- The paper introduces GRACE, a novel graph-based method that reduces KV cache size by up to 60% with negligible performance drop.
- It combines statistical profiling for outlier protection with a greedy Minimum Incremental Error Selection algorithm to optimize channel pruning.
- Empirical evaluations on LLaMA-3-8B and Mistral-7B show lower attention reconstruction error and improved performance under memory constraints.
Graph-Guided Adaptive Channel Elimination for KV Cache Compression
Introduction and Motivation
Key-Value (KV) cache size remains a severe bottleneck for long-context inference in LLMs, as its memory footprint scales linearly with context length. While token-level and model-level approaches (e.g., token eviction, shared KV heads, quantization) help address this issue, channel-level pruning strategies offer an orthogonal and highly promising avenue for memory-efficient inference. However, existing channel pruning techniques inadequately model the collective effect of pruning decisions: they treat the importance of each channel independently, neglecting the strong inter-channel dependencies observed in real LLMs.
GRACE (Graph-guided Adaptive Channel Elimination) targets this critical limitation by reformulating KV cache pruning as a graph-based optimization. Each channel is explicitly modeled as a node, and channel interactions as weighted edges, enabling a principled selection of pruning candidates that minimizes the degradation of the attention mechanism. A further innovation is the explicit protection of "outlier" channels—key dimensions with disproportionately large activations—against pruning-induced instability.
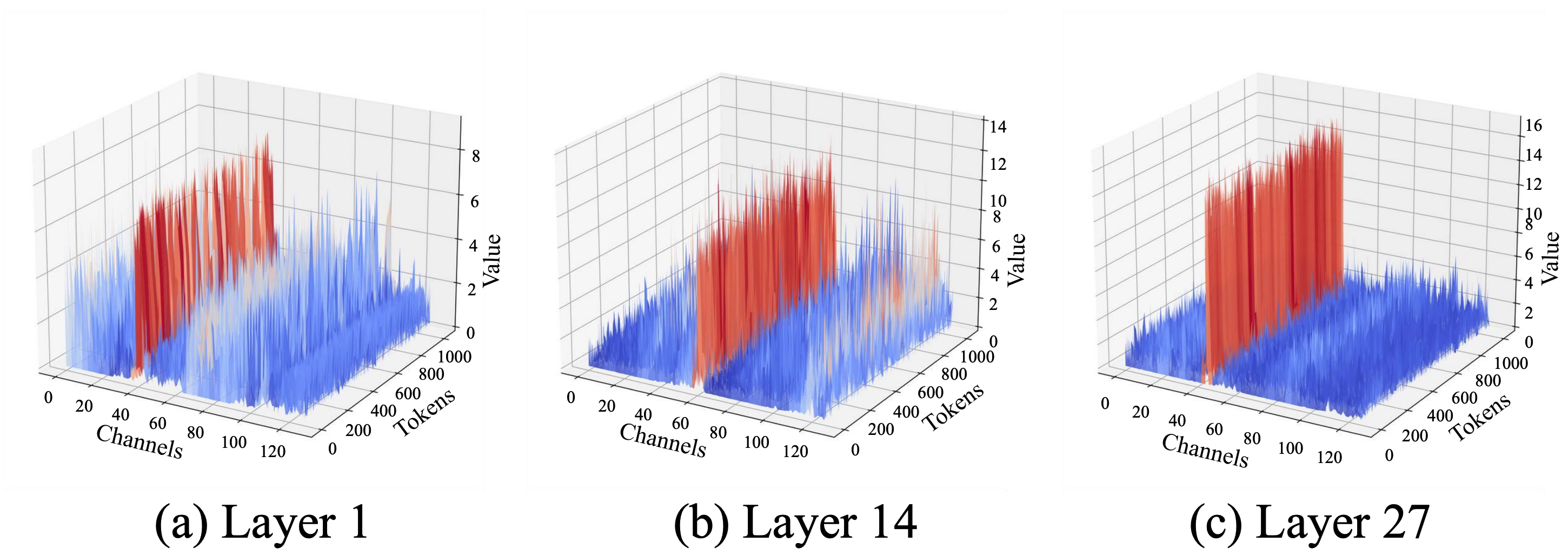
Figure 1: Magnitude visualization of key cache. A small subset of channels concentrates the majority of the energy.
The GRACE Framework
The GRACE framework applies a two-step channel elimination process:
- Salient Channel Protection: Statistical analysis identifies and shields outlier channels, ensuring those with the highest mean and variance (most likely to be critical for model stability) are always retained.
- Graph-Theoretic Pruning: For the remaining candidate channels, a complete weighted graph is constructed, where nodes represent channels and edge weights encode cross-channel interaction strength.
A greedy algorithm—Minimum Incremental Error Selection (MIES)—is then employed. In each iteration, MIES selects the channel whose pruning yields the smallest increase to the cumulative attention reconstruction error (as defined by the Frobenius norm difference between the full and pruned attention matrices). Crucially, the algorithm recomputes channel scores at each step, reflecting the updated state of both self-importance and the cumulative impact of pruned channel interactions.
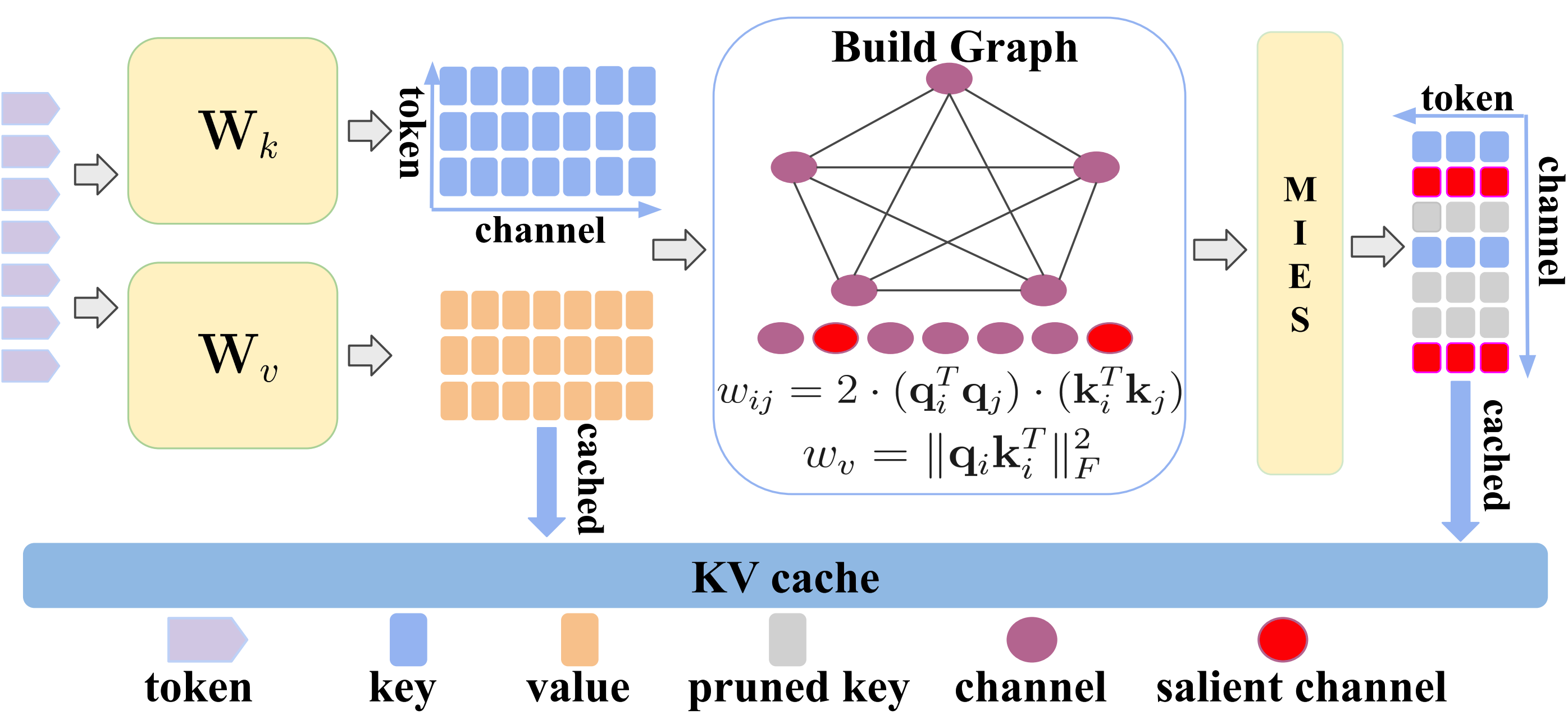
Figure 2: An overview of the proposed GRACE framework.
Formally, the pruning error for a subset S of channels is decomposed as a quadratic set function involving both self and interaction terms:
f(S)=i∈S∑∣∣qiki⊤∣∣F2+i=j∈S∑(qi⊤qj)(ki⊤kj)
This explicit modeling of the off-diagonal interaction terms is empirically validated by the highly non-negligible values observed in the interaction heatmap.
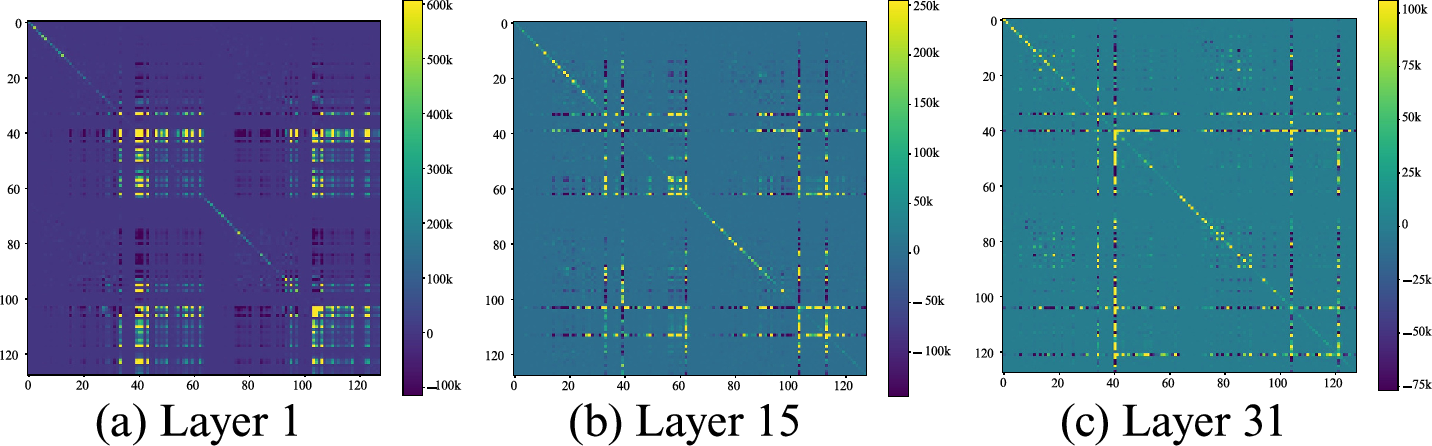
Figure 3: Heatmap of interaction terms between channels, where heatmapi,j=ki⊤kj×qi⊤qj. Off-diagonal terms are non-negligible.
Saliency-Driven Protection: Addressing Query Drift
LLM decoding involves nonstationary query distributions—channels important during cache construction may be essential for future queries. Statistical profiling of query vector activations in GRACE reveals that high-magnitude (outlier) channels also exhibit pronounced volatility. Pruning such channels, even if statistically rare, severely degrades attention fidelity.
To mitigate this, GRACE applies a dynamic, data-driven threshold (mean plus one standard deviation, clamped to a suitable range) to always retain the most volatile and highest-energy dimensions.
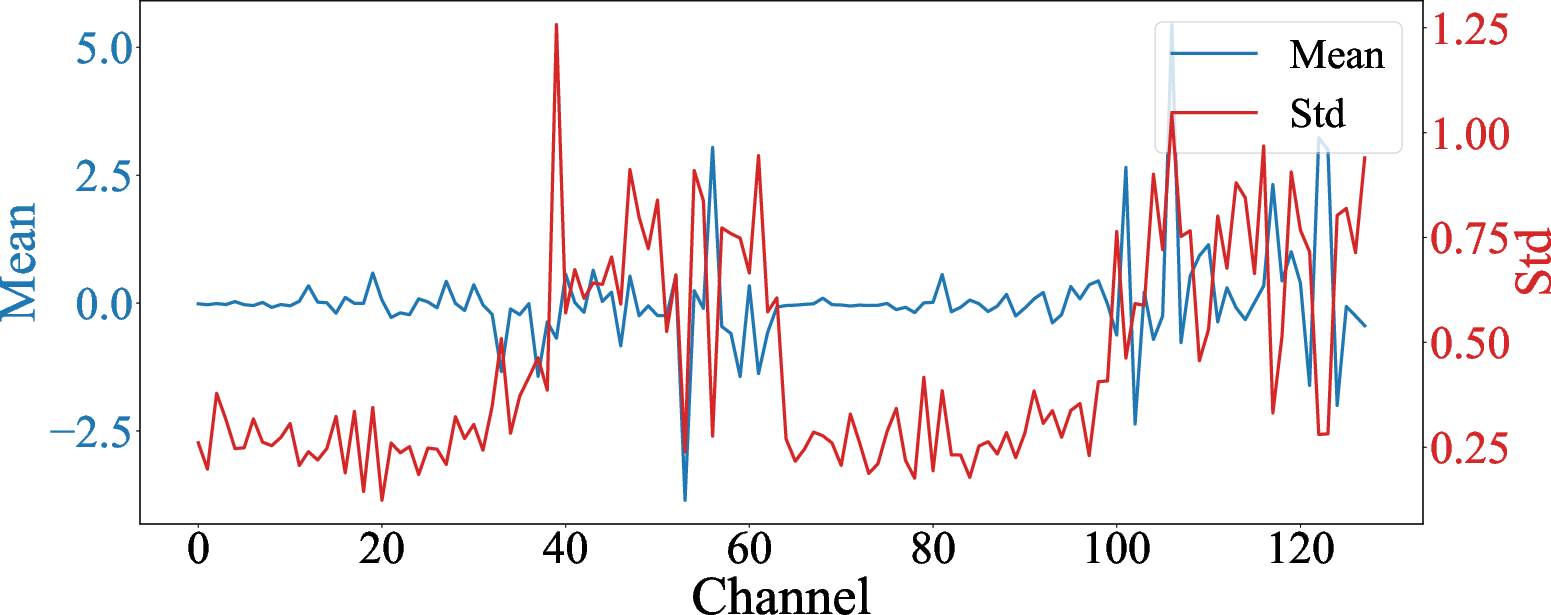
Figure 4: Statistical profiling of query vector channels. Channels with higher mean amplitudes also exhibit higher variance.
This addresses key theoretical weaknesses in prior methods and empirically stabilizes downstream generation, especially under context drift.
Theoretical Analysis
The GRACE optimization objective is a combinatorial quadratic minimization over the subset of candidate channels. GRACE's greedy approximator (MIES) offers the following guarantee: under a restricted eigenvalue condition for the interaction matrix, the selected set achieves a pruning error bounded by the ratio of the maximal to minimal eigenvalues (κ) of the interaction matrix, relative to the (unknown) optimum. Salient channel protection further stabilizes κ, improving the concentration of the bound and ensuring practical near-optimality.
Empirical Evaluation
Extensive evaluation on LLaMA-3-8B-Instruct and Mistral-7B-Instruct LLMs was conducted using LongBench and the Needle In A Haystack benchmark. GRACE consistently outperformed THINK—its main competitor—by achieving lower attention reconstruction error and stronger downstream task performance at equivalent or higher pruning ratios.
GRACE reduced the KV cache size by 60% with negligible performance drop and even surpassed the performance of THINK on 10/16 LongBench subtasks for LLaMA-3-8B at 50% pruning. In Mistral-7B-Instruct, GRACE achieved higher average scores under both 256-token and 512-token KV budgets.
Notably, for the highly compressive Needle In A Haystack setting (96-token KV, 60% pruning), GRACE achieved a retrieval score of 0.828 vs. THINK's 0.804, demonstrating its effectiveness in preserving sparse, critical information under extreme memory constraints.
GRACE further demonstrates robust reduction in attention reconstruction error across decoder layers, especially in the shallowest and deepest layers, where it shows a 30–40% relative reduction compared to THINK.
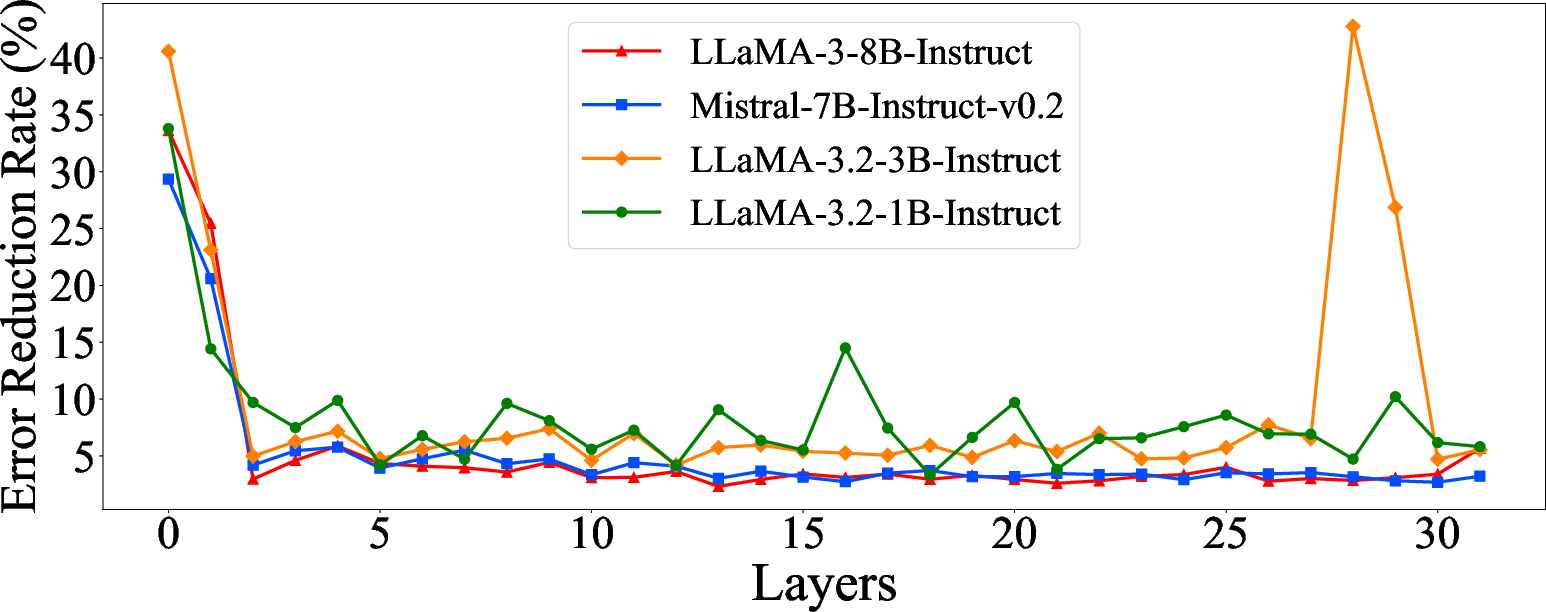
Figure 5: Reduction in reconstruction error for our method versus the THINK across decoder layers.
The computational overhead for GRACE (Time to First Token, Time per Output Token) is negligible, making it practical for real-time or large-batch inference regimes.
Practical and Theoretical Implications
GRACE's graph-theoretic pruning strategy introduces a general, training-free, and plug-and-play framework for channel-level cache compression. It can be straightforwardly combined with model-level cache sharing, quantization, or token-level caches to produce multiplicative gains in inference memory efficiency. The explicit handling of inter-channel correlations provides a template for future cache management algorithms in LLMs and other attention-based architectures.
Theoretically, GRACE's insights link KV cache redundancy to second-order statistics in channel activations, aligning with broader trends in model compression emphasizing the criticality of outlier dimensions. Its greedy solution and protection mechanism suggest avenues for more sophisticated, possibly higher-order or contextual interaction modeling.
Future Directions
Potential extensions include adaptation to other cache compression domains (e.g., value caches, multi-modal attention) and integration with adaptive quantization. Further research into the dynamics of salient channel preservation during instruction-following, multi-turn dialogue, and grounding tasks could inform task-specific cache management strategies. An additional area is making the GRACE framework differentiable and amenable to end-to-end tuning.
Conclusion
GRACE presents a robust solution for KV cache compression in LLMs by explicitly encoding inter-channel dependencies and dynamically protecting salient activations. It offers substantial memory savings with minimal accuracy tradeoff, outperforming established baselines in both typical and memory-constrained settings. Its graph-based methodology and theoretical guarantees mark a significant advance in practical long-context inference for large-scale LLMs (2604.16983).

