- The paper presents a training-free DepthVAR framework that dynamically allocates computation per token to exploit depth redundancy, significantly reducing inference cost.
- It employs cyclic percentile rotation and adaptive scheduling, achieving up to 3.1× acceleration on standard VAR architectures while maintaining semantic fidelity and fine details.
- Empirical results demonstrate that layered, token-specific computation outperforms hard token pruning methods by preserving image texture and alignment even at lower computational depths.
DepthVAR: Depth-Adaptive Efficient Visual Autoregressive Modeling
Introduction and Context
Visual autoregressive (VAR) modeling for high-resolution image generation remains computationally expensive due to its uniform treatment of all token positions at each scale, ignoring the fact that a majority of tokens do not require maximal processing depth throughout the Transformer. Existing acceleration techniques, such as frequency-based hard token pruning [guoFastVARLinearVisual2025], dichotomize tokens between being "updated" or "pruned", leading to sub-optimal trade-offs between computational savings and synthesis quality. The paper "Depth Adaptive Efficient Visual Autoregressive Modeling" (2604.17286) introduces DepthVAR, a training-free adaptive inference framework that operates by dynamically varying the computational depth per token, leveraging pervasive layer-wise and positional redundancy present in modern VAR models. This approach achieves significant improvements in speed while preserving image fidelity and alignment, without retraining or altering architectural priors.
Limitations of Prior VAR Acceleration Paradigms
Current paradigms for VAR acceleration (see Figure 1) include hard-pruning of low-frequency tokens and sparse anchor-based selection to prioritize high-frequency content updates. However, the work presents compelling evidence that frequency estimation accuracy has a weak correlation with output quality, and even with an oracle ground-truth mask, hard-pruning induces quality collapse (Figure 2). This exposes a foundational limitation: binary pruning fails to exploit the continuous spectrum of computational redundancy across layers and positions.
Figure 1: Comparison of hard token pruning, sparse token retention, and DepthVAR’s adaptive per-token computation paradigm.
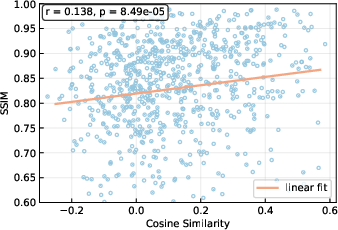

Figure 2: Improved frequency approximation does not yield proportional improvements in image quality, demonstrating the limitation of the pruning heuristic.
Token-wise early-exit and dynamic depth studies reveal that many tokens and layers are redundant for final generation quality—most token representations saturate before the final block, and performance sometimes peaks prior to full-depth computation (Figure 3). Such redundancy patterns diverge from trends observed in encoder-only architectures, further reinforcing the necessity for token- and layer-adaptive inference.
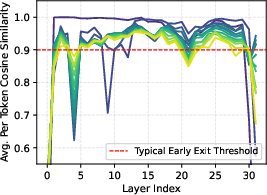
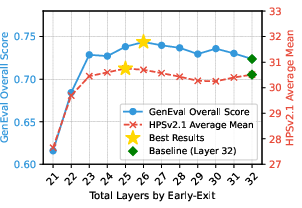
Figure 3: Token-wise layer similarity and early-exit curves indicate position-specific depth redundancy in pretrained VARs.
DepthVAR Framework
DepthVAR introduces an inference-only, training-free dynamic depth allocation mechanism. At each scale i, tokens receive adaptive depth scores, which are deterministically mapped (via bit-reversal) into a per-layer mask ensuring uncorrelated and unbiased utilization of all available Transformer blocks. Instead of discarding tokens or using a binary keep/prune mask, tokens are processed up to a position-specific depth, with inactive regions restored using cached proxies from previous scales, ensuring consistency and minimizing local context disruption (Figure 4).
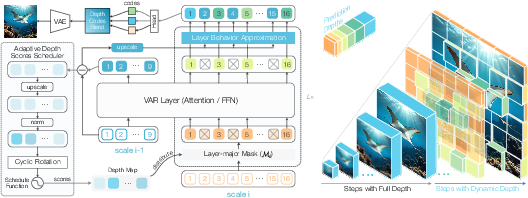
Figure 4: Overview of dynamic depth inference. An adaptive scheduler generates depth scores, which are mapped to a layer-major mask. Dynamic token processing and code blending ensure each position’s contribution is proportional to depth.
A critical technical advance is the use of cyclic percentile rotation during adaptive scheduling (Figure 5), which ensures all spatial positions are periodically updated, avoiding the fixation and starvation observed in static token ranking schemes.
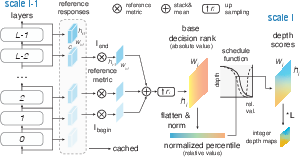
Figure 5: Features from the previous scale are aggregated, normalized, and undergo cyclic rotation before depth score assignment.
Finally, output codes are blended proportional to the assigned depth scores, so deeper tokens (subjected to more computation) dominate feature updates, promoting detail refinement, while shallow tokens serve to control the gradient of change.
Empirical Results
On standard VAR architectures (Infinity-2B and HART-0.7B), DepthVAR achieves 2.3×–3.1× acceleration over default inference with negligible or no loss in GenEval [ghosh2023geneval], HPSv2.1 [wu2023humanhps], and ImageReward [xu2023imagereward] metrics. It consistently outperforms prior hard-pruning/token-merging approaches in both speed and quality, and, owing to its training-free nature, presents a robust baseline for plug-and-play deployment in pretrained VAR systems.
Qualitative Analysis
Qualitative visual comparison with previous SOTA accelerators (Figure 6) makes evident that DepthVAR preserves both semantic alignment and fine texture details, while aggressive token pruning leads to blurring and spatial artifacts.

Figure 6: DepthVAR (right) achieves a 2.3× speedup without sacrificing semantic or fine-grained visual content compared to hard-pruning and merge-based methods.
Methodological Ablations and Analysis
Extensive ablation studies show the superiority of sigmoid-based adaptive scheduling, the necessity of depth-based code blending, and the performance boost achieved via cyclic rotation (Figure 7, Table: Ablation Studies).
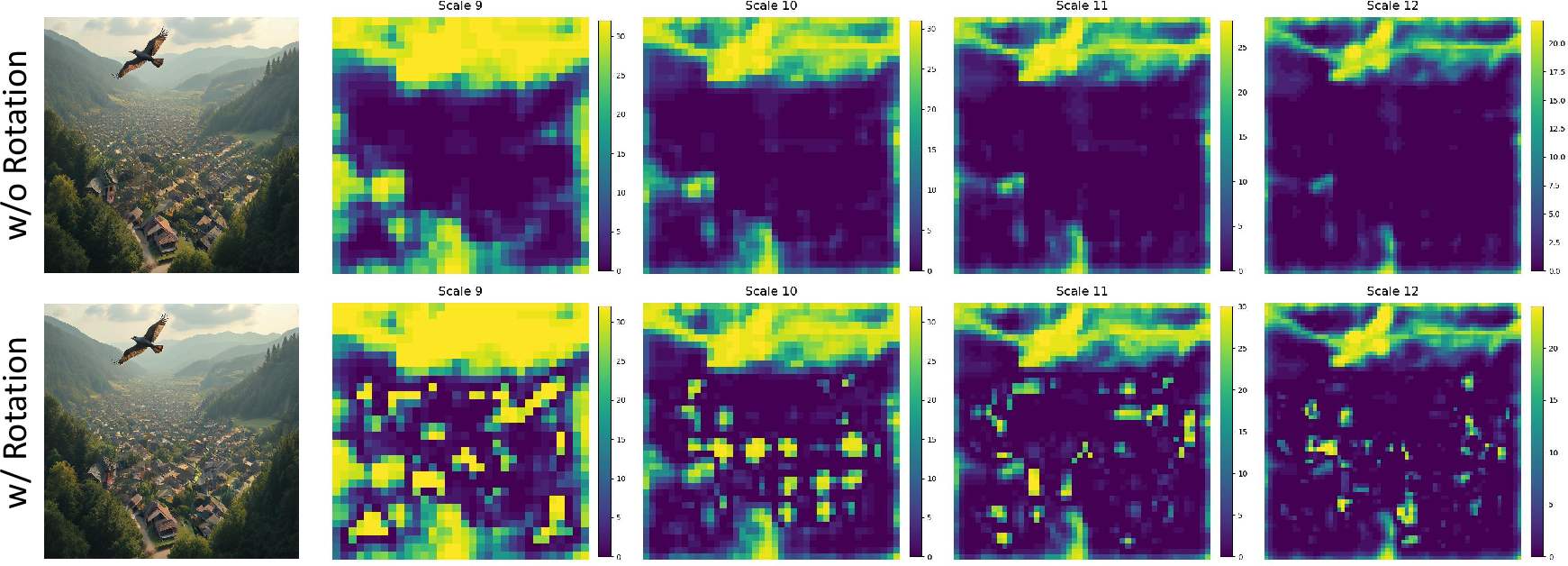
Figure 7: Cyclic percentile rotation assures low-score regions are iteratively updated, as shown in the evolution of depth masks across refinement scales.
The framework exhibits low sensitivity to scheduler function, reference metric, and bit-reversal vs. uniform layer sampling, guaranteeing robustness across architectural variants and compute regimes. Runtime analysis demonstrates that DepthVAR’s overhead is minor compared to the total computation saved (Figure 8), and its GPU memory reduction outpaces leading alternatives.

Figure 8: DepthVAR’s runtime breakdown, highlighting the marginal overhead relative to the efficiency gains in VAR inference.
Theoretical and Practical Implications
For theory, DepthVAR demonstrates that redundant computation in overparameterized generative models can be exploited at inference without retraining, provided architectural priors (e.g., LayerDrop) are present to regularize for depth-agnostic robustness. Practically, this type of fine-grained, layer-major adaptation has immediate impact for deployment of high-res generative systems, especially in resource-constrained or time-critical environments, as well as compositional applications requiring semantic alignment. As shown in broader redundancy studies (Appendix), depth redundancy is universal across VAR variants, ensuring generalization.
Limitations and Future Directions
While DepthVAR can dramatically reduce inference cost, its fixed, preallocated compute regime may inadequately handle universally complex or highly detailed images, where adaptive, per-sample compute routing or even joint early-exit strategies could further improve sample-specific quality/computation trade-offs. Future work includes integrating learned depth policies, sample-adaptive budgets, and cross-modal cues for even finer control.
Conclusion
DepthVAR (2604.17286) establishes a new paradigm for inference-efficient VAR modeling by exploiting per-position, per-layer redundancy, combining technical rigor (bit-reversal, cyclic scheduling, code blending) with strong empirical superiority. The work validates that training-free, dynamic-depth inference delivers a superior, robust, and generalizable trade-off between generation speed and quality, charting a promising research trajectory for scalable generative AI.

