- The paper introduces REZE, an eigenspace-based regularization method that suppresses task-induced biases in domain-adaptive text embeddings.
- It employs a two-stage process with offline eigenspace construction and online regularization to enhance contrastive pre-finetuning without adding inference overhead.
- Empirical evaluations demonstrate that REZE outperforms naive pre-finetuning and post-hoc isotropy methods, especially on heterogeneous benchmarks in finance, code, and chemistry.
Representation Regularization for Domain-Adaptive Text Embedding Pre-finetuning: The REZE Framework
Domain adaptation for text embedding models often involves contrastive pre-finetuning (PFT) on heterogeneous collections of tasks, driven by the scarcity of large, high-quality, in-domain corpora. However, naive PFT imparts significant task-induced biases to the learned representations, distorting the pretrained geometric structure and resulting in negative transfer, particularly when incorporating diverse supervision signals. Past approaches like post-hoc isotropic regularization are typically ineffective in multi-task regimes, especially when training data is limited or highly diversified.
The paper "REZE: Representation Regularization for Domain-adaptive Text Embedding Pre-finetuning" (2604.17257) introduces a novel regularization method—REZE—that explicitly controls the representation shift during embedding pre-finetuning. This is achieved via eigenspace analysis, isolating and adaptively suppressing task-variant (dataset-induced) deviations while maintaining generalizable, task-invariant semantic structure without incurring inference-time overhead.
Algorithmic Framework
REZE proposes an eigenspace-based, relation-level regularization mechanism. Rather than operating directly on individual embeddings, the framework analyzes anchor–positive relation vectors, which better capture pairwise semantic shifts that may be task-specific.
The regularization procedure can be divided into two principal stages:
- Offline Reference Eigenspace Construction:
Anchor–positive pairs from each dataset are concatenated and projected into an eigenspace via covariance estimation and eigenvalue decomposition (EVD). Within this joint space:
- Task-wise means are computed for each eigendimension.
- Task-variant variance is robustly estimated using median-based dispersion metrics across sources (mitigating outlier sensitivity).
- Regularization is only applied to active dimensions explaining the majority of variance (as determined by a cumulative variance ratio, usually 0.99).
- Dimensions showing high inter-source variance are adaptively shrunken toward the global reference using a soft-shrinkage mechanism, parametrized by a robust global threshold and per-source, per-dimension scaling.
- Online Regularization During Pre-finetuning: At each training step, the relation vector from the current model is regularized to match the debiased reference target (calculated via eigenspace transformation and source-specific shrinkage). The final loss is a weighted sum of the standard contrastive InfoNCE loss and the REZE regularization, efficiently integrated into mini-batch training without task or corpus constraints.
The central insight is visualized in the effect of REZE on the representation geometry:
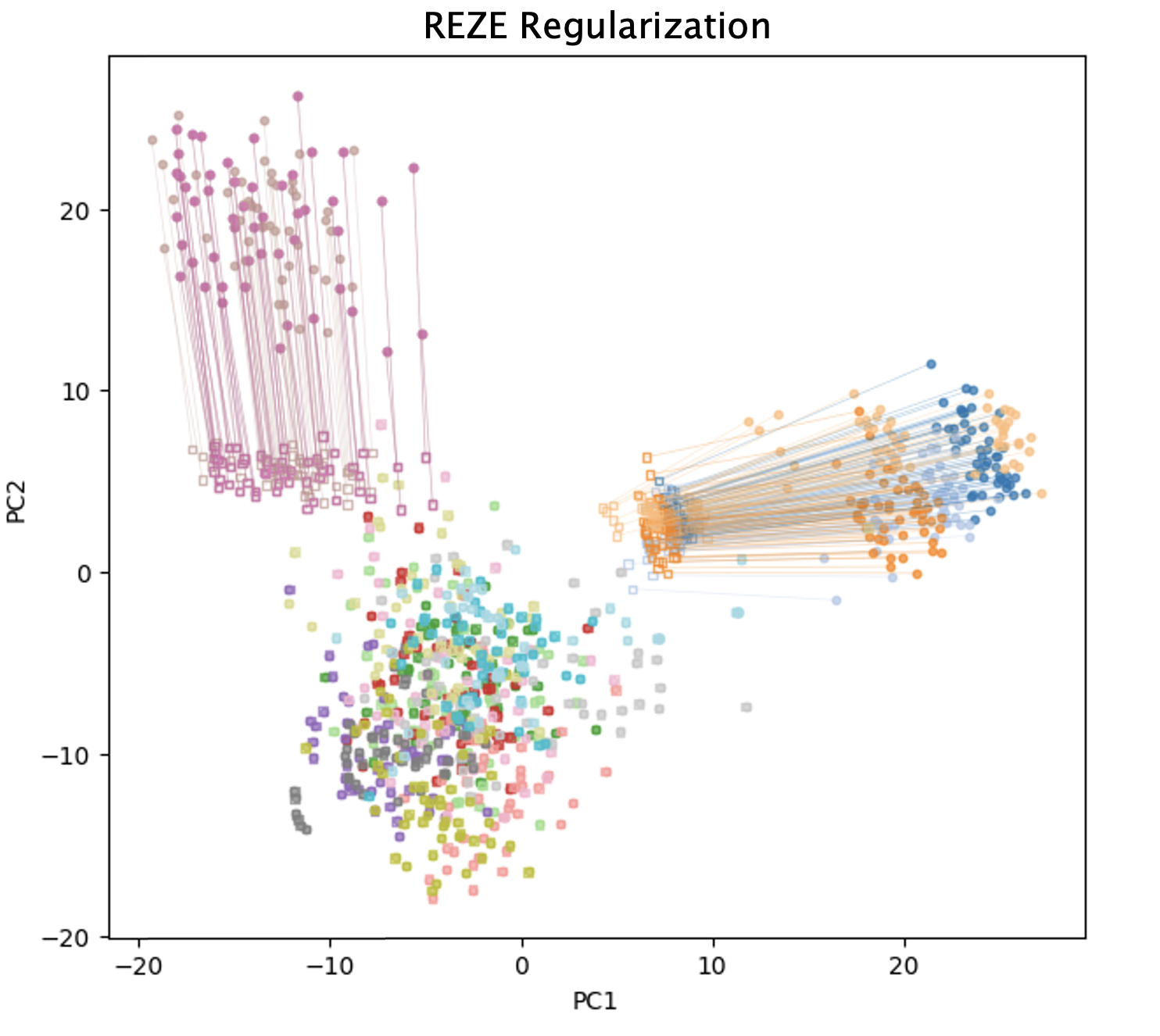
Figure 1: REZE adaptively reduces dataset-specific deviations in the embedding eigenspace by softly aligning components with high inter-source variance, suppressing artifacts that underlie task conflicts.
Empirical Evaluation
Benchmarks and Baselines
REZE is evaluated on three specialized benchmarks—FinMTEB (finance), Code (MTEB, for code-related retrieval), and ChemTEB (chemistry)—to comprehensively assess robustness to heterogeneous task supervision. The experimental protocol involves a two-stage pipeline: pre-finetuning with all in-domain (but non-target) datasets, followed by fine-tuning on limited target supervision. Multiple state-of-the-art embedding models (E5, ModernBERT, GTE, Qwen3-Embedding) are considered to demonstrate generalizability.
Baselines include:
- Direct fine-tuning (FT)
- Standard PFT (no representation control)
- PFT followed by post-hoc Whitening or NormalizingFlow-based isotropy regularization
Main Results
Across all settings (sample sizes 100/500/1000), REZE consistently matches or surpasses both FT and standard PFT. Notably:
- Naive PFT frequently underperforms direct FT, confirming that exposure to divergent in-domain signals can induce detrimental task conflicts.
- Post-hoc isotropy regularization (Whitening, NormalizingFlow) is unstable, often degrading performance due to improper variance normalization and sensitivity to small sample variance estimation.
- REZE demonstrates strong gains, especially where task heterogeneity is highest and where other methods fail (e.g., Code-MTEB with Qwen3 backbone).
The dependence of domain-average performance on the regularization strength α is visualized:
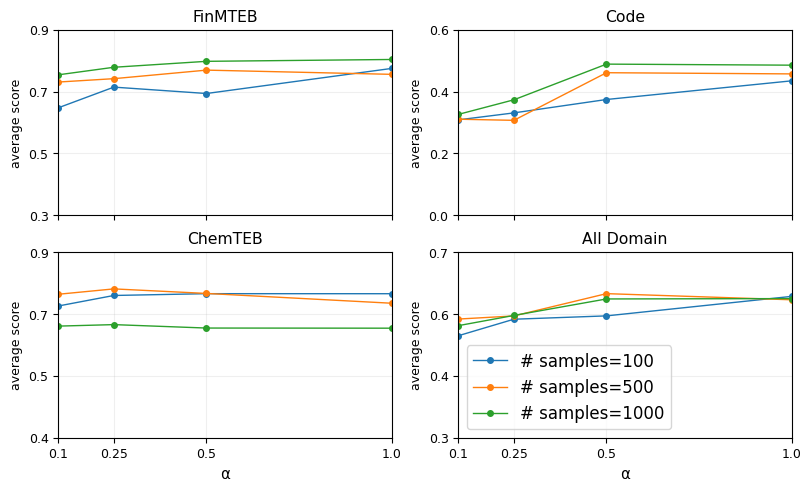
Figure 2: Increasing REZE regularization weight α generally improves performance up to α=1.0, beyond which gains saturate or reverse, confirming that moderate regularization best balances bias suppression and semantic preservation.
Ablation studies further confirm the advantage of robust, median-based statistics for component shrinkage over mean aggregation.
Embedding Space Analysis
Visualization and isotropy analysis substantiate REZE's efficacy in aligning multi-source representation manifolds:
- Embedding Space Visualization:
Examining the projections of anchor–positive concatenations before and after REZE (versus PFT), the method maintains geometric coherence and prevents task-driven drift, as shown in:
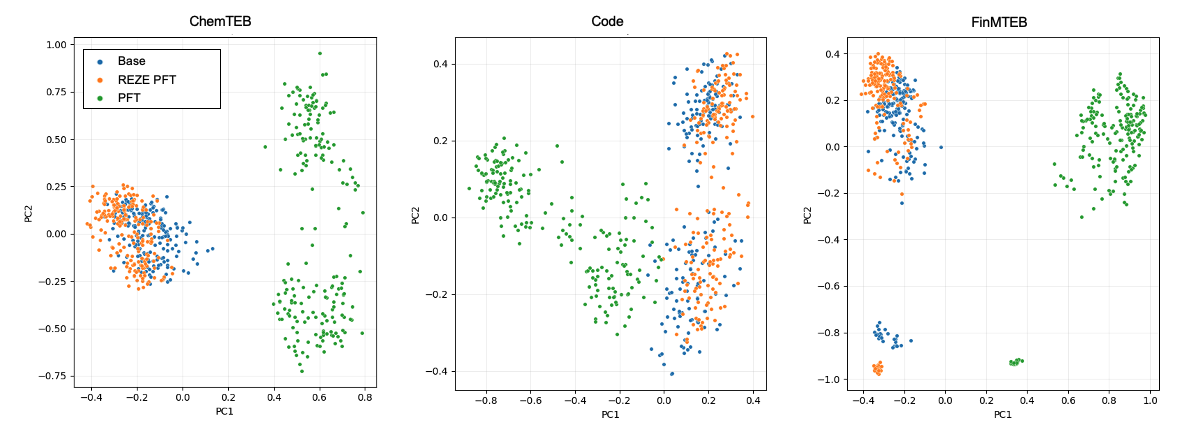
Figure 3: REZE maintains the pretrained manifold's structure across three domain benchmarks, whereas naive PFT induces uncontrolled dispersion and task-induced fragmentation.
IsoScore is consistently increased for REZE-pretrained models over PFT, indicating improved uniformity of embedding space utilization.
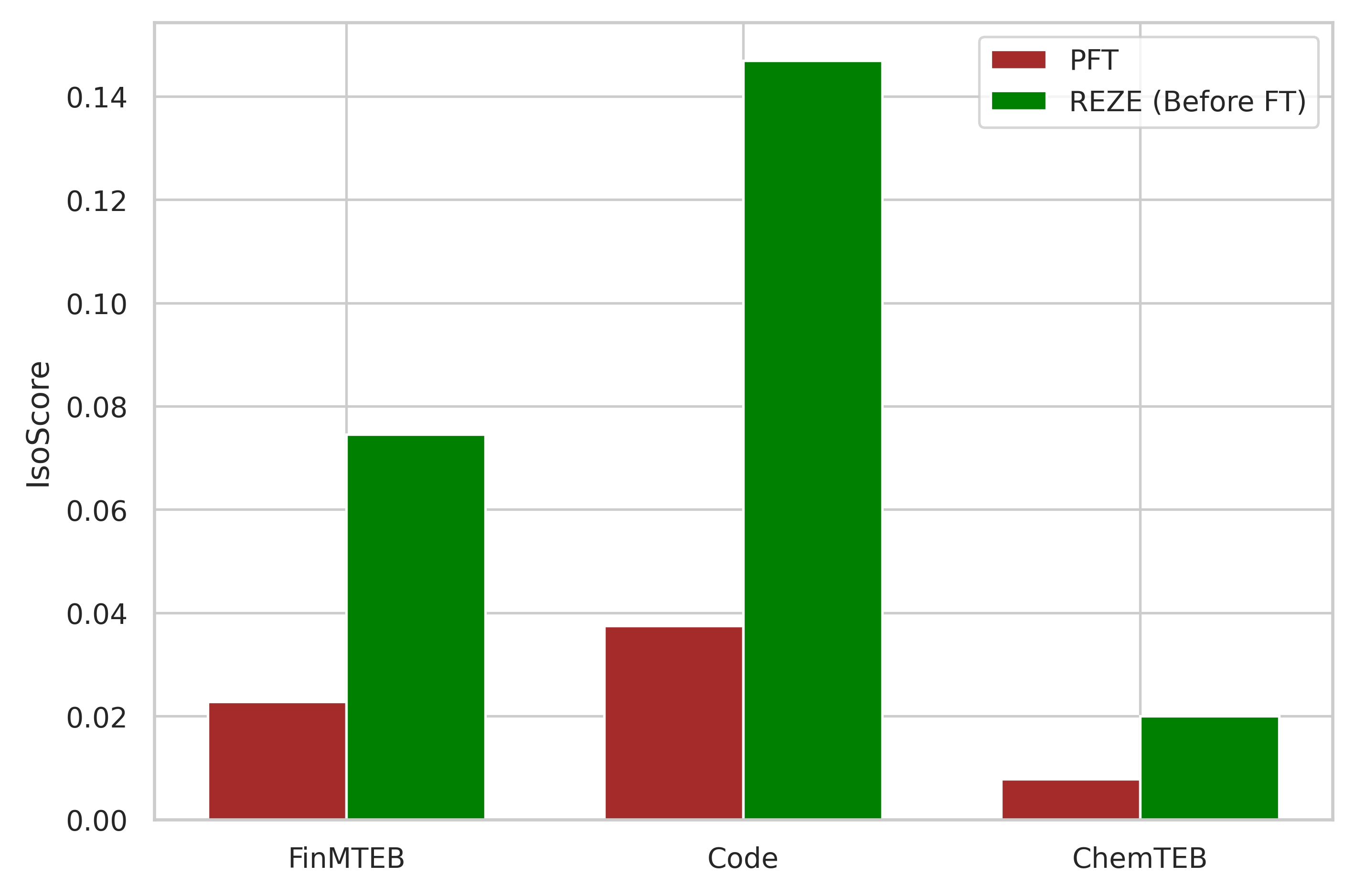
Figure 4: IsoScore comparison highlights REZE's superior control of embedding isotropy relative to standard PFT across all evaluation domains.
Theoretical and Practical Implications
REZE introduces the principle that robust control of representation shift—rather than isotropy alone—is critical for stable domain adaptation under heterogeneous supervision. The eigenspace-based, robust dispersion analysis enables model- and domain-agnostic regularization that avoids both overfitting to dataset idiosyncrasies and underutilization of domain-shared features.
Practically, the method is efficient, requiring only offline matrix computation and no inference-time overhead. It is architecturally agnostic, supporting transformer-based embedding models of varying size and pretraining recipe, and is readily compatible with diverse downstream objectives (classification, retrieval, reranking).
Limitations and Future Directions
Evaluation was limited by the scope of available domain benchmarks (with legal and other high-speciality domains underrepresented) and by moderate model/batch sizes due to computational constraints. Future work should extend REZE to larger models, larger batch settings, and more extreme low-resource or highly specialized environments. Importantly, further integration with modular multi-task and dynamic expert models may yield additional gains in compositional generalization and negative transfer resilience.
Conclusion
REZE is an effective, theoretically principled method for controlling task-induced bias during domain-adaptive text embedding pre-finetuning. Through eigenspace regularization of relation-level representations, it reliably suppresses detrimental representation shifts in the presence of heterogeneous task signals, enabling more robust and sample-efficient downstream adaptation than post-hoc isotropy transformations or naive multi-task PFT. Consequently, REZE offers a practically viable path for constructing domain-specialized embedding models under realistic data and supervision constraints.