- The paper introduces TRACE, a training-free framework that aggregates multi-step answer consistency and confidence trajectories to determine optimal early exit.
- The method reduces token usage by 25-30% while maintaining accuracy within 1-2% across diverse mathematical and scientific reasoning benchmarks.
- By moving beyond single-step confidence signals, TRACE minimizes overthinking and premature exits, ensuring robust convergence in LLM reasoning.
Efficient Test-Time Scaling via Temporal Reasoning Aggregation
Introduction and Motivation
Test-time scaling has become the de facto paradigm for enhancing the reasoning ability of LLMs on complex tasks such as mathematical problem solving and code generation. The prevalent approach leverages extended chain-of-thought (CoT) reasoning, which dramatically increases inference-time compute by generating considerably longer reasoning traces and exploring alternative deduction paths. This practice consistently boosts accuracy but incurs substantial token and computational overhead, leading to "overthinking" where models continue unnecessary deliberation far beyond the point of answer correctness.
Existing dynamic early-exit strategies predominantly rely on single-step confidence signals to decide when to terminate inference. However, recent empirical evidence reveals that such instantaneous signals are unreliable for multi-step reasoning, often causing either premature exit (yielding wrong answers despite high confidence) or excessive token consumption. This limitation arises because reasoning convergence is fundamentally temporal and not always indicated by local confidence spikes. As illustrated below, naive single-step approaches are susceptible to halting on incorrect answers (Figure 1).
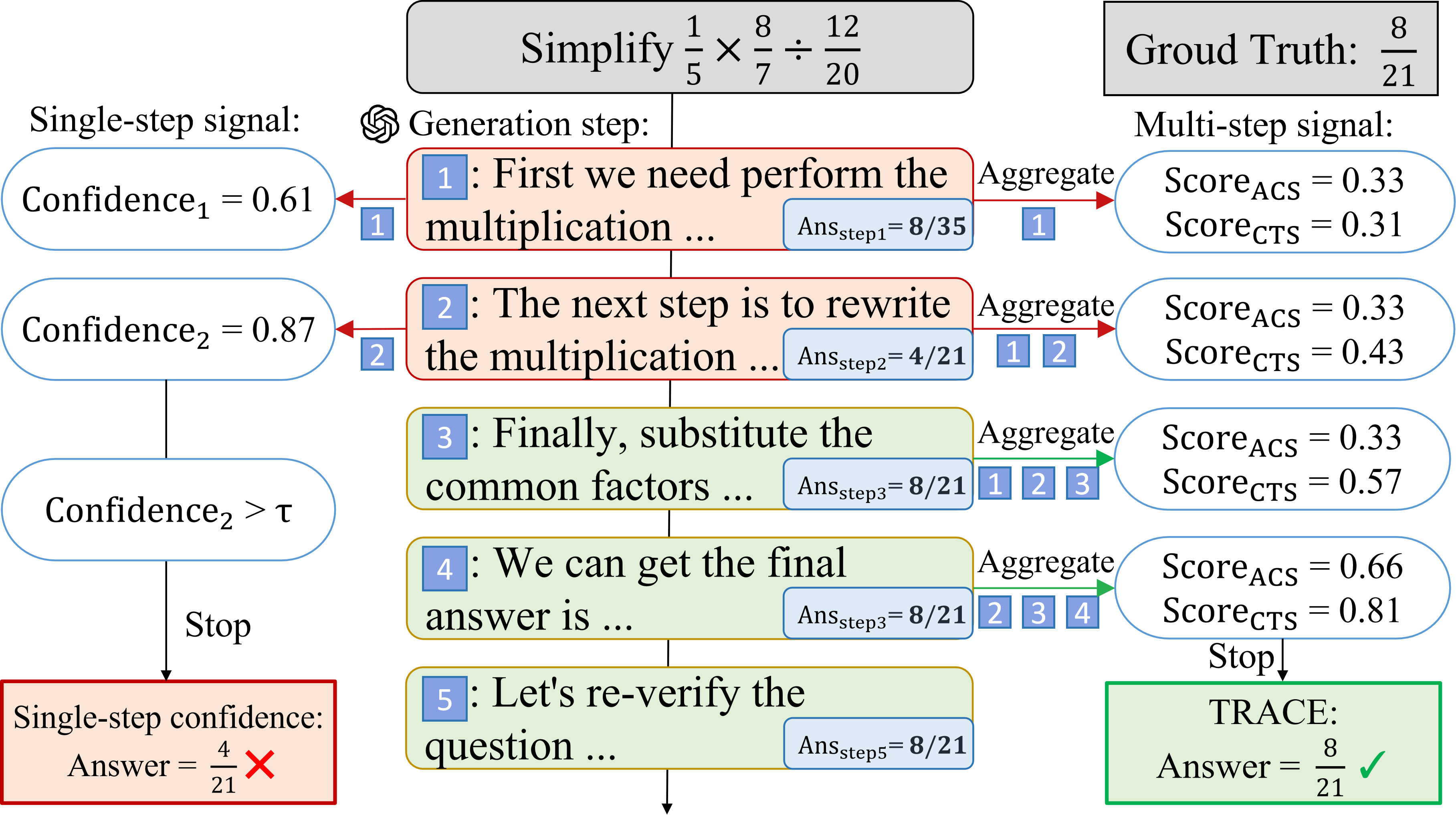
Figure 1: Single-step confidence-based early-exit prematurely stops at a high-confidence but incorrect intermediate prediction, while TRACE avoids false convergence and reaches the correct answer.
To address these intrinsic weaknesses, the "Efficient Test-Time Scaling via Temporal Reasoning Aggregation" (2604.17304) paper proposes TRACE: a training-free, test-time aggregation framework for robust early-exit in multi-step reasoning. TRACE integrates cross-step consistency and confidence trajectory, providing a principled stopping criterion that mitigates both premature and delayed termination.
Methodology: TRACE—Temporal Reasoning Aggregation for Convergent Exit
TRACE departs from instantaneous, single-step signals by aggregating multi-step evidence through a sliding window. At each step t, it considers the k most recent reasoning steps and computes two complementary signals for each candidate answer a:
- Answer Consistency Score (ACS): Quantifies the persistence of a candidate answer across recent steps. Converged reasoning is expected to stabilize, with the correct answer recurring in the majority of recent segments.
- Confidence Trajectory Score (CTS): Captures both the magnitude and the temporal evolution of model confidence in the candidate answer over the context window. Sustained high confidence over several steps signals genuine convergence, whereas abrupt spikes are discounted.
These signals are linearly combined (via a weighted sum, with hyperparameter α) into a unified stability score. Early-exit is triggered when the best candidate answer's combined score exceeds a threshold τ, ensuring that only temporally-persistent and well-supported conclusions are accepted.
This architectural overview is depicted schematically below (Figure 2).
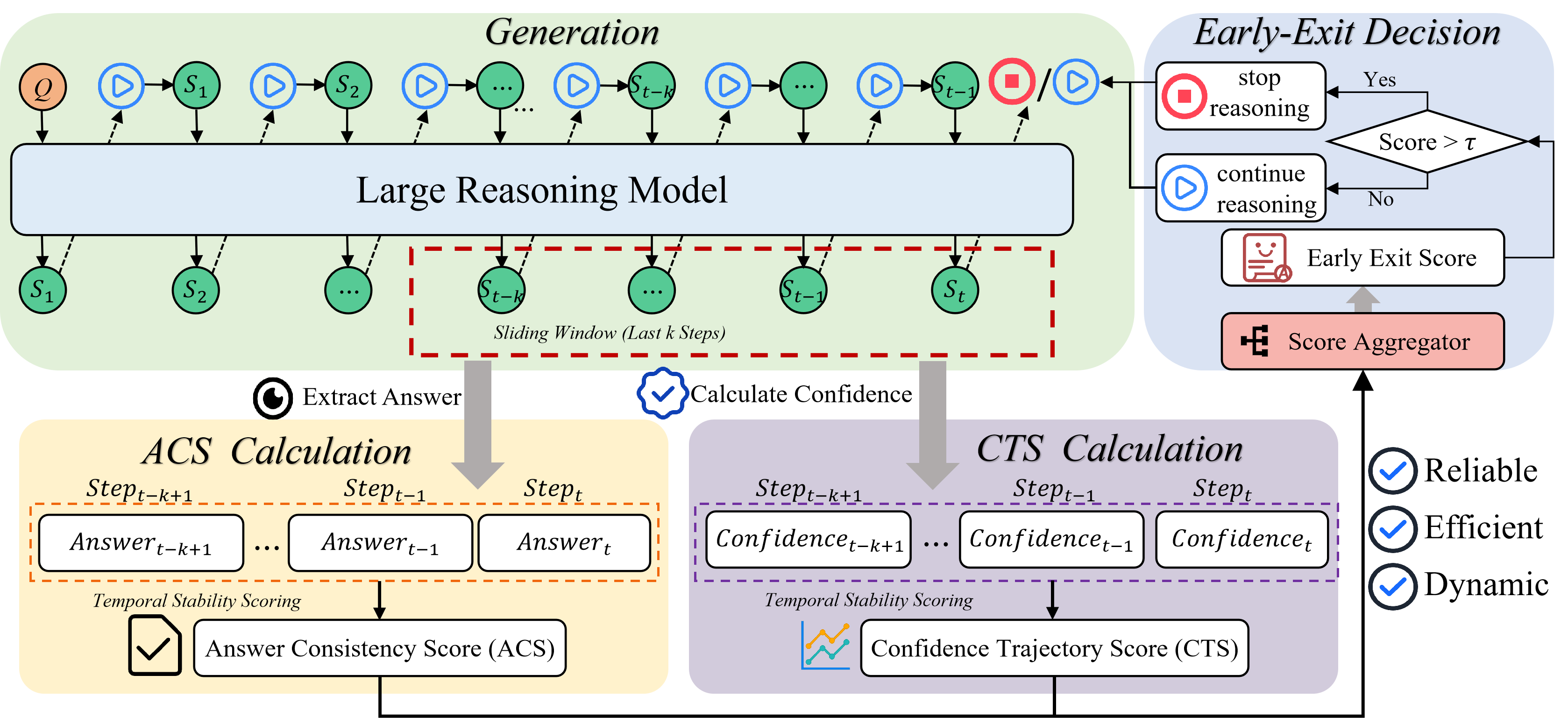
Figure 2: Overview of TRACE. The model generates reasoning steps autoregressively. A sliding window over the most recent k steps aggregates answer consistency and confidence trajectory signals, which are jointly used to determine whether the reasoning process has converged and can be safely terminated.
Evaluation and Empirical Analysis
TRACE is evaluated on a suite of hard mathematical reasoning benchmarks (OlympiadBench, MATH500, AIME24/25, AMC23) and a challenging science QA dataset (GPQA-D). Experiments utilize diverse model architectures, including Qwen3-8B, Qwen3-4B, Gemini2.5-Flash, and DeepSeek-R1-Distilled-Llama-8B.
Key results:
- TRACE achieves average token reductions of 25-30% relative to vanilla full reasoning, with accuracy drops contained within 1–2% across all models and datasets.
- Compared to dynamic early-exit baselines (e.g., DEER, Dynasor, TALE), TRACE systematically achieves superior accuracy–efficiency trade-offs. Aggressive baselines often either excessively curtail traces (causing notable accuracy loss) or fail to gain efficiency over full reasoning.
- On out-of-domain scientific reasoning (GPQA-D), TRACE generalizes robustly, delivering lower token costs and consistently higher accuracy than baselines.
The effectiveness of TRACE versus single-step confidence-based early exit is visualized in the accuracy–token trade-off below (Figure 3).
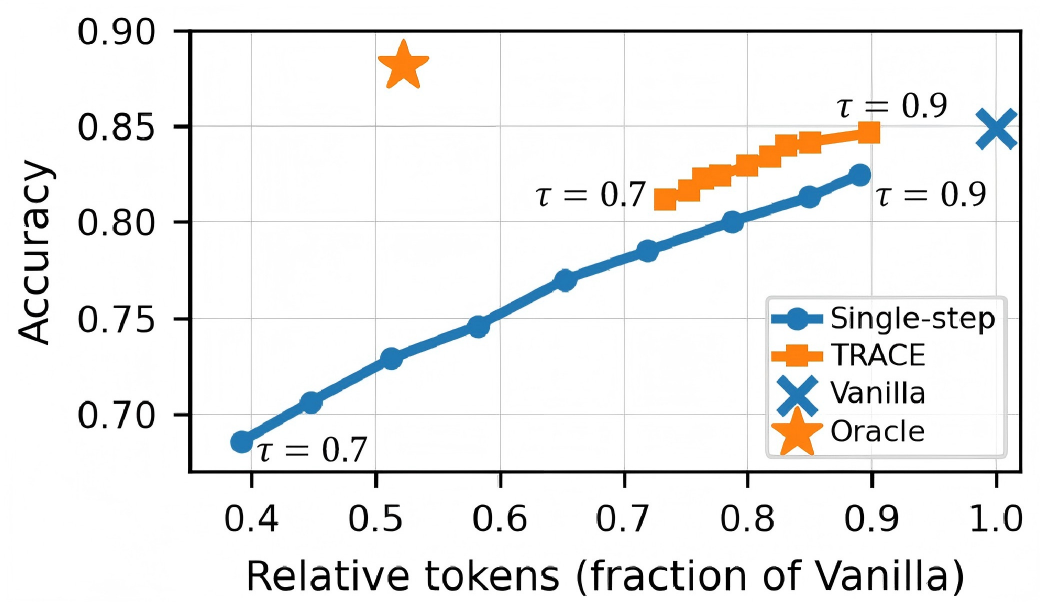
Figure 3: Accuracy–token trade-off under identical early-exit thresholds. Each point on the curves corresponds to a different early exit threshold τ. TRACE achieves improved accuracy at lower token budgets compared to single-step methods.
Ablation studies isolate the contributions of ACS and CTS. TRACE's combined approach consistently yields highest or near-highest accuracy, whereas each single-component variant underperforms on harder tasks, confirming the necessity of aggregating both answer stability and temporal confidence.
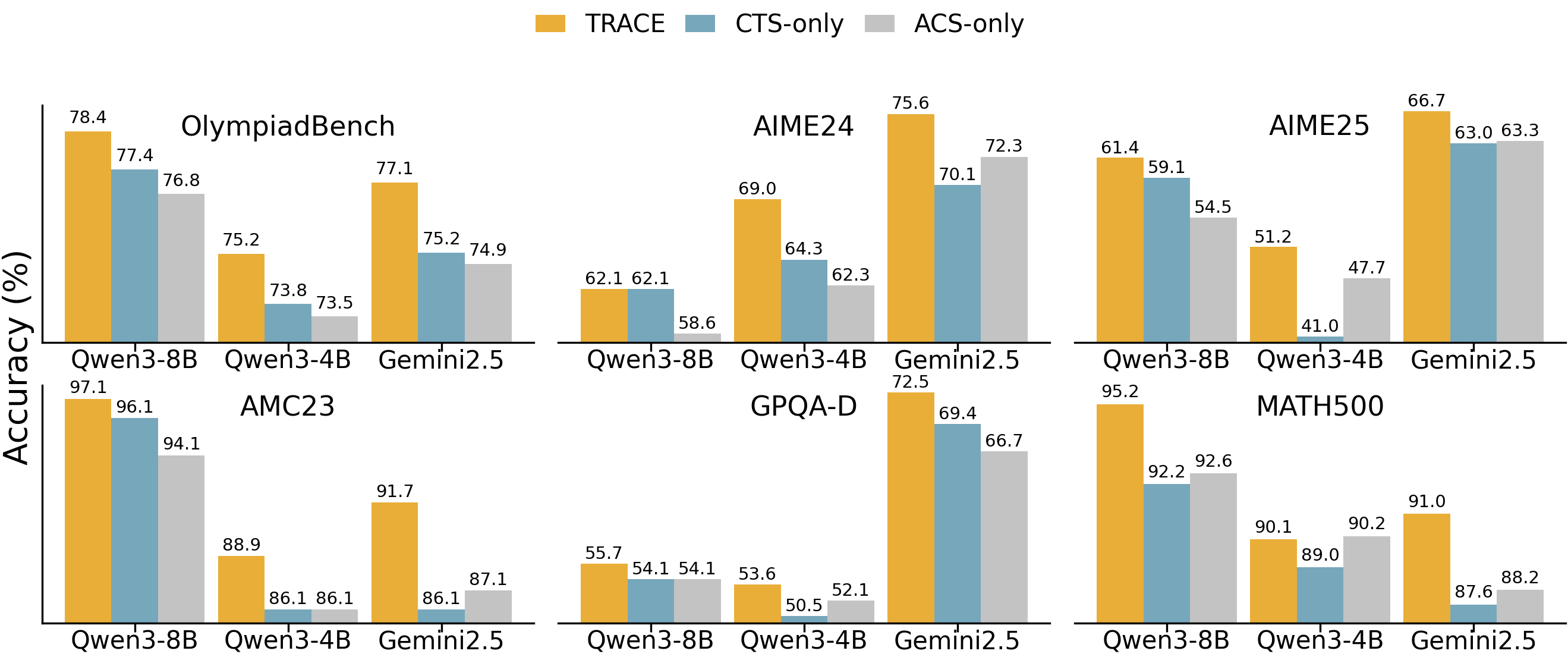
Figure 4: (Left) Ablation results: TRACE (ACS+CTS) vs. single-signal variants. (Right) TRACE stability score distributions demonstrate increased separation between correct and incorrect predictions compared to single-step confidence.
Kernel density estimation of stability scores demonstrates that TRACE produces tight, high-confidence clusters for correct predictions, while incorrect answers tend to have lower, more diffuse scores (Figure 5).
Figure 5: Kernel density estimates of TRACE Stability Score for correct (solid) and incorrect (dashed) predictions across multiple math benchmarks.
Analysis of answer convergence at the early-exit boundary (Figure 6) shows that TRACE typically exits only once the answer sequence has stabilized, whereas single-step methods often terminate while answers still fluctuate, increasing error risk.
Furthermore, cost analysis reveals that TRACE achieves greater inference savings on longer, high-compute examples, confirming practical utility.
Theoretical and Practical Implications
TRACE offers a training-free, model-agnostic enhancement to existing test-time scaling protocols. Theoretically, it operationalizes reasoning convergence as a temporal property, leveraging cross-step statistical persistence and confidence dynamics—an improvement aligned with observed calibration failures of single-step signals.
Practically, TRACE's design lowers latency and compute cost for deployment in resource-constrained environments (e.g., inference serving, API access), with negligible code overhead. Its lightweight answer-induction incurs minimal (<3%) token cost on top of reasoning, and its reliance on fundamental sequence statistics makes it adaptable across LLM variants and tasks.
Case Study: Mitigating Transient Overconfidence
A detailed case study (Figure 7) demonstrates how TRACE avoids classic overthinking/early-exit pitfalls common in mathematical reasoning. When single-step confidence triggers premature exit on a high-confidence yet incorrect answer, TRACE delays termination until answer and confidence have stabilized, yielding correct results.

Figure 7: Illustration of a case study. TRACE avoids exiting on transient, overconfident but incorrect answers, and instead converges on the true answer after multi-step stabilization.
Robustness and Hyperparameter Sensitivity
TRACE exhibits low sensitivity to window size (k) and stability score threshold (τ). Increasing k yields marginal accuracy improvements; performance remains stable for practical window sizes. Default settings (k0, k1) balance efficiency and reliability across datasets.
Inference cost is consistently reduced without sacrificing accuracy—even on challenging, high-budget reasoning instances.
Limitations and Future Work
TRACE is currently validated on text-only benchmarks and does not incorporate multimodal reasoning traces. Extending the approach to include vision-language or other input modalities, where intermediate uncertainty and representation drift may differ, is a key avenue for future investigation.
Potential directions include adaptation to real-time agentic tasks, integration with proactive error detection protocols, or alignment with reinforcement learning-based test-time reasoning objectives.
Conclusion
The TRACE framework establishes a robust, inference-time aggregation protocol for detecting reasoning convergence in LLMs. By moving beyond single-step confidence and leveraging temporal stability of answers and confidence, TRACE obtains significant reductions in token usage with negligible accuracy loss. Its versatility, model-agnosticism, and strong performance across domains make it a compelling solution for efficient, high-accuracy reasoning at scale.
Reference:
Efficient Test-Time Scaling via Temporal Reasoning Aggregation (2604.17304)

