- The paper introduces a gradient-based method to filter out high-gradient samples, maintaining the safety basin during fine-tuning.
- Empirical results demonstrate a 3.6× reduction in attack success rate and improved backward transfer with minimal task interference.
- The approach is architecture-agnostic, prevents catastrophic forgetting, and avoids the need for curated safe data.
Continual Safety Alignment via Gradient-Based Sample Selection
The paper addresses a central challenge in the deployment of aligned LLMs: enabling continual adaptation to new tasks while preserving safety alignment, encompassing refusal behaviors, truthfulness, and helpfulness. Empirical evidence has shown that even non-adversarial, benign fine-tuning irreversibly degrades alignment properties established in supervised or RLHF-based stages, with existing approaches either requiring curated safe data or architectural constraints that are impractical for routine deployment.
The key insight developed is a data-centric interpretation: alignment drift is not uniformly caused by all samples. Instead, samples with high per-example gradient norm during fine-tuning are "alignment tension points"—these activate the reversion of models toward their original, less aligned pretrained distribution due to model elasticity. Moderate-gradient samples enable task transfer while mitigating safety collapse.
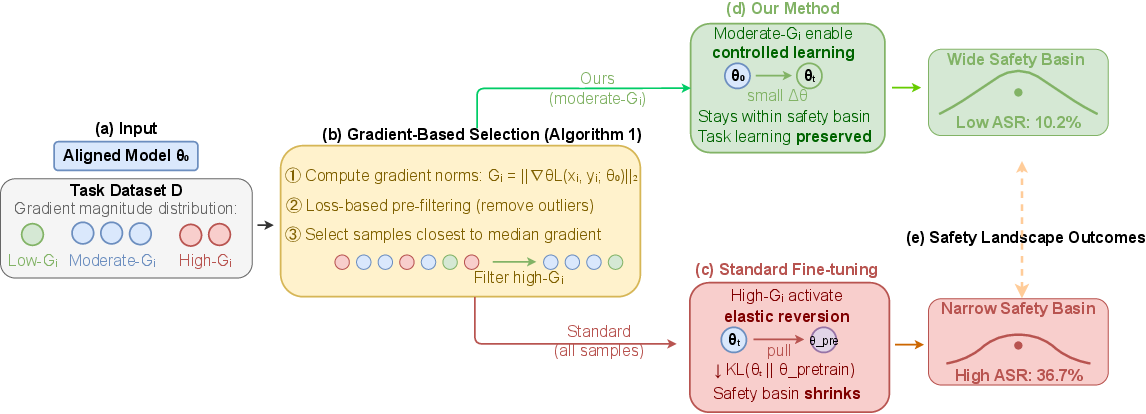
Figure 1: Schematic of gradient-based filtering’s role in maintaining position within the safety basin during continual domain adaptation.
Theoretical Foundations
The analysis leverages two key frameworks:
- Elasticity Theory: Aligned model weights are held in place by a weak alignment dataset, but the immense pretrained corpus exerts a strong parametric "elastic" pull. Fine-tuning on misaligned gradients provides a rapid pathway for the model to revert toward its pre-alignment policy distribution, rapidly increasing attack success rates.
- Safety Basin Geometry: The parameter space surrounding an aligned checkpoint forms a safety "basin" with sharp boundaries. Small, cumulative parameter deviations incurred through careless fine-tuning can push the model out of this basin, after which the attack success rate (ASR) grows abruptly instead of gradually.
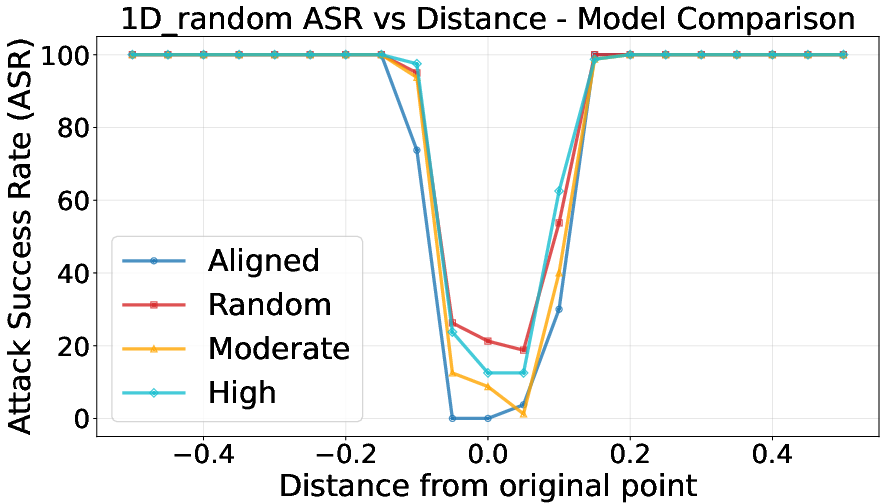
Figure 2: Visualization of safety basins after fine-tuning; moderate-gradient selection leads to robust basins, high-gradient selection shrinks them and causes failure under parameter perturbations.
Sample-Level Mechanistic Analysis
Three major observations underpin the mechanism:
- High-gradient samples correspond to severe output format or label mismatches (e.g., aligned model's verbose QA contrasting with terse classification targets), not to adversarial content.
- Gradient direction analysis shows high-gradient samples induce updates aligned with the pretraining-to-alignment direction in final-layer parameters (especially V/O projections in Qwen2.5 and MLP in LLaMA-3.1), further implicating these samples in elastic reversion.
- Gradient clipping (attenuating update size but not filtering high-gradient content) shows only marginal safety improvement, underscoring the necessity of explicit exclusion of offending samples.
Methodology: Gradient-Based Sample Selection
The proposed method filters training data batches by excluding high-gradient (and, optionally, low-gradient) samples; only samples in a narrow band around the median gradient norm are selected for update. The process involves initial loss-based pre-filtering to eliminate outliers, followed by precise computation and ranking of gradient magnitudes.
The approach is robust to the choice of selection ratio ρ within [0.1,0.4]: lower ratios provide tighter safety at minor performance cost, but moderate settings (ρ=0.2) yield optimal task-safety tradeoffs.
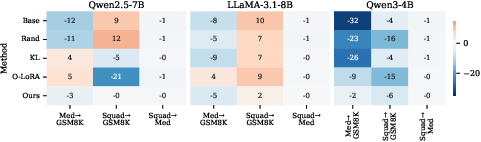
Empirical Findings: Alignment and Continual Learning Metrics
Extensive experiments were conducted on Qwen2.5-7B-Instruct, LLaMA-3.1-8B-Instruct, and Qwen3-4B-Instruct, tested on continual task sequences including Dolly, GSM8K, MedMCQA, and SQuAD v2.
Safety Retention and Task Transfer
Catastrophic Forgetting Prevention
- Backward Transfer & Forgetting Measure: On Qwen3-4B, the method produces a 14.2 percentage point improvement in backward transfer and a 4.3× reduction in forgetting relative to baseline approaches, which is especially significant given the increased vulnerability of recent model families to catastrophic forgetting.
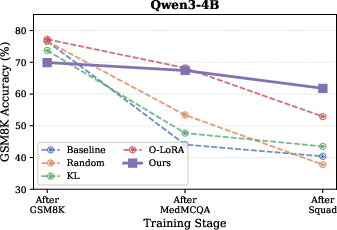
Figure 4: GSM8K performance trajectory illustrates the milder degradation of the proposed approach versus the catastrophic drops suffered by naive fine-tuning baselines.
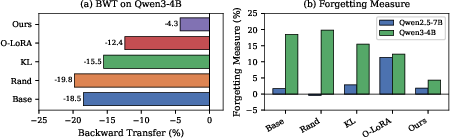
Figure 5: Continual learning metrics highlight superior BWT and FM on Qwen3 using moderate-gradient selection.
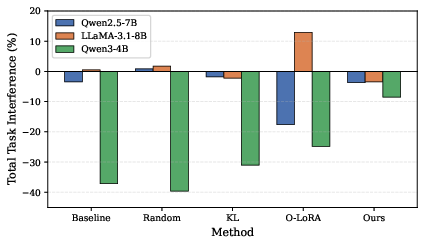
Figure 6: Accumulated interference is vastly lower using the proposed selection method, corresponding to higher retention and safety.
Safety Basin Robustness
Quantitative assessment using VISAGE demonstrates that moderate-gradient filtering preserves 83–88% of the original safety basin, compared to 62–72% for high-gradient selection and 72–78% for random. Safety generalization is validated on HarmBench and under multiple task orderings.
Efficiency and Practicality
While the approach introduces approximately 51% training-time overhead due to per-sample gradient computation, it does not require any curated safe data, is architecture-agnostic, and demands no parameter freezing or intrusive model modifications.
Implications and Future Directions
This work solidifies the link between sample-level gradient magnitude and alignment drift risk, reframing continual safety alignment as a datacentric optimization. The practical significance is substantial: organizations can more reliably adapt LLMs to new tasks without incurring catastrophic alignment failures, and without incurring heavy manual overhead for curation or control.
The theoretical implications are equally noteworthy. By illuminating the functional relationship between fine-tuning data gradients, parameter reversion directions, and the safety geometry of the loss landscape, the work invites further formal analysis and opens the door to future algorithmic refinements, including more efficient gradient approximations, adaptive selection ratios, or hybridization with curvature-aware or representation-based data selection.
Extensions to multimodal and multilingual models, as well as scaling up to foundation-model-sized architectures, remain promising avenues. Particularly, combining gradient-based filtering with other post-fine-tuning alignment restoration or subspace regularization techniques may yield further robustness, as alignment attack scenarios become increasingly diverse and capable.
Conclusion
This paper rigorously establishes that continual safety alignment for LLMs is fundamentally a sample selection problem: catastrophic safety drift and forgetting are strongly predictable and mitigable by excluding high-gradient samples during sequential adaptation. The approach consistently improves both safety and task transfer, outperforming parameter- and architecture-based defenses by a significant margin and providing actionable guidance for the safe, practical, and scalable deployment of continually adapted LLMs (2604.17215).