- The paper introduces HSG, a model that leverages hyperbolic geometry to encode inherent hierarchy by projecting scene entities onto the Lorentz manifold.
- It employs a novel hyperbolic entailment loss and Lorentzian InfoNCE objective, achieving superior PP IoU and Graph IoU metrics compared to Euclidean baselines.
- The approach demonstrates robust hierarchical organization and scalable scene understanding using large-scale self-supervised transformers.
Hyperbolic Scene Graph: Hierarchical Scene Understanding via Hyperbolic Representation Learning
Introduction and Motivation
Scene graph representations constitute the dominant paradigm for structured scene understanding across computer vision, robotics, and embodied AI tasks. Traditional frameworks—including Multiview Scene Graphs (MSG) and their extensions—project visual entities into Euclidean spaces and model semantic relationships via contrastive objectives and attention-based association mechanisms. However, such Euclidean embeddings fundamentally lack inductive bias for explicit hierarchy, limiting their capacity to represent inherent entailment, such as the inclusion of objects within places.
Hyperbolic Scene Graph (HSG) introduces a geometric rethinking of scene representation: by projecting place and object embeddings into the Lorentz model of hyperbolic space, HSG exploits the exponential volume growth and hierarchical geometry to naturally encode place-object entailment. A custom hyperbolic entailment loss further enforces hierarchical constraints, yielding structurally consistent, semantically aligned scene graphs superior to all Euclidean baselines across multiple compositional and structural metrics. This architecture enables HSG to align more closely with the cognitive structures of real-world spatial understanding than prior approaches.
Hyperbolic Representation Learning for Scene Graphs
The core innovation of HSG is the explicit use of the Lorentz hyperbolic manifold as the embedding space for visual scene entities. In this model, each embedding is represented as a point on the upper sheet of an n-dimensional hyperboloid in (n+1)-dimensional Minkowski spacetime. The methodological pipeline proceeds as follows:
- Encoder and Initial Embeddings: A visual backbone (best, DINOv2-Base) extracts features for each detected object and derived place across multiple calibrated image views.
- Hyperbolic Projection: Decoder outputs are projected into the tangent space at the origin of the hyperboloid, then mapped onto the manifold using the exponential map. The time coordinate is computed to ensure manifold consistency (norm constraint: ⟨x,x⟩L=−1/c).
- Contrastive and Entailment Loss: Places and objects are supervised jointly by a Lorentzian InfoNCE objective (negative Lorentzian distance similarity) and a hyperbolic entailment loss, where place embeddings define conic regions, and object embeddings are constrained to be inside the entailment cones of their containing place nodes. This formalizes visual-semantic hierarchy as geometric containment.
- Scene Graph Construction: Hierarchical scene graphs are built by aggregating multi-view associations using geometric and visual consistency, with hyperbolic node and edge features informing both object and relation fusion across viewpoints.
This geometric formulation allows the model to exploit curvature as a critical capacity control parameter. Optimal performance is achieved at curv_init=80, which balances expressiveness and numerical stability (Figure 1).
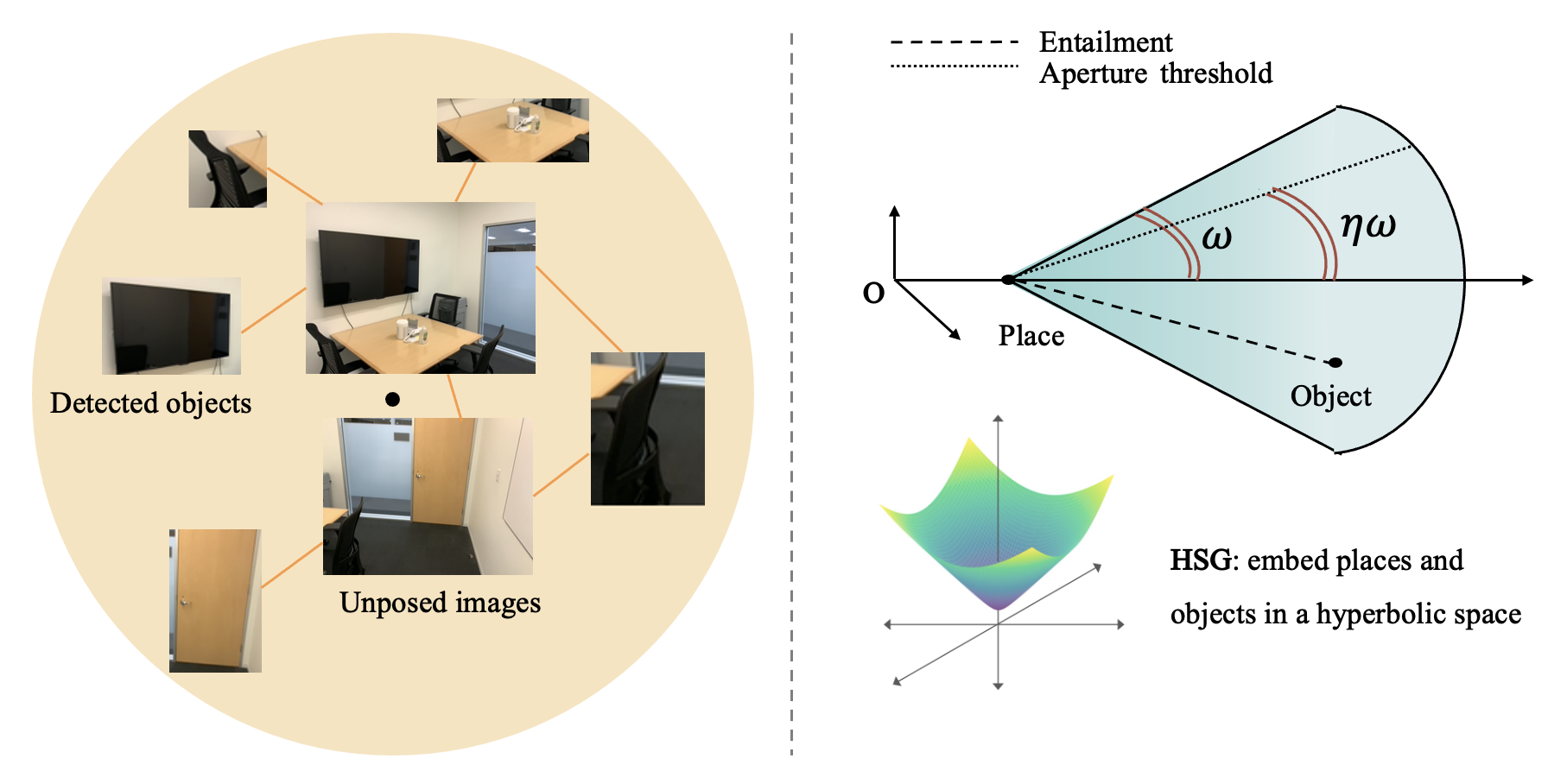
Figure 2: Left—the place-centric hierarchy, placing central scene descriptors as roots with objects as children; Right—hyperbolic entailment cone formulation where cones regulate hierarchical constraints.
Algorithmic Details and Losses
The Lorentz model is selected for its numerical stability and global differentiability (Cartan–Hadamard theorem). Place q and object p embedding entailment is encoded as the requirement that the exterior angle ϕ(p,q) falls within an aperture ω(q) of a hyperbolic cone centered at q:
Lent(p,q)=max(0,ϕ(p,q)−ηω(q))
This geometric regularizer, in conjunction with the Lorentzian InfoNCE, enforces that places (closer to the hyperboloid origin) dominate objects (farther away), implementing semantic entailment as radial separation.
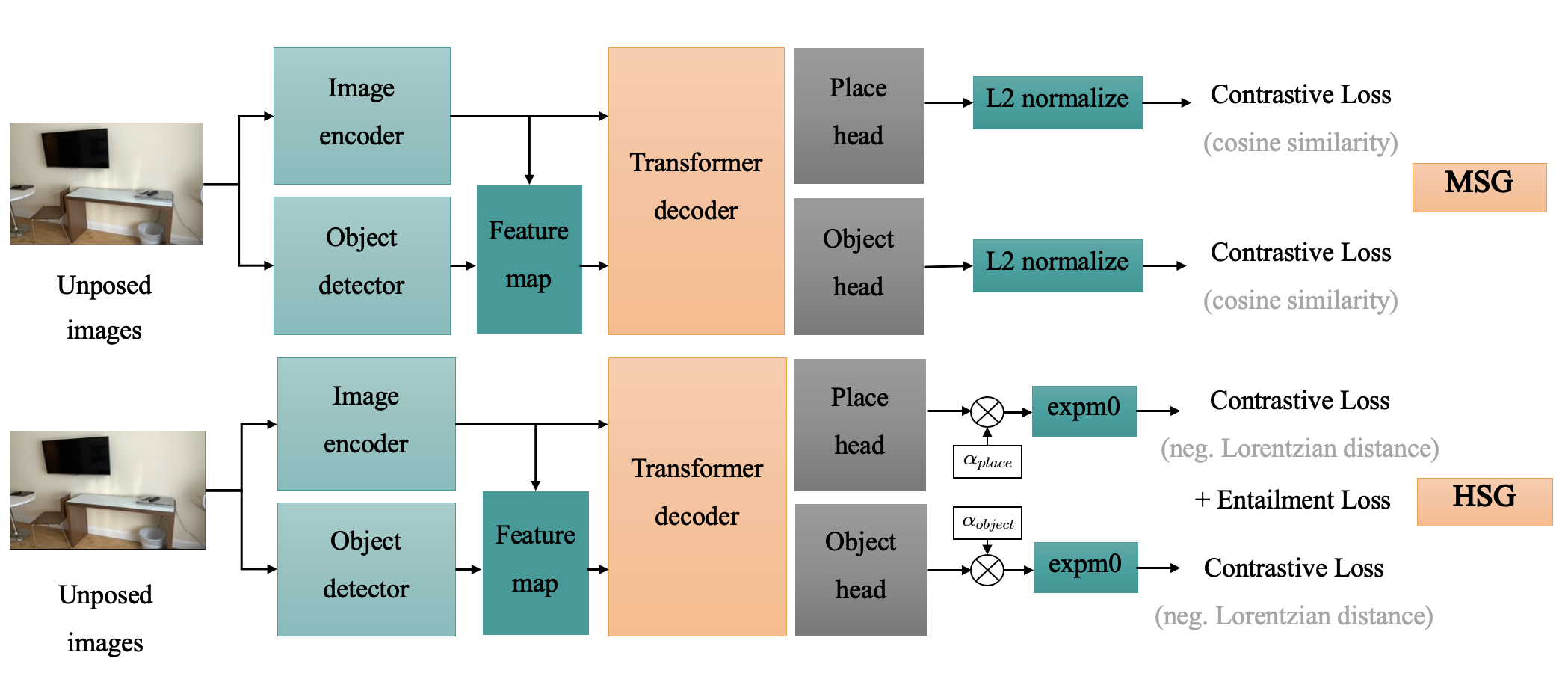
Figure 3: HSG model architecture augmenting MSG with Lorentzian manifold embedding and hierarchical entailment loss.
Contrastive objectives alone are insufficient for structured compositionality, as evidenced by the breakdown of hierarchical metrics when only Euclidean InfoNCE is employed (Table 2). Full HSG recovers strong hierarchy and alignment.
Experimental Results
Quantitative Metrics
Experiments use the ARKitScenes dataset (4.5k training, 200 test scenes), evaluating:
- Recall@1: Place-level retrieval.
- PP IoU: Place-place edge alignment.
- PO IoU: Place-object edge alignment.
- Graph IoU: Overall graph structure alignment.
Key results include:
- HSG achieves PP IoU of 33.17 and Graph IoU of 33.51, outperforming the best Euclidean AoMSG variant by +8.14.
- Place retrieval is maintained at 98.4% Recall@1, indicating that hierarchical enforcement does not compromise instance discrimination.
- Performance is highly robust to aperture threshold (n+1)0 and InfoNCE temperature (n+1)1, with a sweet spot at (n+1)2.
Performance is maximized for projector dimension 1024; lower/redundant dimensions reduce PP IoU.
Curvature learning is essential—curvature fixed at (n+1)3 destroys hierarchical structure (PP IoU (n+1)4 15.5–15.8).
Ablation and Backbone Study
Backbone analysis shows that only large-scale self-supervised transformers (DINOv2-Base) consistently achieve hierarchically structured embeddings—CNNs and smaller ViTs fail to impose the necessary separation.
Ablation studies reveal that removing the entailment loss degrades relational alignment, but the major hierarchical gains arise from hyperbolic projection itself. The full HSG loss stack provides the cleanest compositional split.
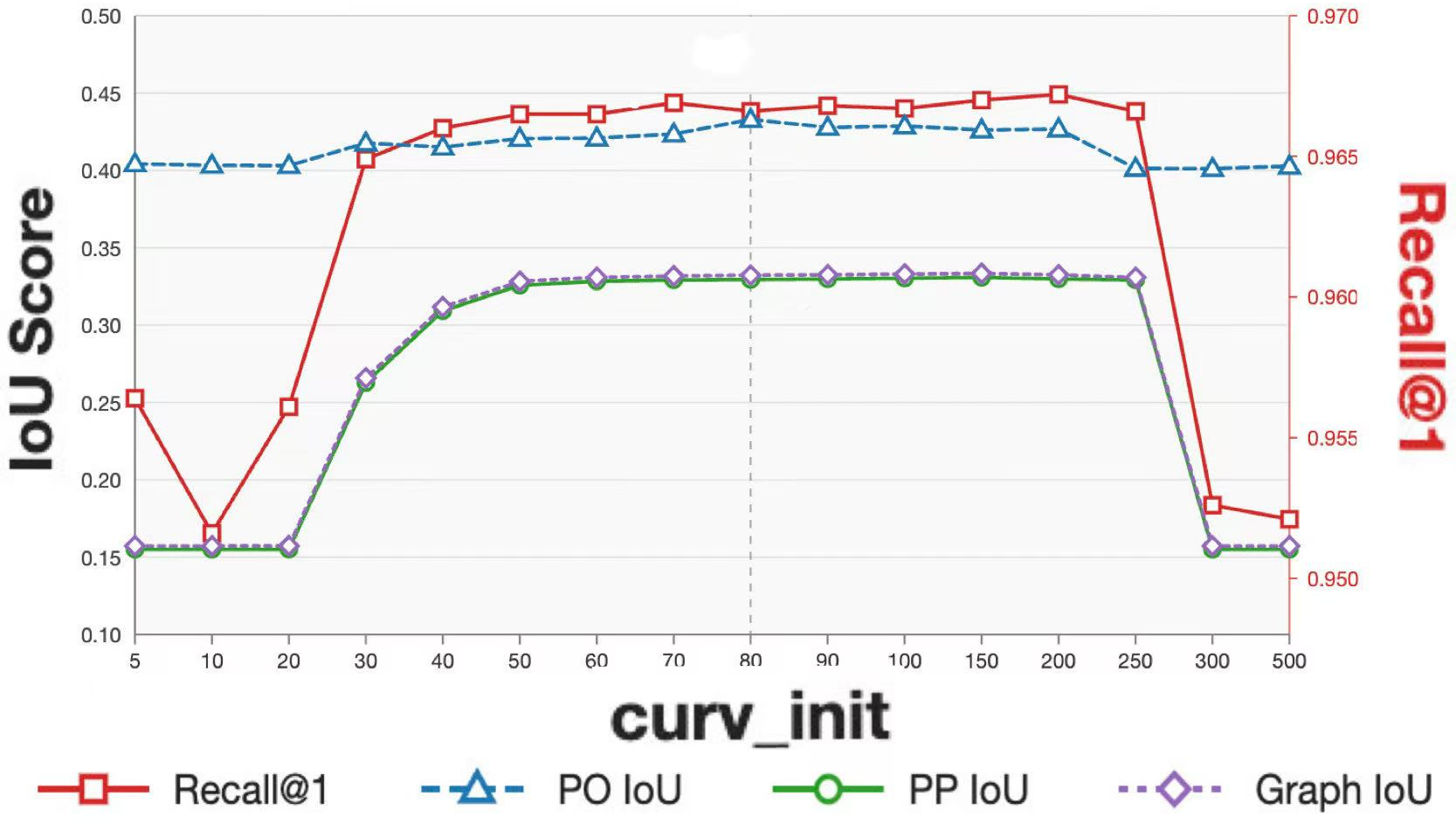
Figure 1: Curvature initialization strongly modulates both retrieval and graph-structure metrics; expressiveness is maximized at (n+1)5.
Qualitative Analysis
Embedding distance distribution visualizations (Figure 4) demonstrate that HSG organizes places and objects radially around the root (hyperboloid origin) in accordance with semantic abstraction—places cluster closer, objects farther. Euclidean baselines lack any meaningful separation.
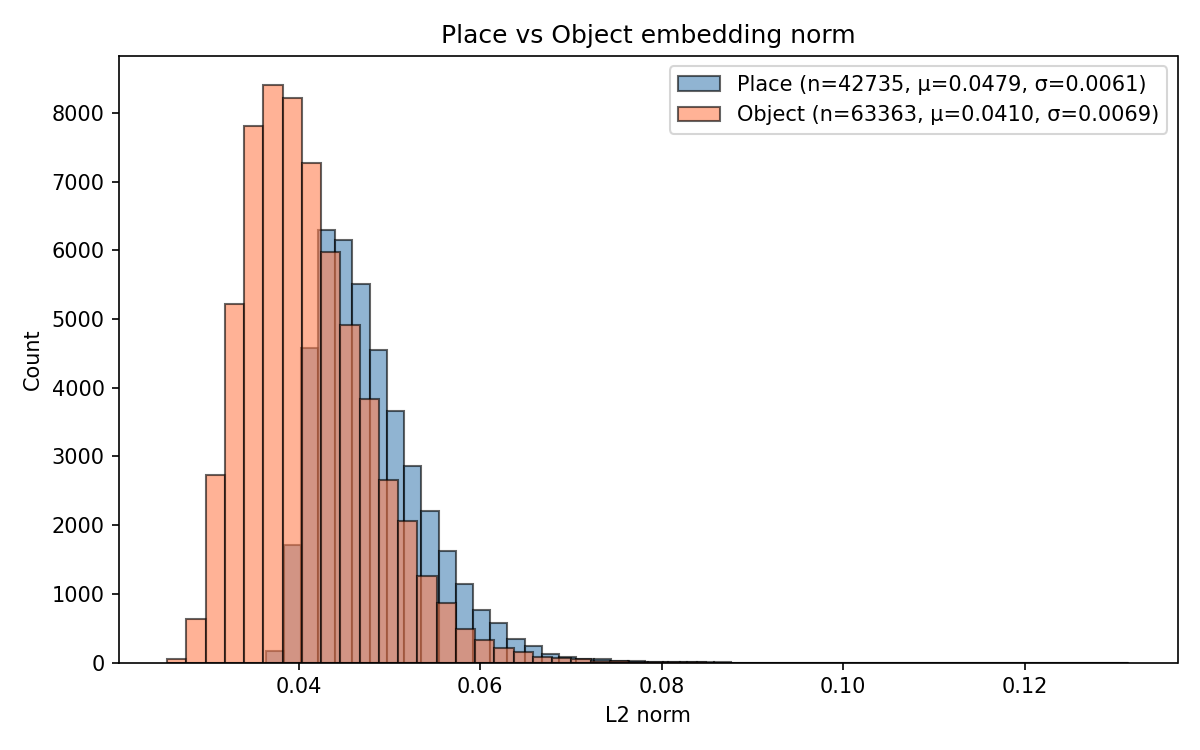
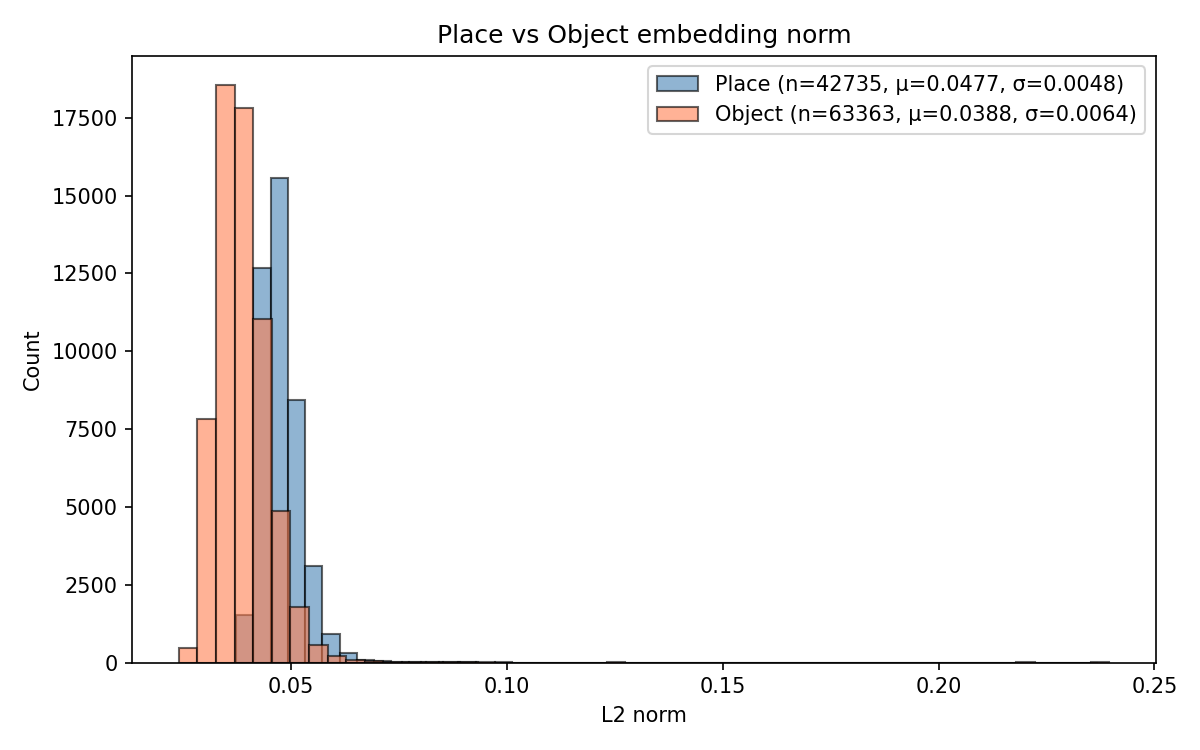
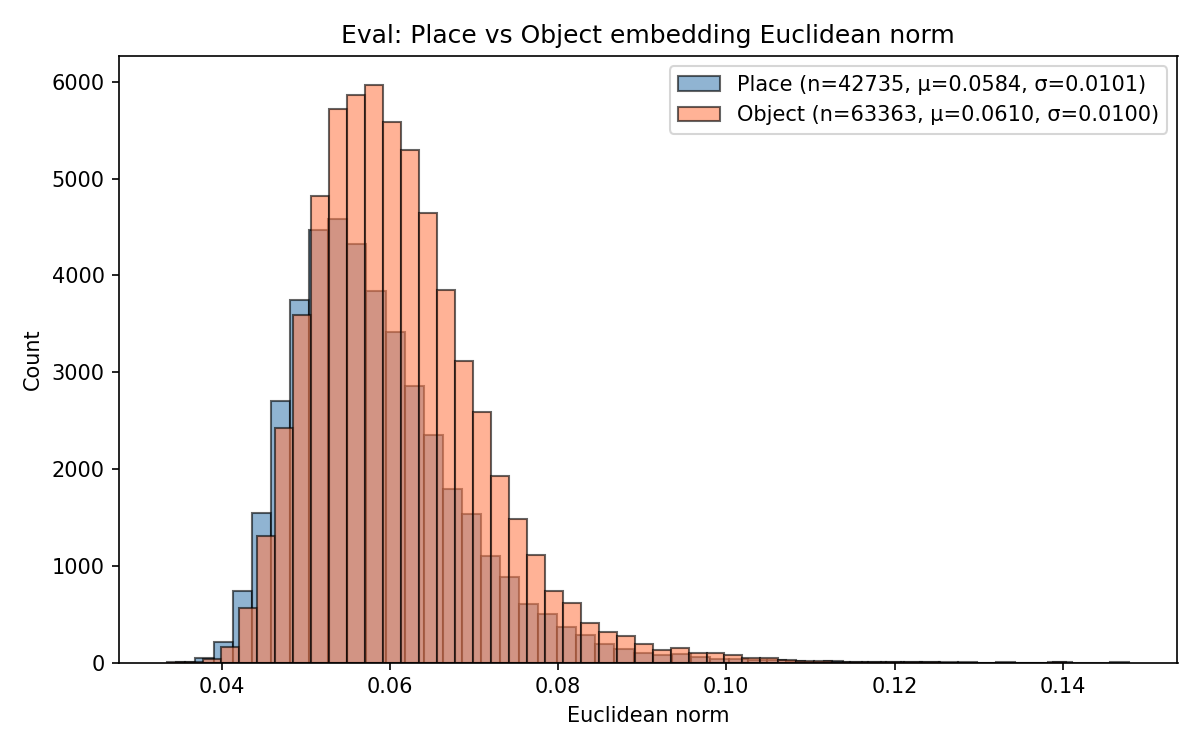
Figure 4: Backbone-dependent distribution of embedding distances from the [ROOT] node in HSG, showing strong hierarchical separation for DINOv2, moderate for ConvNeXt, negligible for ViT.
Real-world video experiments and graph visualizations confirm that HSG generalizes to unseen settings—object and place node assignments are semantically meaningful and robust to view changes.

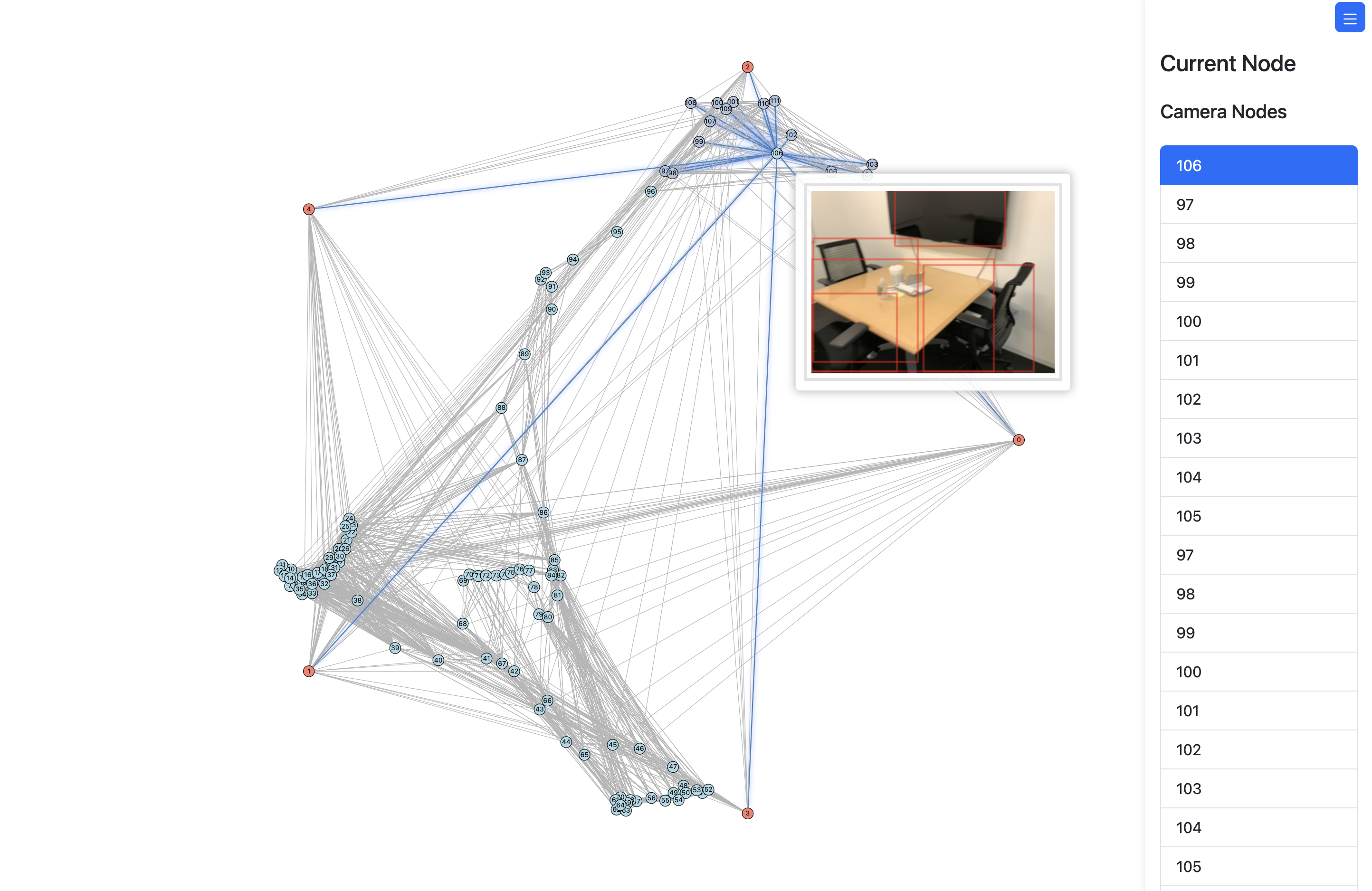
Figure 5: Top—object detections; Bottom—interactive graph visualization with blue (place) and orange (object) nodes.


Figure 6: Place node visualization—triplets correspond to the same physical location aggregated via MSG.


Figure 7: Consistent grouping of multi-view object detections into single object nodes, color-coded per instance.
Implications and Future Directions
HSG provides the first operational demonstration that hyperbolic geometry can be used to encode scene hierarchy directly in visual embedding spaces, improving both compositional semantics and global structure without sacrificing instance-level accuracy. This conclusion is robust across model backbones, input configurations, and dataset settings.
The theoretical implication is that hierarchical representation learning for vision should be decoupled from purely metric learning approaches: explicit curvature and entailment constraints are necessary for compositional structural consistency.
Potential future work includes:
- Adaptive multi-stage curvature optimization to model non-uniform geometric structures and diverse spatial hierarchies.
- Integration with open-vocabulary/grounded detectors (e.g., DINOv3, GroundingDINO), and scaling to larger, more diverse datasets and tasks, e.g., embodied reasoning, question answering.
- Multimodal extension—joint optimization for image-text or temporal information could unlock new state-of-the-art in graph-based scene understanding.
Conclusion
HSG demonstrates that hyperbolic projection and entailment-aware constraints markedly improve the semantic and structural quality of scene graphs. By leveraging the geometric advantages of the Lorentz hyperboloid, HSG advances the formalization of compositional hierarchy in machine-perceived visual environments beyond what is achievable with classical Euclidean embeddings. This work establishes hyperbolic scene graph representations as a structurally superior alternative for scalable, geometry-aware visual reasoning.

