- The paper introduces a novel cross-modal knowledge distillation framework that transfers high-order vision-language interactions to lightweight models for referring image segmentation.
- By incorporating channel attention-based relational distillation, the approach improves mIoU by 3–5% on benchmark datasets without increasing model complexity or inference time.
- The work offers an efficient solution for deploying RIS models in resource-constrained settings and paves the way for applying similar techniques to other cross-modal tasks.
Channel Attention-Guided Cross-Modal Knowledge Distillation for Referring Image Segmentation
Introduction
Referring image segmentation (RIS) addresses the challenge of segmenting precise regions within an image as dictated by natural language expressions. RIS integrates cross-modal reasoning, requiring both visual and linguistic context awareness, and has evolved from simplistic feature concatenation methods to approaches harnessing attention mechanisms, cross-modal interactions, and, most recently, large-scale pre-trained vision-LLMs for enhanced performance. However, deployment challenges emerge due to significant computational and memory overheads associated with these large models, making them prohibitive for applications in edge scenarios or on devices with constrained resources.
The paper "Channel Attention-Guided Cross-Modal Knowledge Distillation for Referring Image Segmentation" (2604.16806) proposes a novel knowledge distillation framework that enables lightweight student models to achieve competitive segmentation accuracy without incurring the computational burden characteristic of large-scale models. The approach focuses on the distillation of high-order vision-language correspondences and intra-channel semantic structures from a teacher network to a student network, introducing a channel attention-guided paradigm to cross-modal knowledge transfer.
Methodology
The network architecture is bifurcated into teacher and student branches, sharing an overall design but diverging in encoder backbone scale. The teacher is constructed with deep encoders (ResNet-101 for vision, BERT-12 for language), while the student utilizes lightweight alternatives (e.g., ResNet-18, BERT-4).
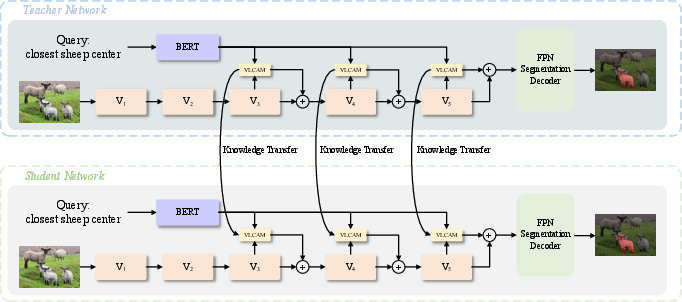
Figure 1: The overall architecture of the proposed model, with explicit teacher-student design and cross-modal distillation.
Cross-Modal Attention Module
Fusion of vision and language features is accomplished through a cross-modal attention module. Visual features (V3 to V5 stages) and tokenized language features are projected and fused via attention, producing a vision-language correlation matrix that encodes the alignment between spatial image regions and linguistic elements. This attention-driven fusion allows for fine-grained cross-modal interaction necessary for RIS.
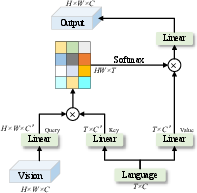
Figure 2: The vision-language cross-modal attention module enabling progressive multimodal feature fusion within the architecture.
Relational Knowledge Distillation
To address the knowledge gap between teacher and student:
- Vision-Language Relational Distillation: The MSE loss aligns student and teacher vision-language correlation matrices, ensuring the student approximates the cross-modal alignment latent in the teacher.
- Channel Attention Relational Distillation: Moving beyond pixel-level mimicry, the framework leverages channel-wise correlation matrices, reflecting the covariance of semantic components within deep feature maps. This constraint promotes transfer of high-level cross-modal reasoning capacity rather than low-level local detail, mitigating excessive over-regularization.
The overall distillation objective is a composite of segmentation loss and two relational distillation terms, weighted by tunable hyperparameters.
Experimental Evaluation
Evaluation on RefCOCO and RefCOCO+ validates the proposed approach. These datasets collectively probe both general (RefCOCO) and appearance-centric (RefCOCO+) language-vision segmentation settings. Mean Intersection over Union (mIoU) is used as the main performance metric.
Notably, without distillation, the student model (ResNet-18 backbone) exhibits substantial degradation relative to the fully self-supervised teacher model (ResNet-101). Incorporating cross-modal and channel attention-based distillation leads to 3–5% improvements in mIoU without increasing parameters or inference time, closing much of the performance gap. The results demonstrate that the framework effectively surmounts the accuracy-resource trade-off inherent in RIS model deployment.
Implications and Future Directions
This work provides two key practical contributions: (1) enabling efficient and deployable RIS models through knowledge distillation that preserves essential semantic alignment, and (2) introducing channel attention-based constraints that transfer mid-level semantic structure instead of merely transferring low-level feature similarity. The approach is extensible to other cross-modal tasks (e.g., visual question answering or cross-modal retrieval) where efficient models are required.
Theoretically, the explicit utilization of channel-wise correlations for relational distillation may influence future studies on structured knowledge transfer and regularization in multimodal settings. Future research directions include extending the method to more diverse modalities, exploring hierarchical or curriculum-based distillation strategies, and further reducing annotation dependence through semi-supervised or self-supervised learning protocols.
Conclusion
The paper presents a channel attention-guided cross-modal knowledge distillation framework for RIS that transfers high-order vision-language correlations and intra-channel relations from large-scale teachers to lightweight students. Through careful design and evaluation, the method substantially reduces model size and computational cost while maintaining competitive accuracy, facilitating deployment on resource-limited platforms. The channel relational distillation strategy advances practical multimodal model compression, enabling more efficient and scalable vision-language applications.