- The paper introduces a residual-statistic-gated low-rank adaptation method that integrates Laplacian residuals with frozen Vision Transformers to amplify forensic facial cues.
- It achieves significant performance gains with Detection Equal Error Rates as low as 4.00% on challenging cross-dataset evaluations compared to state-of-the-art S-MAD baselines.
- The approach is computationally efficient, resilient to common image degradations, and suitable for real-time biometric security applications.
R-FLoRA: Residual-Statistic-Gated Low-Rank Adaptation for Robust S-MAD
Problem Definition and Motivation
Automated border and identity verification systems employing facial recognition are fundamentally vulnerable to face morphing attacks—images fabricated by blending facial data from two or more individuals such that the resulting artifact is accepted as both contributors during authentication. The threat is pronounced in Single-Image Morphing Attack Detection (S-MAD), where only the probe image is available, precluding reference comparisons as in differential protocols. Morph generation methods have diversified, including landmark-based, GAN-, and diffusion-based approaches, resulting in substantial variance in morph signatures. Existing S-MAD architectures struggle with cross-dataset generalization and deteriorate notably when confronted with previously unseen morphing algorithms or data distributions.
Methodological Framework
The proposed R-FLoRA method introduces a residual-statistic-gated low-rank adaptation of frozen foundation-scale Vision Transformers (ViTs), specifically leveraging the high-capacity CLIP ViT-L/14 backbone. The architecture integrates two parallel processing streams: one extracting hierarchical semantic features with a frozen ViT, and another isolating high-frequency morphing artifacts using Laplacian residuals.
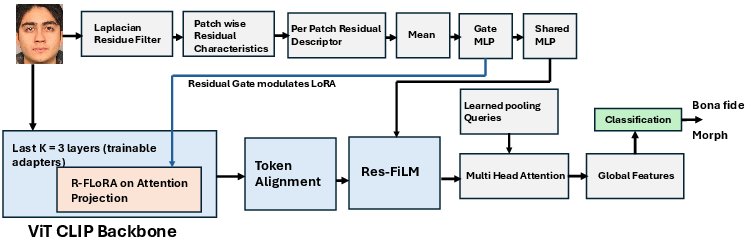
Figure 1: Schematic of the R-FLoRA pipeline integrating frozen ViT backbone with Laplacian-based residual-statistic-gated adapters and feature-wise fusion modules.
A summary of core modules:
- Frozen ViT Backbone: All transformer parameters remain frozen, preserving large-scale pre-trained representations.
- Laplacian Residual Branch: Each image is decomposed into local patches, with per-patch high-frequency Laplacian statistics (mean, variance, energy) extracted to form residual descriptors. These serve as sample-specific forensic cues.
- Residual-Statistic-Gated Low-Rank Adaptation (R-FLoRA): Lightweight low-rank adapters augment the Q, V projections—in the last k transformer layers—with a scalar gate derived from global Laplacian residual statistics, enforcing per-image conditional modulation without sacrificing the semantic integrity of foundation features.
- Feature-wise Linear Modulation (Res-FiLM): A shared MLP computes per-token affine modulation parameters from patch-level residual descriptors; these modulate spatially aligned backbone tokens, injecting localized artifact sensitivity.
- Cross-Attention Pooling Head: Fused tokens are adaptively aggregated using a learned query bank to focus on patches with salient residual artifacts, before passing to a binary classifier.
- Residual-Contrastive Alignment Loss (RCA): An auxiliary alignment loss regularizes the distance between residual-conditioned and baseline tokens, aligning them for bona fide images and enforcing separation for morphs, mitigating overfitting and promoting robustness to domain shift.
Datasets and Experimental Protocol
Comprehensive cross-dataset evaluation was performed using four ICAO-compliant databases: FERET, FRGC, FRILL, and MS40, spanning seven morph generation techniques (landmark-based, post-processed, MIPGAN-1/2, diffusion autoencoder, PIPE, Greedy-DiM). Notably, both training and validation are performed on separate datasets (MD#1 and MD#2) with evaluation exclusively on disjoint MD#3 and MD#4, ensuring that models are assessed on genuinely novel distributions.

Figure 2: Representative bona fide and morph samples from four ICAO-compliant datasets across seven morphing techniques.
Results and Numerical Analysis
The approach yields consistently superior Detection Equal Error Rates (D-EER) and Bona Fide Sample Classification Error Rates (BSCER) compared to nine recent S-MAD baselines, including diffusion-based (DDPM), self-supervised, transformer, teacher-student distillation, few-shot, ensemble, and prior CLIP-based methods. For instance, on MD#3 (Train: MD#1; Val: MD#2), D-EER was reduced to 7.14% ± 0.45 while all competitors exceeded 12.74%, some surpassing 50%. When trained on MD#2 and validated on MD#1, the D-EER on MD#3 drops even further to 4.00% ± 1.23.
Crucially, the model maintains resilience to realistic image degradations (blur, noise, JPEG compression), with only moderate error inflation under severe perturbation regimes. For moderate degradation, such as JPEG quality factors >50 or Gaussian noise SNR >20 dB, EER remains below 12%.

Figure 3: Detection robustness visualization under varying Gaussian blur severity at test time.

Figure 4: Evaluation under increasing additive Gaussian noise (SNR from 30dB to 10dB).

Figure 5: Performance impact of progressive JPEG compression, showing robustness at practical quality levels.
Ablation studies confirm that the combination of (1) residual gating of adapters, (2) concurrent Q/V adaptation in the terminal three transformer layers, and (3) inclusion of RCA regularization is essential for optimal performance; deviation or omission sharply elevates error rates.
Architectural Implications and Theoretical Insights
The decisive empirical advantage is directly attributable to the explicit fusion of interpretable, high-frequency forensic descriptors with invariant, foundation-scale transformer representations. R-FLoRA’s per-image, residual-driven gating ensures that adaptation occurs only if warranted by the presented forensic footprint, effectively suppressing over-specialization to spurious dataset characteristics. The modular, low-rank design affords extension to alternative large-scale visual backbones (e.g., DINOv2, DINOv3) and is computationally efficient, requiring <2.1% of the backbone’s parameter count for training.
The RCA objective materially improves cross-domain stability by regularizing the embedded space such that local sculpting for morphs does not disrupt backbone alignment for bona fide images. The design is robust to mode collapse in generator-based attacks and addresses prior S-MAD limitations in interpretability by exploiting a spatially structured, semantically meaningful residual signal.
Practical Deployment and Future Directions
The method is real-time capable (13 ms per image on high-end GPUs) and supports half-precision inference, making it deployable in operational biometric systems and border control settings. The system’s resilience to standard image processing perturbations underlines its appropriateness for digital workflows and centralized document verification, where compression and mild corruption are routine but catastrophic degradations are rare.
Future work should benchmark performance against deliberately engineered, adversarial morphs that jointly suppress Laplacian and transformer cues, and in workflows involving print/scan channels, mobile capture, and other modality shifts. Broader sensor, temporal, and meta-data integration is a viable path toward even more robust S-MAD, as is detailed interpretability using token attribution or layer-wise relevance propagation.
Conclusion
R-FLoRA substantively advances S-MAD by operationalizing dynamic, residual-statistic-driven low-rank adaptation over frozen foundation model backbones. The integration of Laplacian-based forensic cues, adaptive fusion, and residual-contrastive regularization sets a new standard for cross-dataset generalization, robustness to morphing diversity, and operational suitability in real-world biometric security pipelines.

