- The paper presents a dual-resolution, attention-fusion deep learning model that uses CORAL ordinal regression to accurately grade diabetic retinopathy.
- It leverages both global and local imaging features with EfficientNet-B0 and B3 backbones and employs specialized normalization techniques to enhance robustness.
- Experimental results show high in-domain performance and highlight persistent cross-dataset generalization challenges, indicating avenues for future domain adaptation.
Robust Dual-Resolution Attention-Based Deep Learning with Ordinal Regression for Diabetic Retinopathy Grading
Introduction
The paper "Robust Diabetic Retinopathy Grading Using Dual-Resolution Attention-Based Deep Learning with Ordinal Regression" (2604.17341) addresses the persistent challenge of developing automated diabetic retinopathy (DR) grading systems that achieve high reliability across heterogeneous retinal fundus imaging domains. While prior convolutional neural network (CNN)-based approaches have demonstrated elevated performance on single-source datasets, their generalization to external datasets remains insufficient due to domain shifts induced by image acquisition variability, variations in lighting, device heterogeneity, and pre-processing differences. To mitigate this, the proposed framework integrates three orthogonal components: dual-resolution input encoding, attention-guided feature fusion, and an ordinal regression head based on the CORAL loss, with an explicit focus on cross-dataset robustness.
Methodology
Dataset Configuration and Preprocessing
The approach employs the APTOS 2019 dataset for model training and stratified validation, while Messidor-2 acts as an external testbed for generalization. Fundus images are annotated with DR severity on a 5-grade ordinal scale. The paper conducts rigorous preprocessing: circular cropping for non-retinal region isolation, parallel enhancement via Ben Graham normalization and CLAHE to emphasize complementary structural and textural features, and histogram matching to partially align inter-dataset intensity statistics. Data augmentation is used exclusively for training, maintaining clean validation and testing protocols.
Figure 1: Sample fundus images from each DR severity label (grades 0--4).
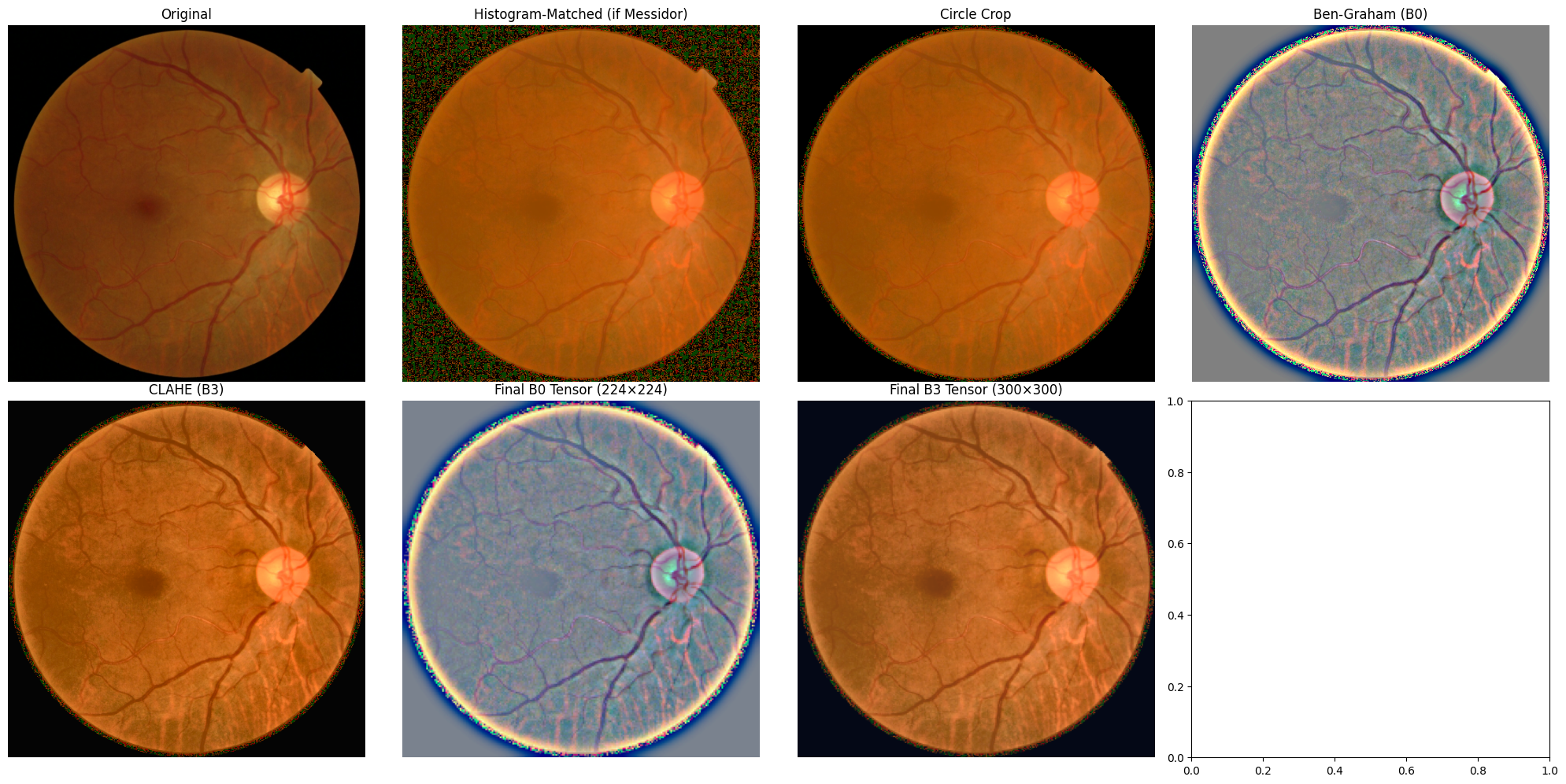
Figure 2: Visualization of the preprocessing pipeline for APTOS and Messidor-2 images.
Dual-Resolution Architecture and Attention Fusion
The model's architecture bifurcates the preprocessing stream. Images normalized with Ben Graham are input to an EfficientNet-B0 backbone at 224×224 resolution to capture global contextual features, whereas CLAHE-enhanced images feed into EfficientNet-B3 at 300×300 to emphasize fine-grained, local pathological clues. The feature projections are then concatenated and fused through a squeeze-and-excitation-based attention mechanism, which dynamically gates the contributions of each spatial branch per sample, enabling adaptive use of multi-scale information in the presence of variable lesion size and contrast.
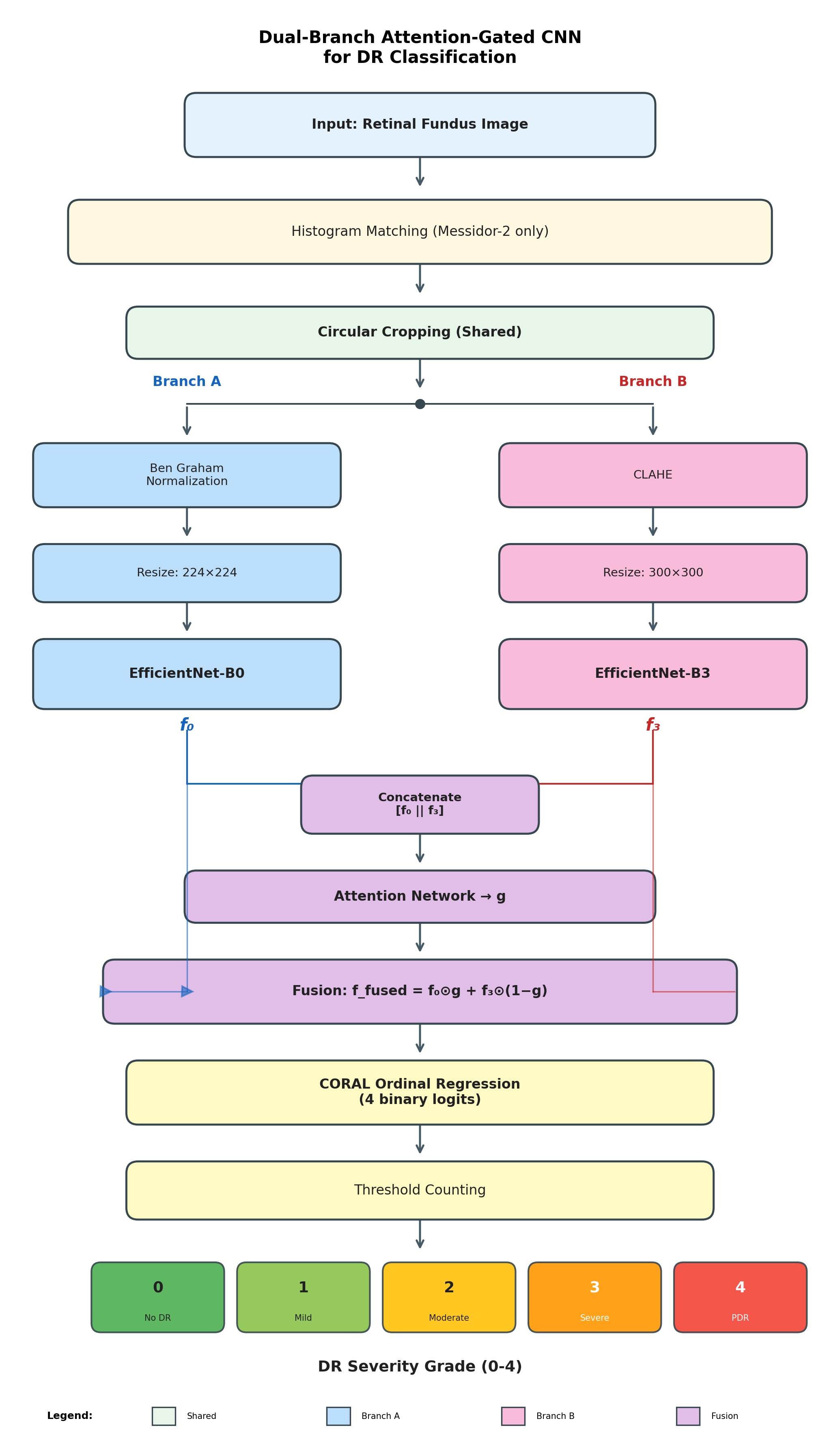
Figure 3: Architecture of the proposed dual-resolution attention-based framework for diabetic retinopathy grading.
Ordinal Regression via CORAL
The fused feature representation is processed by a fully connected ordinal regression head implementing CORAL, producing K−1=4 binary logits corresponding to the five DR severity classes. Unlike cross-entropy loss, CORAL enforces label monotonicity and penalizes large ordinal mis-rankings more heavily. The model's predictions thus reflect the hierarchical structure of clinical DR grading and commonly err on adjacent grades rather than manifesting large grade mismatches.
Experimental Results
Training Dynamics
Training on the combined APTOS and partial Messidor-2 datasets for 10 epochs, the model optimized CORAL loss with Adam at a learning rate of 10−4, employing class-balanced sampling. Training convergence was monotonic, with quadratic weighted kappa (QWK) on APTOS validation ascending from 0.72 to over 0.97 as training progressed. Model selection was governed by maximum QWK on the internal validation set.
In-Domain and Cross-Domain Grading
The framework attained QWK of 0.88 on APTOS validation, indicating a high degree of agreement with human annotation. Most classification errors were single-level confusions—e.g., mild vs. moderate—reflecting clinically acceptable ordinal deviations. Testing on Messidor-2 yielded QWK of 0.68, a tangible drop attributed to incomplete resolution of domain shift despite histogram alignment and limited exposure to Messidor-2 during training. Confusion matrices (see Figure 4) further demonstrated that the majority of errors remained local to severity boundaries, affirming the clinical alignment of predictions enabled by ordinal regression.
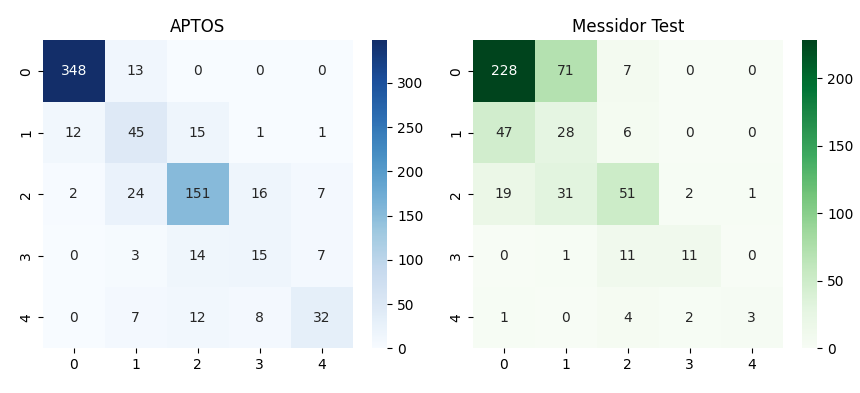
Figure 4: Confusion matrix (top) and training loss / QWK curves (bottom) on both APTOS and Messidor-2 datasets.
Analysis and Discussion
The key technical advances are: (1) the use of dual-resolution branches to optimally extract both global and local lesion features; (2) an architecture with attention-guided late fusion that adaptively leverages preprocessing variations for robust feature modeling; and (3) ordinal regression via CORAL that enforces label monotonicity and aligns loss with clinical severity perception. The strict separation of training and external testing sets imposes a rigorous evaluation standard rarely adopted in related literature, offering a more realistic assessment of domain robustness.
Quantitative results on Messidor-2 highlight persistent limitations in cross-domain reliability, consistent with other recent surveys. Even with advanced histogram matching, remaining distributional shifts are nontrivial, suggesting room for adversarial domain adaptation, representation disentanglement, or direct incorporation of unlabeled external data via semi-supervised or domain generalization paradigms.
The framework was trained exclusively on image-level labels due to limited lesion-level annotation availability, leaving potential gains from weakly- or semi-supervised localization unexplored. Integration with lesion attention masks or region-level supervision could plausibly improve the network's ability to focus on subtle, clinically relevant features.
Implications and Future Prospects
This dual-resolution, attention-based, ordinal model establishes a new baseline for cross-dataset DR grading, emphasizing the necessity of both architectural and loss-function alignment with clinical task structure. The explicit handling of ordinal ambiguity and multi-scale information is likely extensible to other grading tasks in medical imaging with similar hierarchical class structure and distributional variability. The performance gap between in-domain and cross-domain settings underscores the critical need for continued investment in robust domain adaptation strategies.
Areas for immediate future research include adversarial training for explicit feature-invariant learning across domains, transfer learning leveraging larger multi-center datasets, and integration of interpretability modules for clinical acceptability. Extending validation to non-public, multi-hospital datasets, including data from emerging imaging modalities, would further establish the practical clinical value of the method.
Conclusion
The paper presents a systematic approach to DR severity grading using a dual-resolution, attention-based fusion architecture trained with ordinal regression, explicitly calibrated for generalization under domain variation (2604.17341). The model achieves state-of-the-art QWK on internal data and demonstrates improved, though not fully domain-invariant, robustness to external data, marking progress towards clinically viable, generalizable DR screening. Further focus on advanced domain generalization and richer supervision will be required to fully bridge the real-world deployment gap.