- The paper presents a hierarchical framework that maps high-level intent to safe trajectories using LLM-based reasoning and SCP.
- It combines behavior abstractions, waypoint generation, and nonconvex trajectory optimization to ensure operational safety and efficiency.
- It demonstrates superior SCP convergence rates and semantic alignment compared to heuristic approaches across 50,000 test scenarios.
Intent-Aligned Autonomous Spacecraft Guidance via Reasoning Models
Introduction and Context
Autonomous spacecraft operations in proximity regimes necessitate robust approaches to mapping high-level intent to safe, dynamically feasible trajectories. Existing optimal control frameworks, specifically Sequential Convex Programming (SCP), offer convergence guarantees and efficiency but remain reliant on expert-coded abstractions that lack semantic interpretability. Moreover, direct mappings from high-level objectives to full-state trajectories circumvent operator oversight and do not seamlessly support intent-conditioned, interpretable planning. Recent advances in foundation models (FMs), notably LLMs, have demonstrated general reasoning and policy generation capabilities, motivating their application as intermediaries for high-level planning in robotics and space systems. This paper introduces a hierarchical framework that leverages FMs for reasoning over behavior abstractions, structured waypoint generation, and nonconvex trajectory optimization, facilitating scalable, safe, and interpretable intent-driven guidance for spacecraft in close-proximity operations (2604.17176).
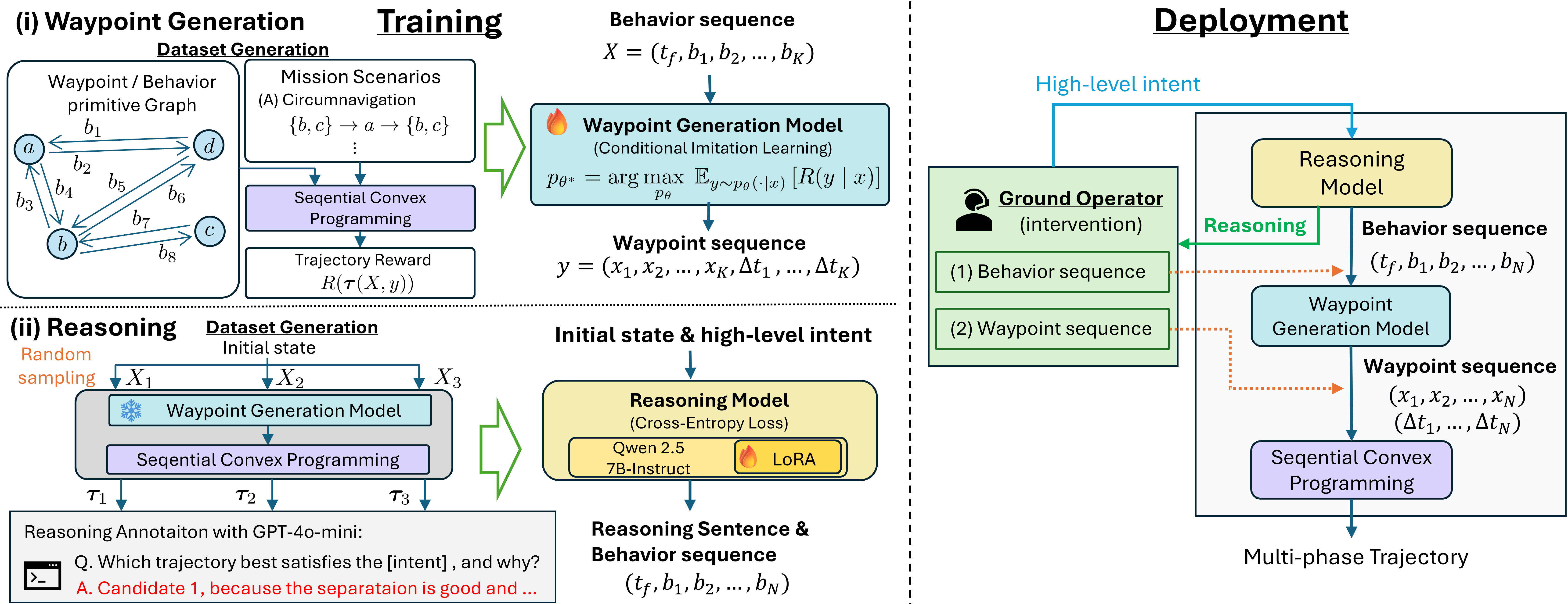
Figure 1: Overview of the training and deployment pipeline, integrating reasoning via FMs, waypoint constraint generation, and SCP-based safe trajectory optimization.
Hierarchical Intent-to-Trajectory Architecture
The framework decomposes the guidance pipeline into three sequential modules:
- High-level Reasoning Model: Maps mission context and prioritized semantic intent to an explicit behavior sequence and transfer time. This is operationalized as tokenized outputs from a pretrained and LoRA-adapted LLM (Qwen2.5-7B-Instruct), trained with optimization-backpropagated supervision to maximize alignment of generated behaviors with intent, leveraging concise reasoning traces.
- Waypoint Generation Model: A conditional Gaussian MLP model, predicting waypoint placement policies from the behavior sequence and scenario context, trained via reward-weighted imitation learning using SCP outcome metrics.
- Trajectory Optimization (SCP): Given generated waypoints, solves a fuel-optimal, chance-constrained, nonconvex trajectory optimization problem, enforcing safety requirements and dynamic feasibility, including robust separation from the keep-out zone (KOZ) under actuation and navigation uncertainties.
This decomposition—explicitly separating behavior, waypoint, and trajectory layers—enables both modular training and operator intervention points, while maintaining end-to-end consistency from human intent to executed trajectories.
Data Generation and Learning Process
The supervised training pipeline iteratively bootstraps the waypoint generator and reasoning model. Large-scale scenario sampling populates a dataset by solving for optimal trajectories under diverse initializations and mission types (circumnavigation, flyby, ducking). Performance rewards are defined as a weighted aggregate of fuel, temporal, observation, and safety metrics, with neural waypoint models trained via reward-weighted log-likelihood maximization.
For the reasoning model, candidate mid-level plans are synthesized, and an LLM automates the annotation of selected plans and rationales by lexicographically following performance priorities. The reasoning model is then fine-tuned to directly infer behavior sequences and concise rationales from context and intent, explicitly ignoring downstream reward or optimization metrics during deployment.
Numerical Results and Analysis
Trajectory Generation and Quality
The approach demonstrates tractable, interpretable inference of multi-phase behavior plans, with downstream pipeline steps reliably translating high-level intent to safe, dynamically feasible RTN-frame trajectories.
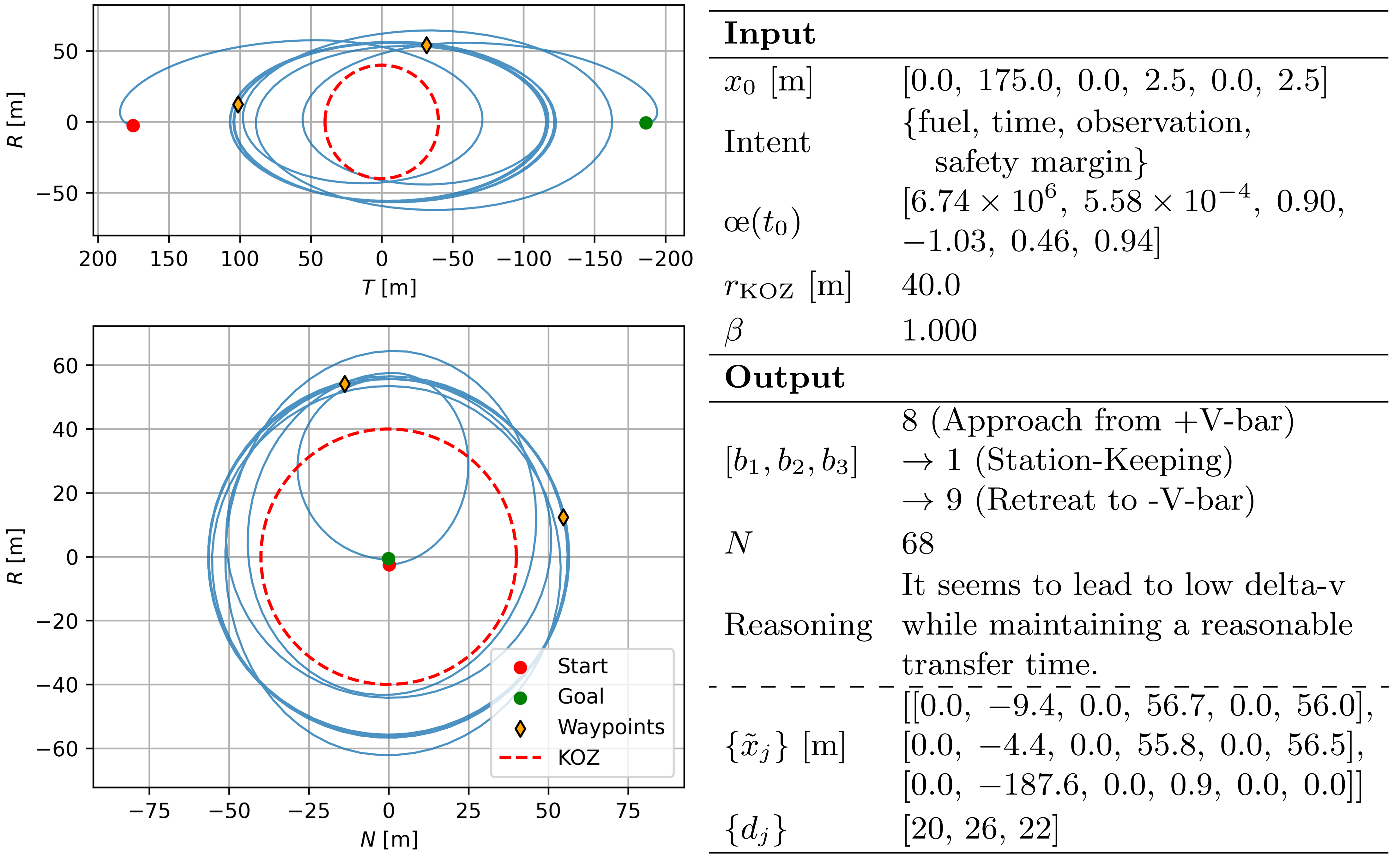
Figure 2: Representative input, intermediate behavior-plan inference, and the resulting optimized trajectory demonstrating intent alignment and robust safety.
Waypoint Generation Effectiveness
On a set of 50,000 scenarios, the neural waypoint generator achieves SCP convergence in 90.6–90.8% of cases, compared to 72.2% for geometric heuristics, with reward-weighted policies yielding higher mean—lower variance—trajectory rewards. Importantly, the majority of waypoint placements (98.8%) fall within a 10 m tolerance of geometrically admissible domains, validating generalization and structural fidelity.
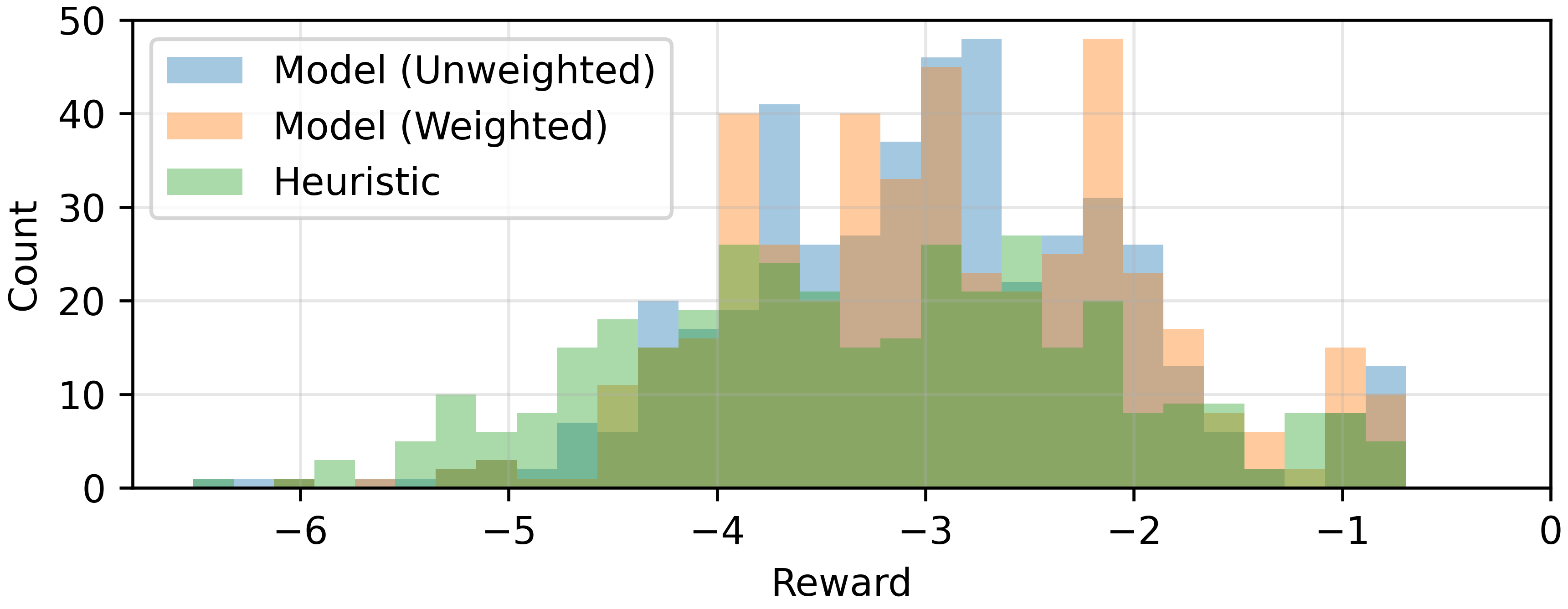
Figure 3: Histogram of reward distribution R(y;X) over test scenarios comparing weighted, unweighted neural, and heuristic waypoint generators.
The full intent-to-trajectory pipeline is validated across four architectural variants (combinations of neural and heuristic modules). The reasoning LLM is feasible in 100% of cases; SCP success is mostly modulated by the waypoint generator, again favoring the neural model.
Critically, in configurations with both trained modules, the pipeline exhibits the highest dual-metric intent/trajectory match rates (18.0% for intent-trajectory, 20.4% for reasoning-trajectory), a relative improvement of approximately 1.5× over heuristic reasoning at fixed waypoint generation. Behavior-sequence feasibility and semantic trace alignment are robust: 52.4% of traces match both top-priority intent metrics, 47.6% at least one.
Theoretical and Practical Implications
The results indicate that the explicit use of intermediate behavior and waypoint abstractions allows for scalable supervision, interpretable operator interventions, and effective propagation of high-level intent to safe, performant closed-loop policies. The LLM-based reasoning layer, decoupled from full state/trajectory metrics at inference, demonstrates that it is possible to distill robust planning heuristics from structured, optimization-backed data while preserving semantic flexibility and operator oversight.
Practically, these attributes facilitate progressive autonomy, critical for mission phases requiring human-in-the-loop supervision as well as full spacecraft self-management. The interface design admits future extensions to collaborative and multi-agent guidance scenarios, as well as integration with visual-semantic or goal-oriented natural language operator interfaces. The approach also highlights the benefit of modular system architectures where interpretable checkpoints propagate uncertainty and enable runtime intervention [art_ieeeaero24, jain2026autonomous].
Future Directions
Several directions are opened by this work: integration of uncertainty-aware neural warm-starts or learned SCP initialization [banerjee2025deep, yuan2024filtering], more expressive sequence models for behavior abstraction [celestini2025generalizable], compositional or multimodal trajectory synthesis, and application to general out-of-distribution context or multi-agent space logistics. Generalization of reasoning strategies and their formal verification in new mission domains remain open research areas.
Conclusion
This paper presents a hierarchical, intent-aligned spacecraft autonomy architecture, establishing that explicit decomposition via behavior and waypoint abstractions allows FMs to serve as high-level reasoning layers, harmonizing semantic mission objectives with safety-critical trajectory optimization. The proposed framework achieves superior SCP convergence rates and higher semantic alignment to operator intent than heuristic baselines, validating the approach in large-scale statistical studies. This method points to scalable, interpretable, and safe autonomy for next-generation space logistics and multi-agent orbital operations.