous and discrete representations are fused using Möbius operations in hyperbolic space. A bottleneck and the Hyperbolic Emotion Lens (HEL), a novel radial calibration mechanism, further compress and intensity-adjust embeddings to regularize scale mismatches between non-verbal and verbal domains.
Prototype-Based Alignment with Optimal Transport
Labeled NVV utterances yield class-specific hyperbolic prototypes (Fréchet means). During adaptation, verbal target utterances are optimally aligned with these prototypes using entropically regularized optimal transport (OT) in hyperbolic space, defining a probabilistic soft labeling mechanism for the target data. Both geometric alignment and soft cross-entropy losses are jointly optimized, enforcing domain consistency. Consistency regularization is applied to further stabilize adaptation under unsupervised conditions.
Experimental Setup
Evaluation spans six datasets encompassing both non-verbal (ASVP-ESD, non-speech) and verbal (MESD, AESDD, RAVDESS, Emo-DB, CREMA-D) corpora, across multiple languages and varying recording conditions. A uniform five-class emotion schema is enforced to standardize cross-corpus comparison. Frontend encoders include both non-verbal-centric (voc2vec) and speech-centric (wav2vec 2.0, WavLM, MMS-1B) SSL models. Layer-wise temporal CNNs are used for downstream classification.
Results and Analysis
Representation Analysis
Empirical evaluation demonstrates that voc2vec, tailored for non-verbal vocalizations, achieves markedly higher performance in NVV scenarios (e.g., 95.26% accuracy, APD(NV)), while speech-oriented encoders are superior in conventional verbal SER (WavLM, 84.39% on APD(V)). When evaluated on zero-shot non-verbal-to-verbal transfer, voc2vec strongly outperforms speech-centric encoders as a source representation for target verbal datasets, confirming the hypothesis that non-verbal acoustic cues transfer more robustly across languages.
Effect of Hyperbolic Modeling and Domain Alignment
Introduction of hyperbolic modeling (as opposed to Euclidean) in NOVA-ARC produces systematic performance gains across all encoders and target datasets. As an illustrative example, under APD(NV)→APD(V) transfer, NOVA-ARC with voc2vec and hyperbolic geometry achieves 92.40% accuracy (APD(V)), compared to 87.31% for its Euclidean counterpart. The superiority is preserved in noisy environments and across other speech SSL backbones (bold numerical improvements are consistent across datasets).
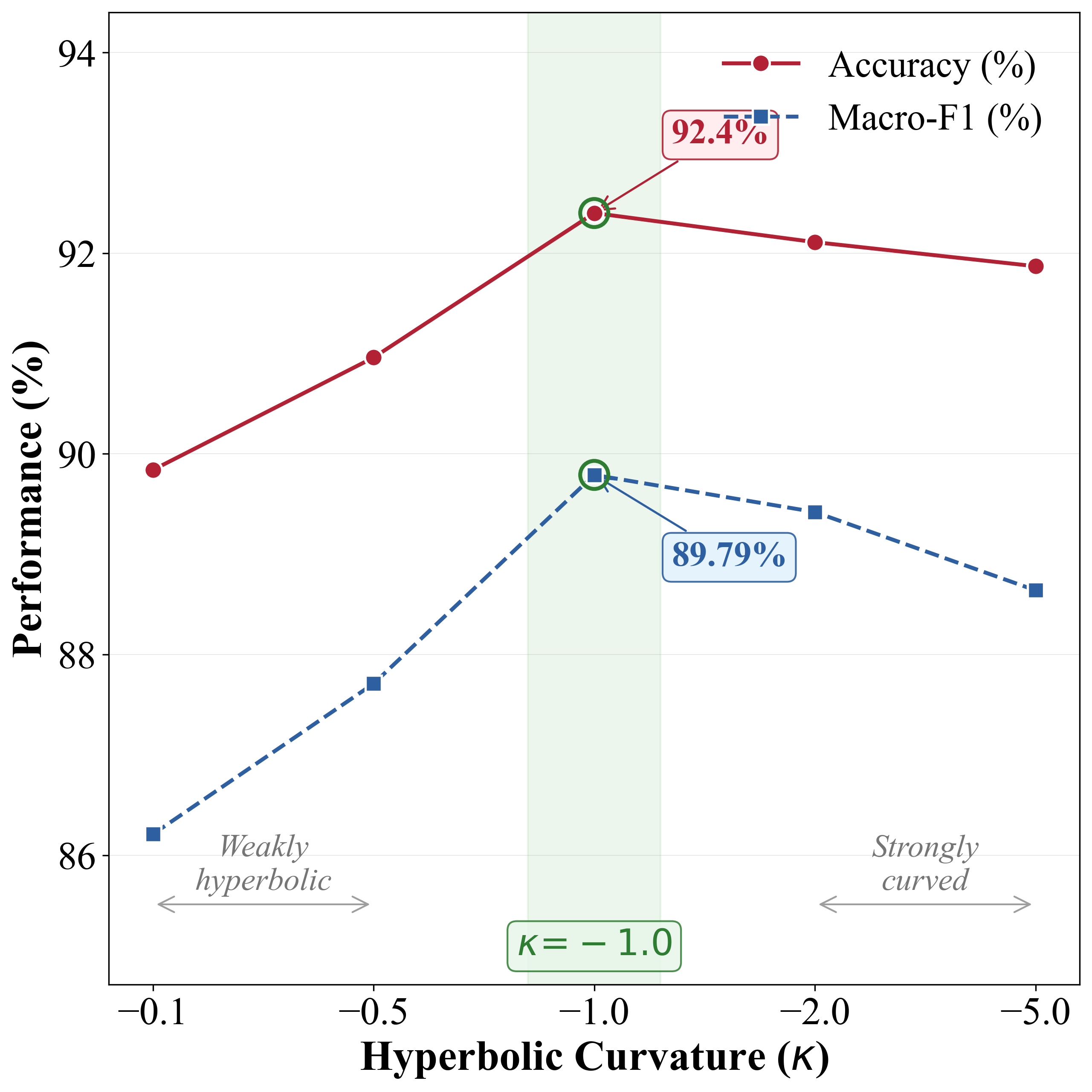
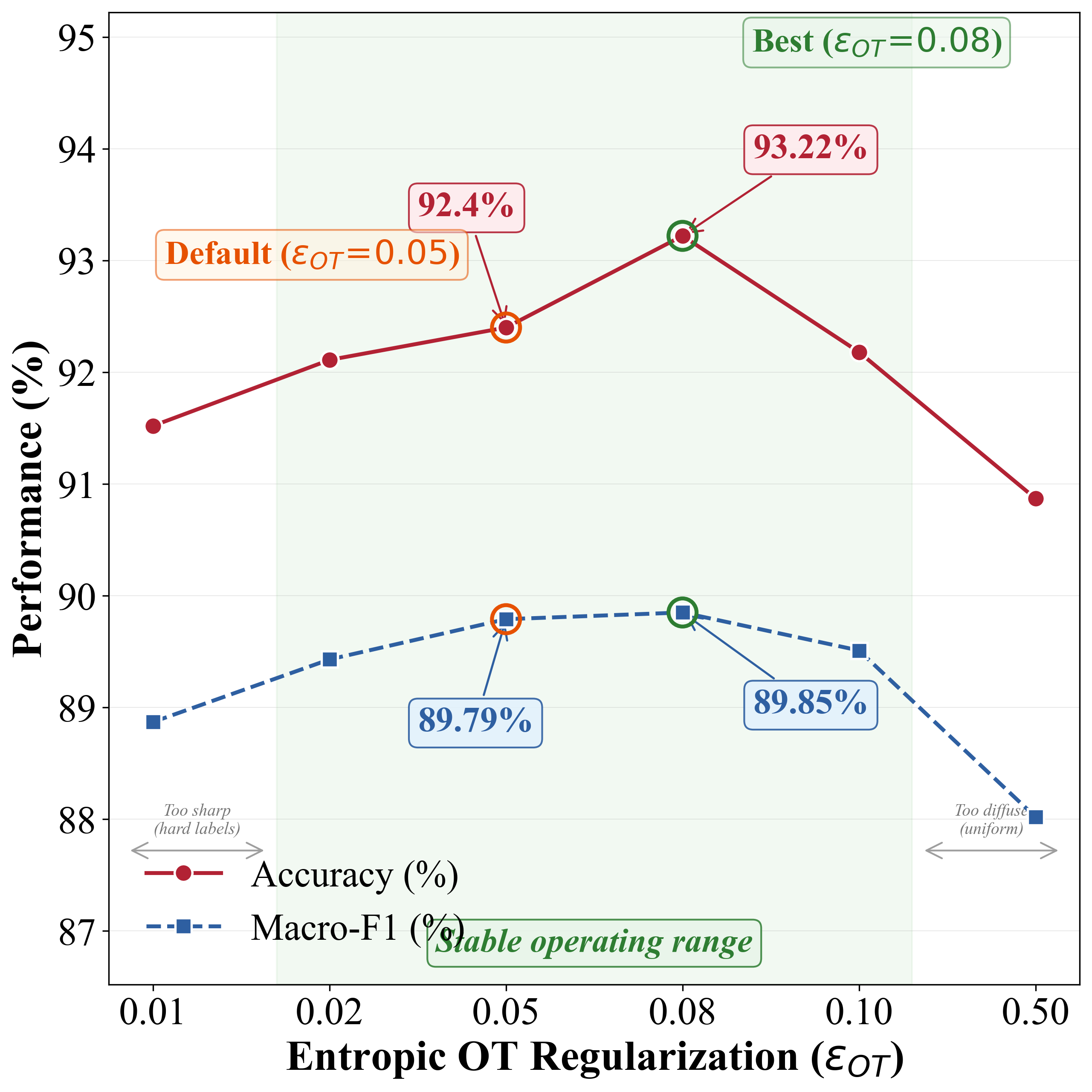
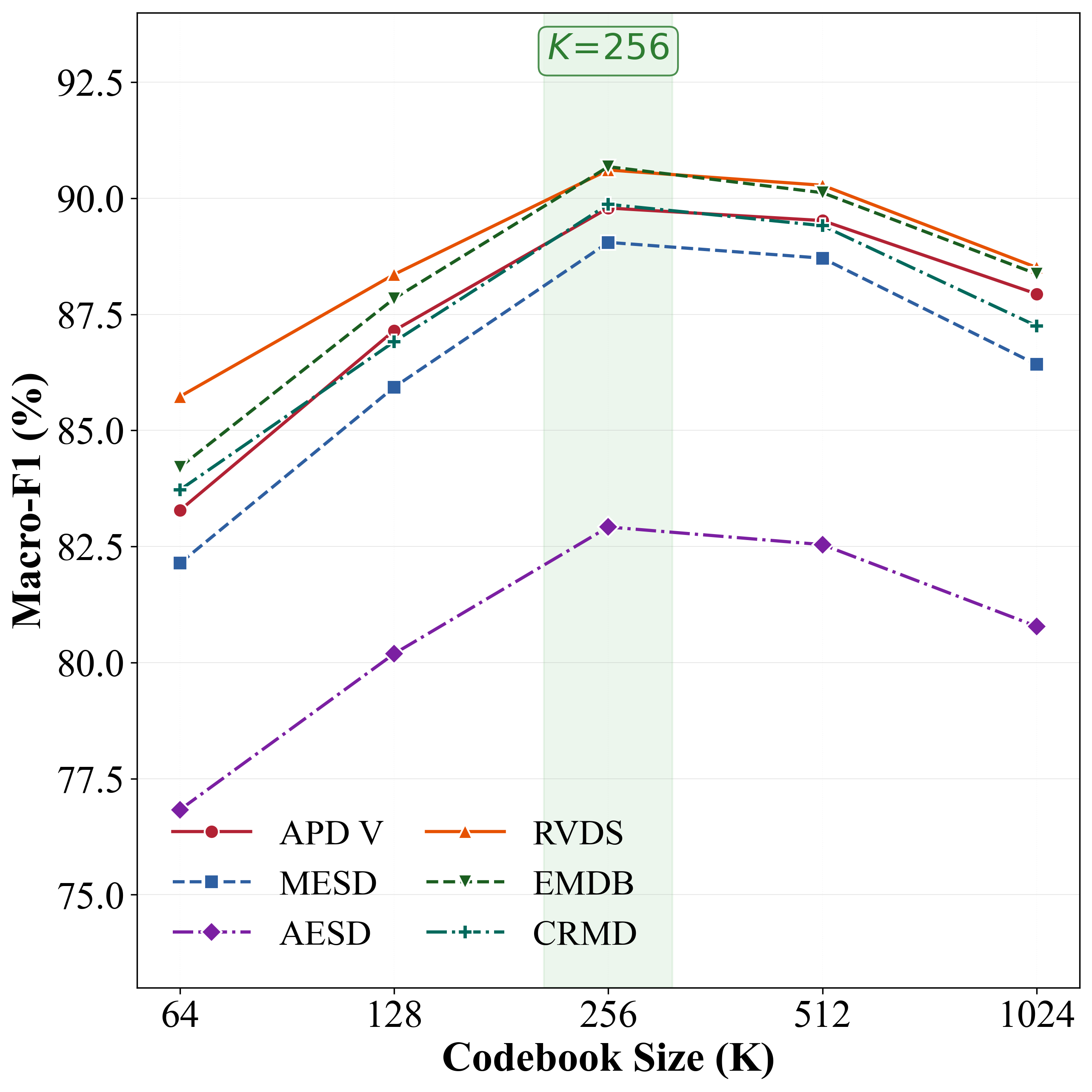
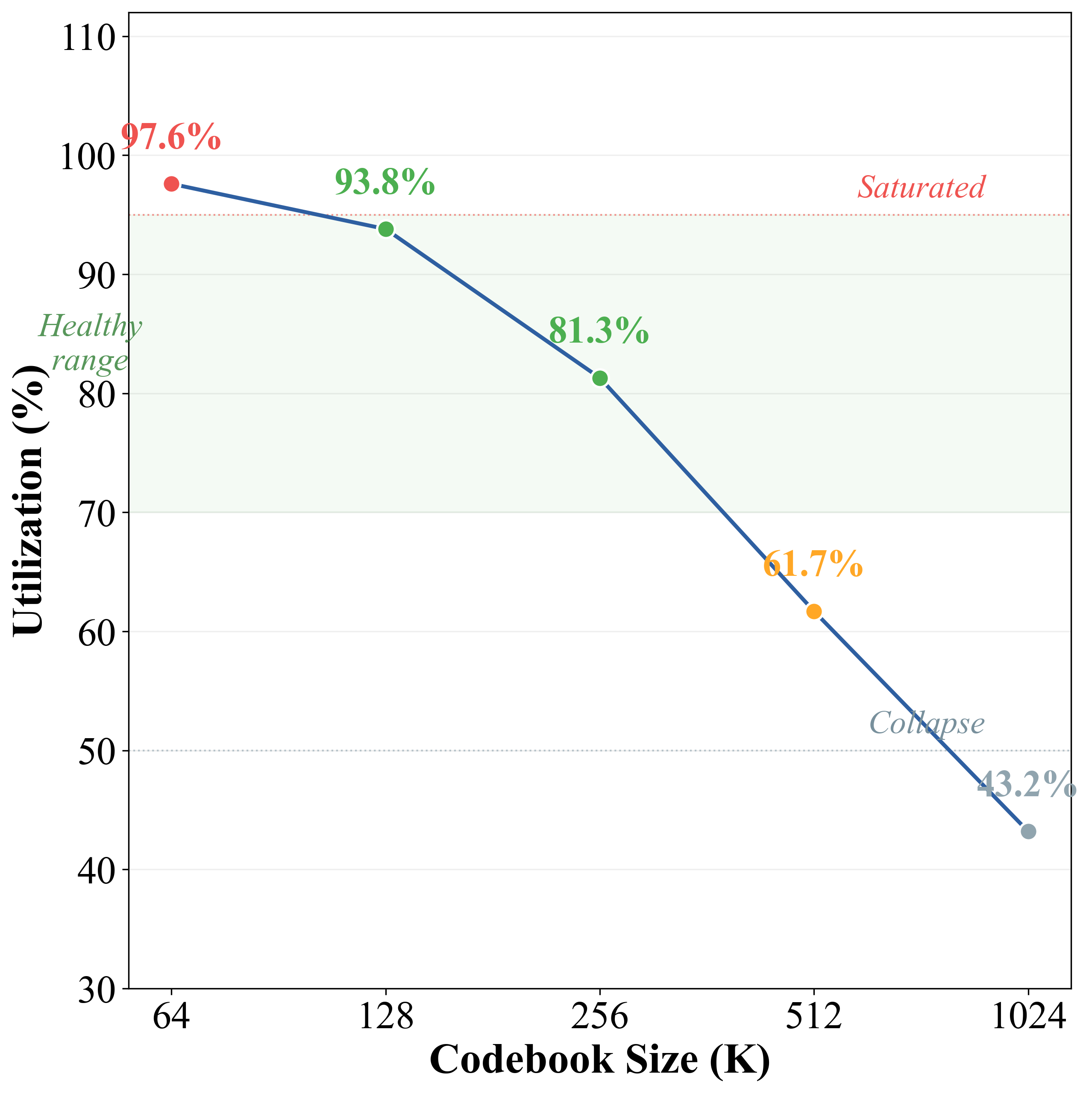
Figure 2: Sensitivity of NOVA-ARC to hyperbolic curvature, entropic regularization, codebook size, and codebook utilization, demonstrating stable performance across a range of hyperparameters.
Ablation studies confirm the necessity of each proposed component: removing hyperbolic geometry, prosody VQ, intensity calibration, or prototype transport, or switching to adversarial or naive OT baselines, all result in substantial performance degradation (e.g., removal of HEL produces a drop from 89.79% F1 to 51.44%; adversarial DA yields only 53.49% accuracy).
Qualitative Analysis
Confusion matrices and t-SNE visualizations further corroborate the architectural advantages: hyperbolic NOVA-ARC yields sharper class separation and reduced error overlap between emotionally similar categories as compared to Euclidean or baseline models.
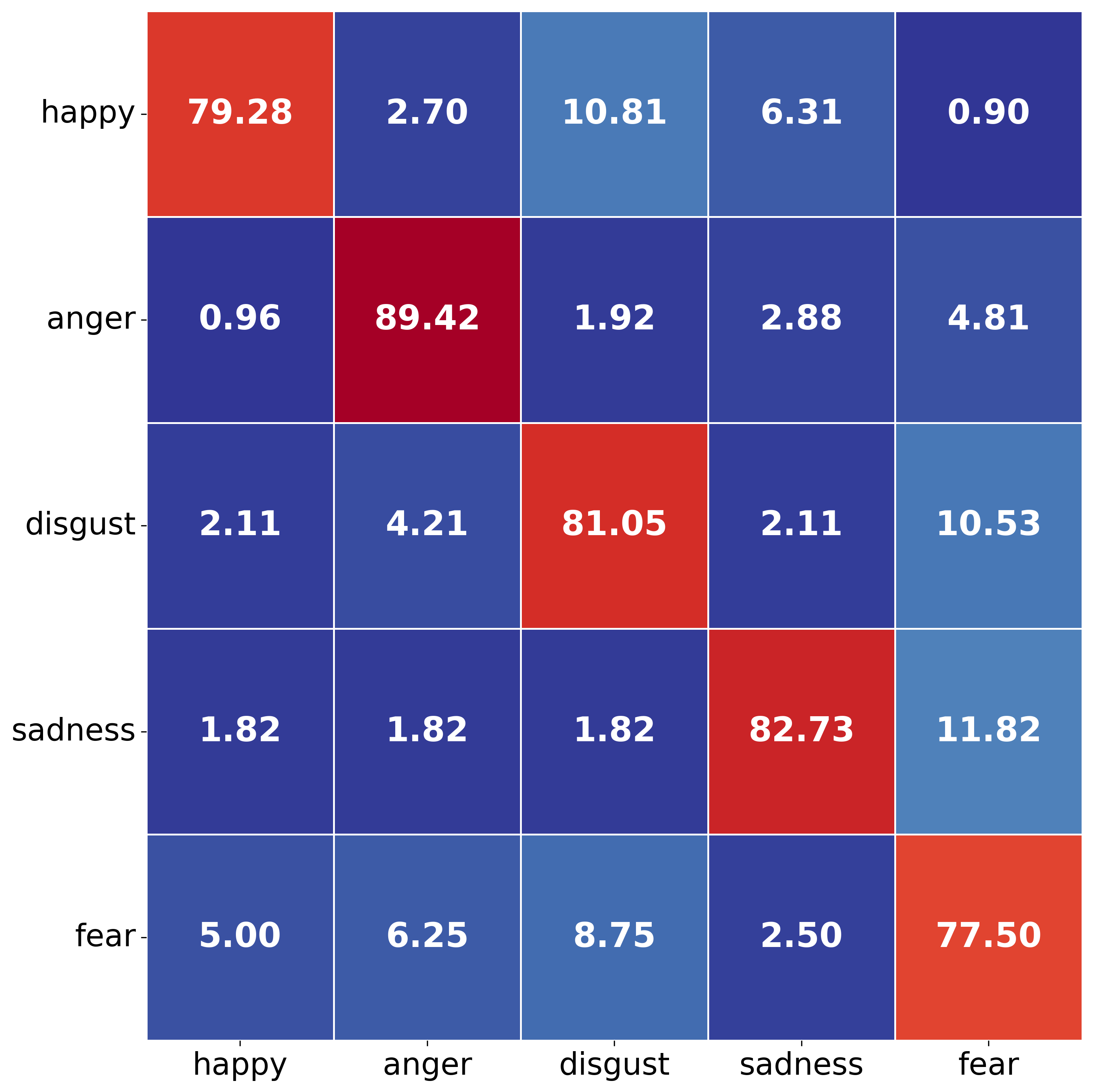
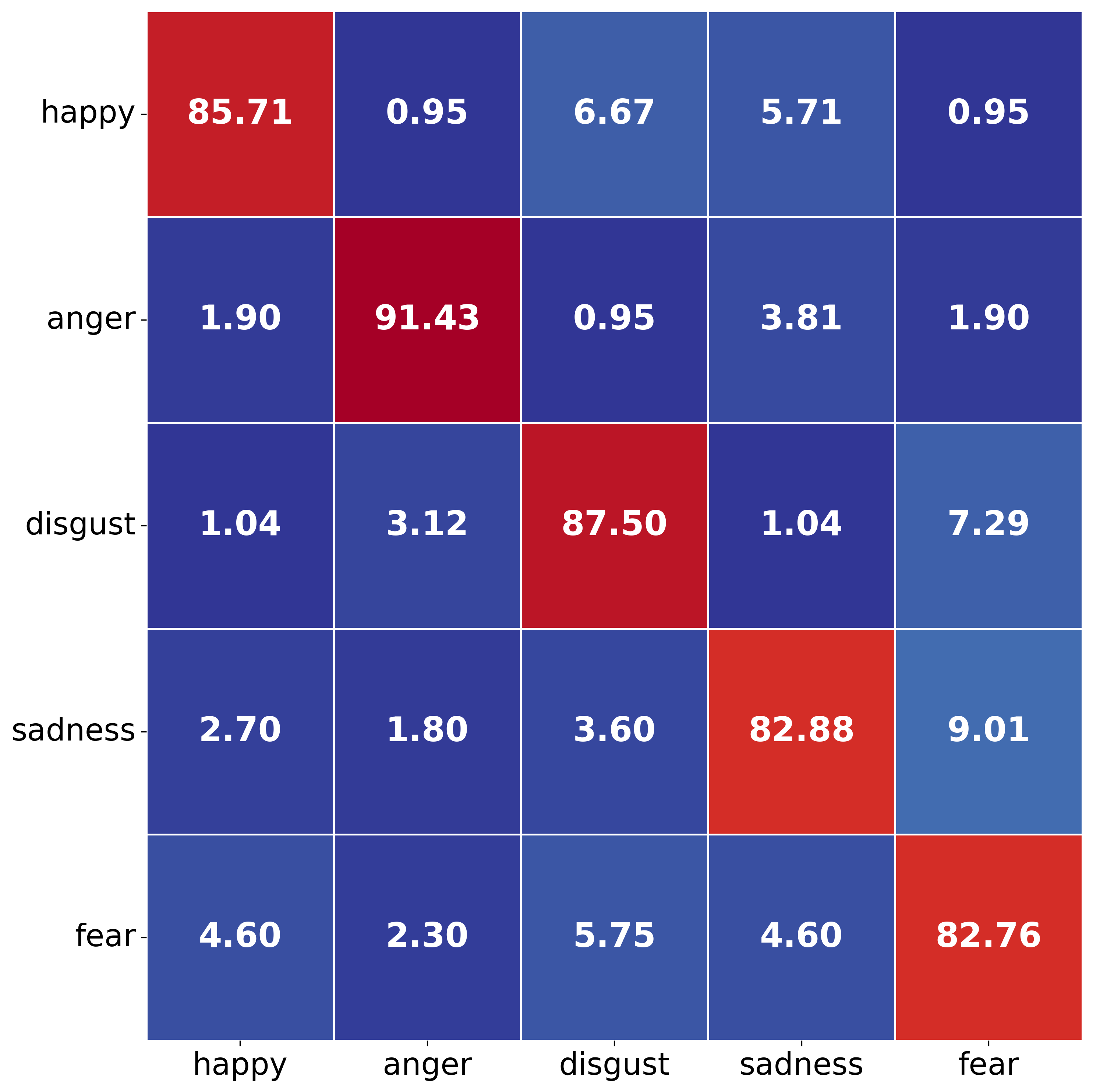
Figure 3: Confusion matrices display improved class discrimination and reduced confusion under hyperbolic domain adaptation in NOVA-ARC across matched and mismatched non-verbal/verbal and Euclidean/hyperbolic settings.
Theoretical Implications and Future Directions
The primary theoretical implication is the validation of non-verbal vocalizations as a universal supervisory signal for multilingual SER, supporting a shift away from dependence on lexically entangled verbal annotation. The work also reinforces the utility of hyperbolic geometry for complex hierarchical affective modeling, suggesting broader application in other paralinguistic or emotion-related cross-domain transfer tasks.
Practically, NOVA-ARC enables scalable, annotation-lite training pipelines for SER in low-resource and minoritized languages, and its modularity allows adaptation to both paralinguistic and traditional semantic tasks. Prosody-aware unsupervised adaptation may also generalize to other spoken communication tasks, such as speaker verification or pathology detection in clinical speech.
Future directions include extending evaluation to spontaneous conversational and multi-speaker dialogue, which introduce overlapping vocalizations and further domain mismatch. Broader application to continuous affective estimation and joint modeling with visual modalities also represent promising research avenues.
Conclusion
This paper introduces a rigorously validated, geometry-aware framework for unsupervised non-verbal-to-verbal transfer in multilingual speech emotion recognition. By exploiting paralinguistic vocalization cues, hyperbolic embedding, and prototype-based optimal transport, NOVA-ARC establishes strong cross-lingual generalization and sets a new baseline for low-resource SER. The findings lay critical groundwork for scalable, cross-domain emotion recognition architectures beyond the constraints of labeled verbal speech and monolingual supervision.
Reference: "Prosody as Supervision: Bridging the Non-Verbal--Verbal for Multilingual Speech Emotion Recognition" (2604.17647)