- The paper introduces ScenarioControl, which applies a vision-language conditioning mechanism with cross-global attention to generate structurally valid, vectorized 3D scenarios for autonomous driving simulation.
- It employs a transformer-based autoencoder and innovative cross-attention branches to merge dense image/text cues with latent tokens, ensuring semantic and spatial alignment.
- Empirical results demonstrate significant improvements in control metrics and collision reduction, enabling diverse scenario synthesis and robust simulation for rare or long-tail driving events.
ScenarioControl: Vision-Language Controllable Vectorized Latent Scenario Generation
Introduction and Motivation
ScenarioControl presents a methodologically significant advancement for controllable scene synthesis in the context of autonomous driving simulation. Its core innovation is a vision-language conditioning mechanism for vectorized scene generation: using either natural language prompts or dashcam-style images, the system generates temporally consistent 3D scenario rollouts, comprising road topology, actor placements, traffic infrastructure, pedestrians, and sensor-level observations in a manner directly ingestible by simulation and autonomy stacks.
The modeling paradigm tackles the sparse-to-dense gap: visual and linguistic signals provide high-level, ambiguous, or partial specification, whereas an explicit, vectorized latent space (map, actors, lane geometry) must be synthesized in a way that is structurally valid and causally grounded. Addressing the limitation of previous works—ranging from purely data-driven replay to unconstrained generative models—ScenarioControl demonstrates controllable generation that generalizes beyond previously seen layouts and input modalities, streamlines human-in-the-loop scenario design, and facilitates diverse, rare, or long-tail test case creation.
Architecture and Conditioning Mechanisms
ScenarioControl employs a transformer-based autoencoder to obtain a compact vectorized latent encoding for both road and agent elements in bird's-eye view (BEV), extended to encode elevation and structure, crucial for camera-space projection and sensor simulation.
The central contribution is the cross-global control mechanism, which fuses input from dense (image or text) modalities with sparse discrete tokens. Cross-attention is split into two complementary branches:
- Fine-grained cross-attention directly connects each latent token to the conditioning stream.
- Global-context branch aggregates a summary embedding from the dense control features and reintroduces it to the latent queries, providing an inductive bias for capturing high-level scene intent.
- Count injection (fcount) infers the number of agents and lanes from the conditioning input, supporting direct complexity control and maintaining structural validity.
This mechanism improves induction of long-range dependencies between global semantic instructions and specific spatial/structural content, outperforming alternative attention fusions—e.g., concatenation, full cross-attention, and linear/gated/agent-specific designs—across all controllability and physical consistency metrics.
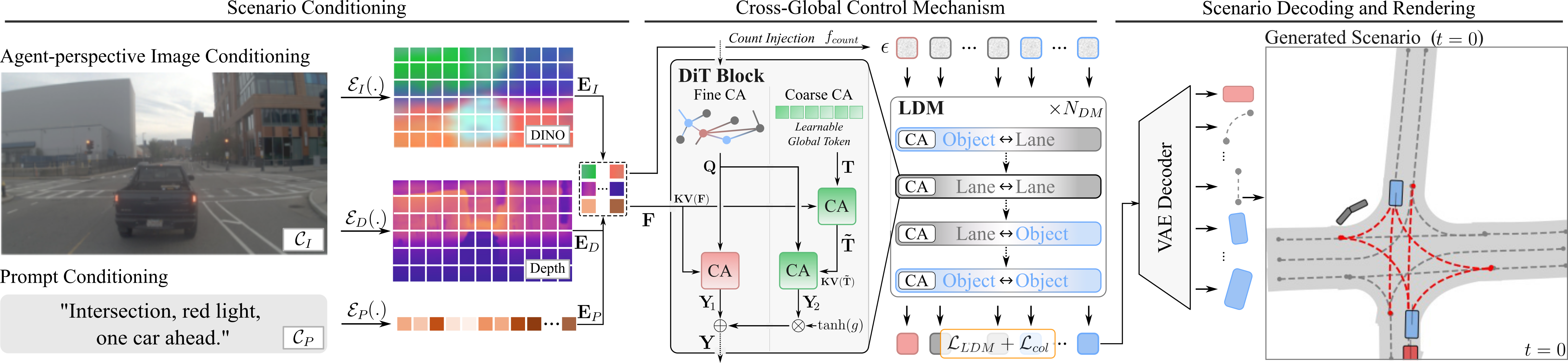
Figure 1: ScenarioControl framework: visual or linguistic conditioning guides vectorized scene generation via cross-global attention, ensuring semantic and structural alignment.
Generative Process and Scenario Synthesis
Given a language prompt (e.g., "Busy intersection with multiple lanes and a crosswalk") or an input image (e.g., dashcam frame), ScenarioControl generates a topologically consistent initial scene. Masks/denoising facilitate outpainting and long-horizon rollouts. The latent diffusion foundation allows iterative, stochastic sampling, producing diverse yet prompt-consistent outputs.
Collision regularization and physically-motivated priors are included in the diffusion loss to ensure realism (i.e., avoid overlapping agents or implausible configurations under ambiguous conditioning).
Figure 3: Diverse image-conditioned initial scene samples, showing deterministic realization of visible structure and sampled plausibility out-of-view.
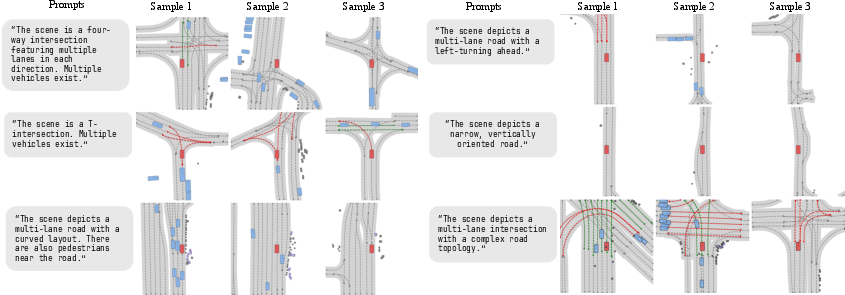
Figure 2: Prompt-conditioned scenario generation, demonstrating high variability and semantic adherence due to unconstrained linguistic input.
Sensor-Level Video Generation and Camera Simulation
Downstream, the vectorized scenario representation enables several forms of sensor simulation:
- Behaviorally consistent rollouts are executed via simulation steps over the vector representation.
- For video generation, the BEV layout is projected into conditional camera-space (using BEV2Cam transformation), providing input to a LoRA-adapted video diffusion backbone (e.g., Wan 2.2) for photorealistic, temporally coherent video synthesis, conditioned on either the first camera frame (frame continuation) or textual scene-level prompts.
Notably, reprojecting allows synthesis from arbitrary camera perspectives and supports actor-centric viewpoint switching, a property unattainable with purely raster-based approaches.

Figure 4: End-to-end video generative pipeline: scenario generation, simulation rollout, BEV-to-camera projection, and photorealistic video synthesis, all controllably grounded in vision or language.

Figure 5: Wireframe overlays demonstrate strict adherence between the generated video and the control signals through time.
Evaluation and Empirical Results
ScenarioControl achieves state-of-the-art controllability across prompt- and image-conditioned settings, as measured by three axes:
- Cosine Control Similarity (CCS): Direct alignment between conditioning signal and generation.
- Shuffled Perturbation Gap (SPG): Robustness to causal perturbations in input.
- Control Sensitivity Correlation (CSC): Output sensitivity to control variation.
These metrics are evaluated at global, lane, and agent levels. ScenarioControl consistently surpasses strong vectorized latent diffusion baselines (Scenario Dreamer) and all ablated attention fusion variants. For example, on NuPlan and Waymo Open Motion:
- Agent control CCS improved from 0.19 (baseline) to 0.30 (text) and 0.38 (image).
- Collision rates dropped by 43% vs. concatenation, with only a marginal reduction in AP.
- In agent placement (Waymo), the method improved AP by nearly 4× over TrafficGen in map-conditioned settings.

Figure 7: Compared to simple concatenation, ScenarioControl maintains control consistency, mitigates hallucination, and minimizes off-FOV violations.
Generalization and Practical Implications
The model is validated on multiple datasets, showing robust cross-dataset transfer (e.g., between NuPlan and Waymo). It supports both the generative synthesis of rare/long-tail events (e.g., simulated incidents, diverse intersections) and scenario editing or in-the-loop test generation for autonomy evaluation.
Its conditioning mechanism affords human-interpretable, modular scenario design, facilitating scalable dataset expansion for safety validation and ML-based planner stress testing. The simultaneous grounding in both structure and appearance paves the way toward unified scenario/video/data generation platforms for closed-loop simulation.
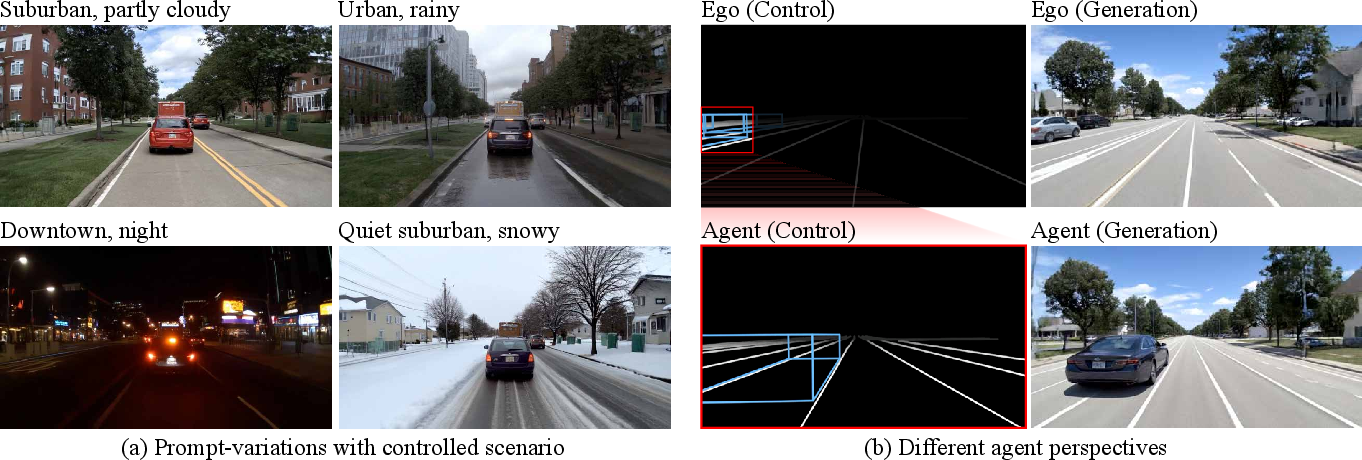
Figure 6: Prompt-conditioned video generation supports both semantic scene variations and arbitrary camera pose transformations, maintaining logical consistency.
Theoretical and Future Directions
ScenarioControl’s explicit, modular fusion of vectorized and dense streams is extensible. Potential future directions include:
- Multi-agent and multi-view extension to encompass more complex, long-horizon, and coordinated interactions.
- Inference of latent scenario parameters (intent, weather, policy) for fine-grained agent behavior customization.
- Integration with end-to-end world modeling for policy learning, closed-loop sensor simulation, or interactive scenario authoring.
- Application to safety validation and generalization stress tests for policy networks in autonomous systems.
Conclusion
ScenarioControl establishes a paradigm for multimodal, interpretable, and structurally grounded scenario and sensor data generation. By bridging vision-language conditioning via cross-global control, it enables high-fidelity, physically consistent, and precisely controllable simulation inputs and outputs. This approach has direct implications for both large-scale evaluation pipelines and research on next-generation data-driven world models for autonomy (2604.17147).