- The paper presents polynomial multiproofs that aggregate multiple sampled evaluations into one proof, reducing communication and storage overhead.
- It leverages a PCS-based multipoint aggregation and deterministic Fiat–Shamir transcripts to secure grouped proofs within micro-domains.
- Experimental results show up to 45% CPU and 42% memory reductions while significantly improving network hit rates and reducing infrastructure needs.
Polynomial Multiproofs for Scalable Data Availability Sampling in Blockchain Light Clients
Motivation and Problem Statement
Blockchain scalability remains constrained by the necessity for full block validation, imposing considerable communication, storage, and computation overhead, particularly for light clients operating in constrained environments. Data Availability Sampling (DAS) offers a probabilistic mechanism by which clients sample and verify subsets of block data. In contemporary deployments, each sampled cell is accompanied by an independent Kate–Zaverucha–Goldberg (KZG) proof, resulting in cumulative bandwidth, storage, and verification inefficiencies. These problems are further exacerbated within peer-to-peer networks using DHTs, due to fragmented retrieval and redundant proof dissemination. The paper introduces polynomial multiproofs (PMP) as a means to aggregate multiple sampled cell evaluations into a single proof, thus amortizing the cryptographic and transport costs.
Multiproof Construction and Grouped Retrieval Model
The proposed system uses a PCS instantiated according to Boneh et al.’s multipoint aggregation protocol, specialized for the DAS context. The aggregation is performed over a shared micro-domain, enabling deterministically grouped proofs to cover contiguous block regions. In this configuration, the prover computes a single aggregated proof for all evaluations within each micro-domain, and the verifier checks an aggregated pairing equation. The aggregation does not compromise DAS’s security model because light clients retain individual reasoning about sampling coordinates, with the grouping influencing only transport and proof amortization.
Canonical grouping metadata is embedded through deterministic Fiat–Shamir transcripts binding each proof to its micro-domain, commitment context, and SRS identifier, preventing proof replay across different groupings. The system partitions row or column domains into disjoint micro-domains, with grouped objects transporting full evaluation vectors together with metadata and aggregated proofs.
Avail Instantiation
The design is realized within Avail, a modular data availability layer. The workflow proceeds as follows:
- Full nodes encode blocks, generate row and column commitments, and compute relevant evaluations and proofs per micro-domain.
- Fat clients fetch, package, and republish grouped authenticated objects (MCell with GCellBlock metadata) into the DHT.
- Light clients perform DAS, mapping each sampled coordinate to its containing micro-domain, fetching grouped objects, and verifying against the aggregated proof.
The improved layout is visually contrasted with the baseline per-cell configuration, illustrating proof amortization via aggregating scalars into multiproof objects.
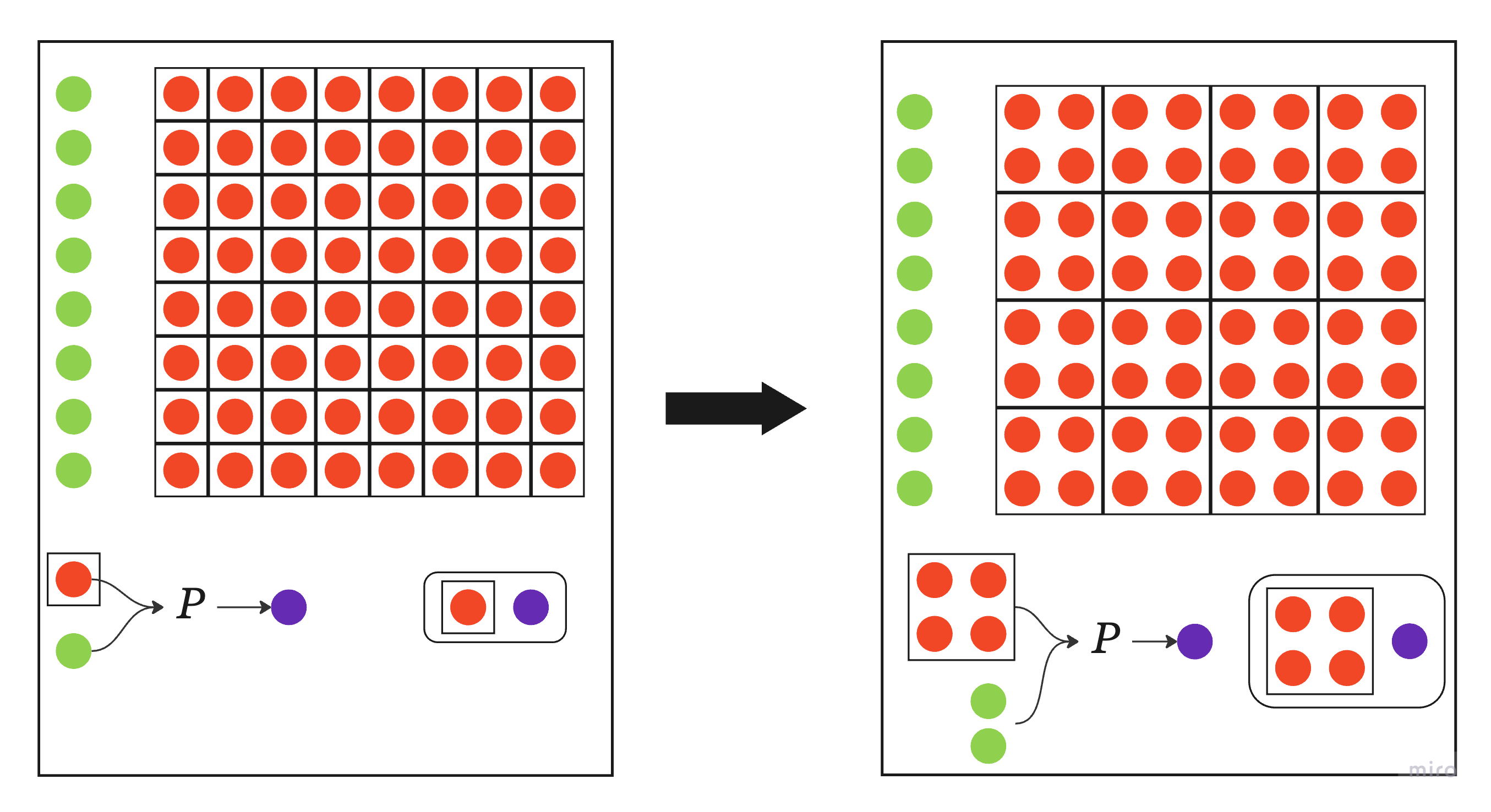
Figure 1: Baseline per-cell retrieval versus multiproof grouping in Avail, showing reduced proof and object count in the multiproof layout.
The approach addresses a critical bottleneck in DHT-based dissemination, wherein multiple sampled coordinates are authenticated with a single proof, drastically reducing object proliferation and proof transmission overhead.
Practical Trade-Offs and Security Considerations
Grouped retrieval preserves DAS acceptance rules, but introduces trade-offs regarding retrieval privacy and correlation of failure events. The grouping factor g must be deterministically chosen to balance proof amortization, locality, and privacy leakage. Conservative soundness accounting recommends that, with perfect correlation within groups, one should sample at least g times as many coordinates to retain security bounds. Larger groups improve locality and efficiency but may reveal sampled neighborhoods to peers.
Experimental Evaluation
The Avail-based implementation is rigorously evaluated across four axes: resource consumption, network behavior, service capacity, and sensitivity. The PMP configuration uses a micro-domain size ∣Tg∣=16, and all tests were performed with fixed seeds and runtime parameters.
Verifier Resource Utilization
PMP substantially reduces CPU and memory overhead relative to the baseline and batched independent verification. At a 1,000-verification batch size, PMP achieves a 45% reduction in normalized CPU usage and a 42% reduction in peak memory consumption.
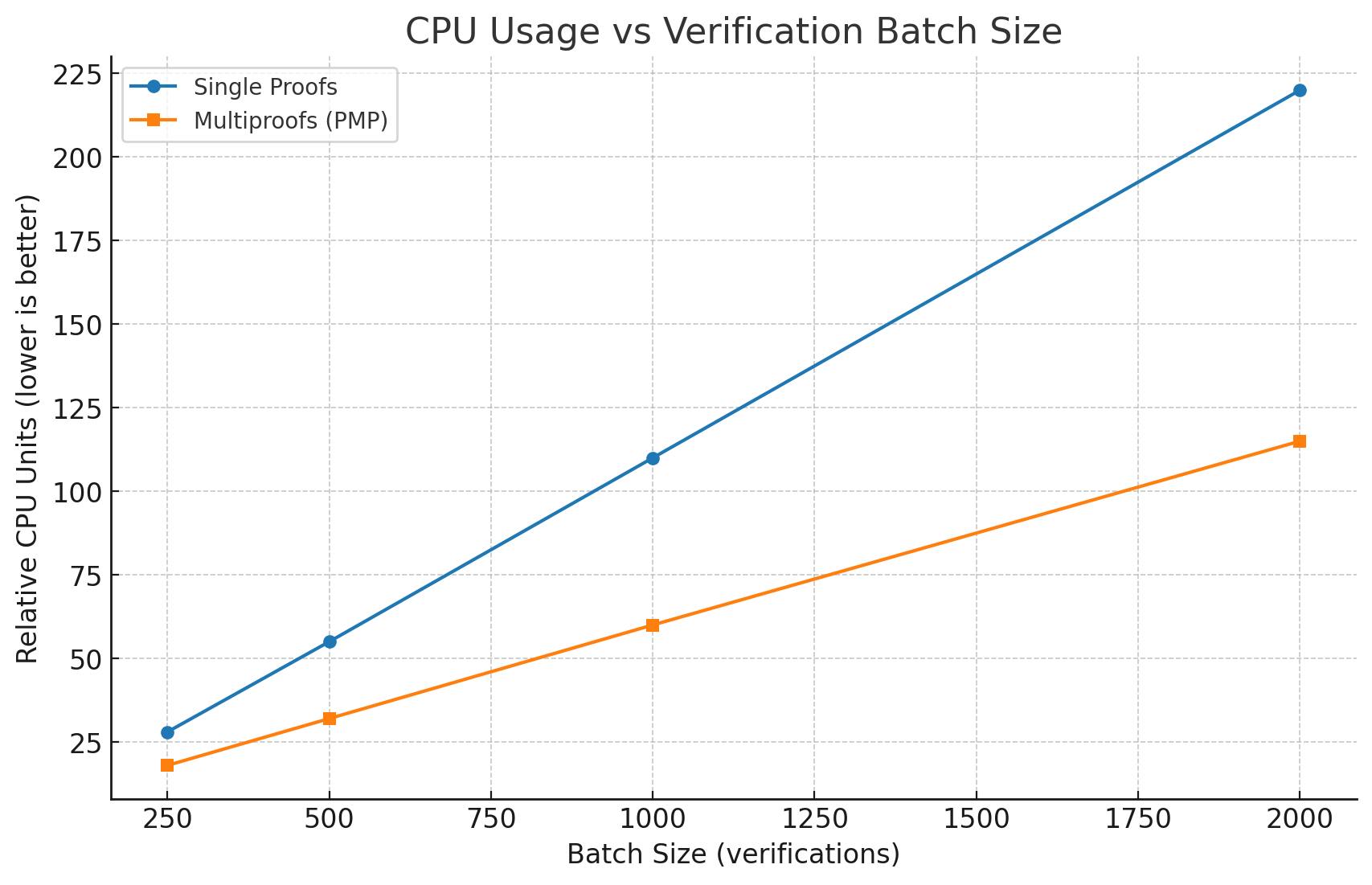
Figure 2: PMP verification requires markedly less CPU per batch compared to baseline and batching alternatives.
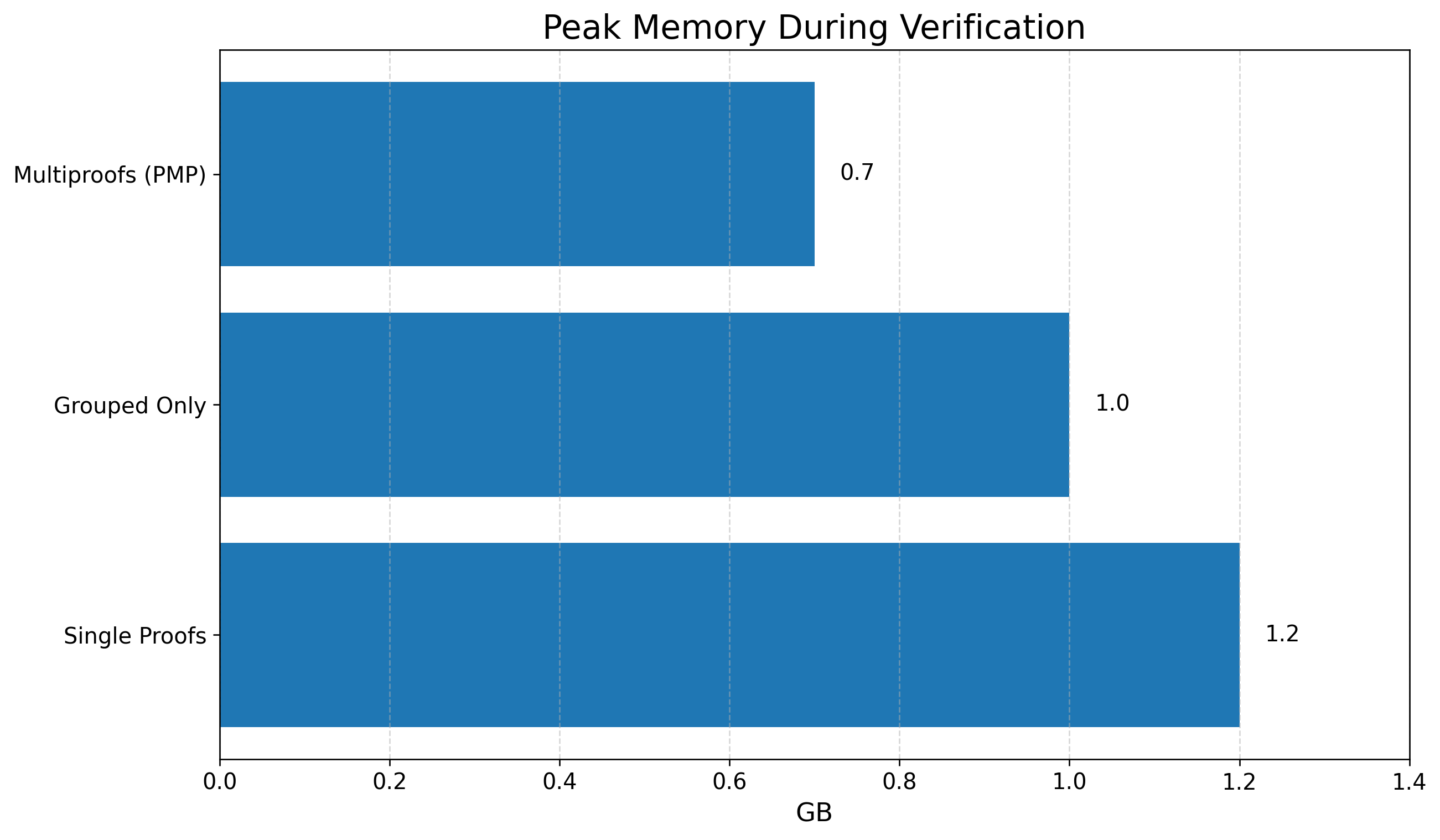
Figure 3: PMP lowers peak memory usage during verification across all tested configurations.
Network-Level Efficiency
PMP improves both DHT hit rates and put rates, particularly for large payloads. Under 1.5–2 MB payloads, hit rates rise from 12% in the vanilla system to 98% with PMP; at 1 KB, hit rates reach 100%. This improvement is not observed with batched verification alone, confirming that network-level gains derive from object grouping and proof aggregation.
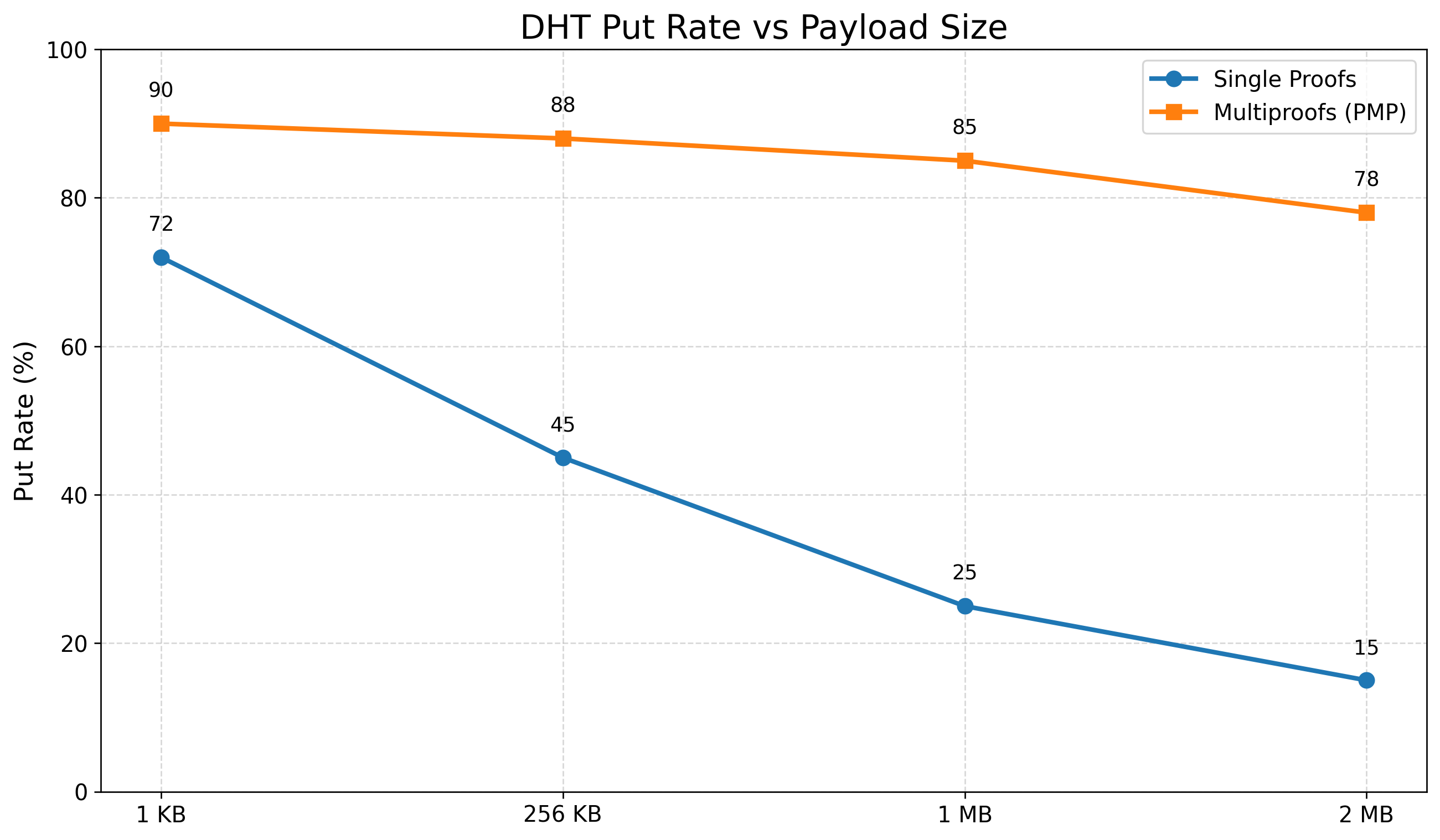
Figure 4: PMP enables higher DHT put rates with increased payload size.
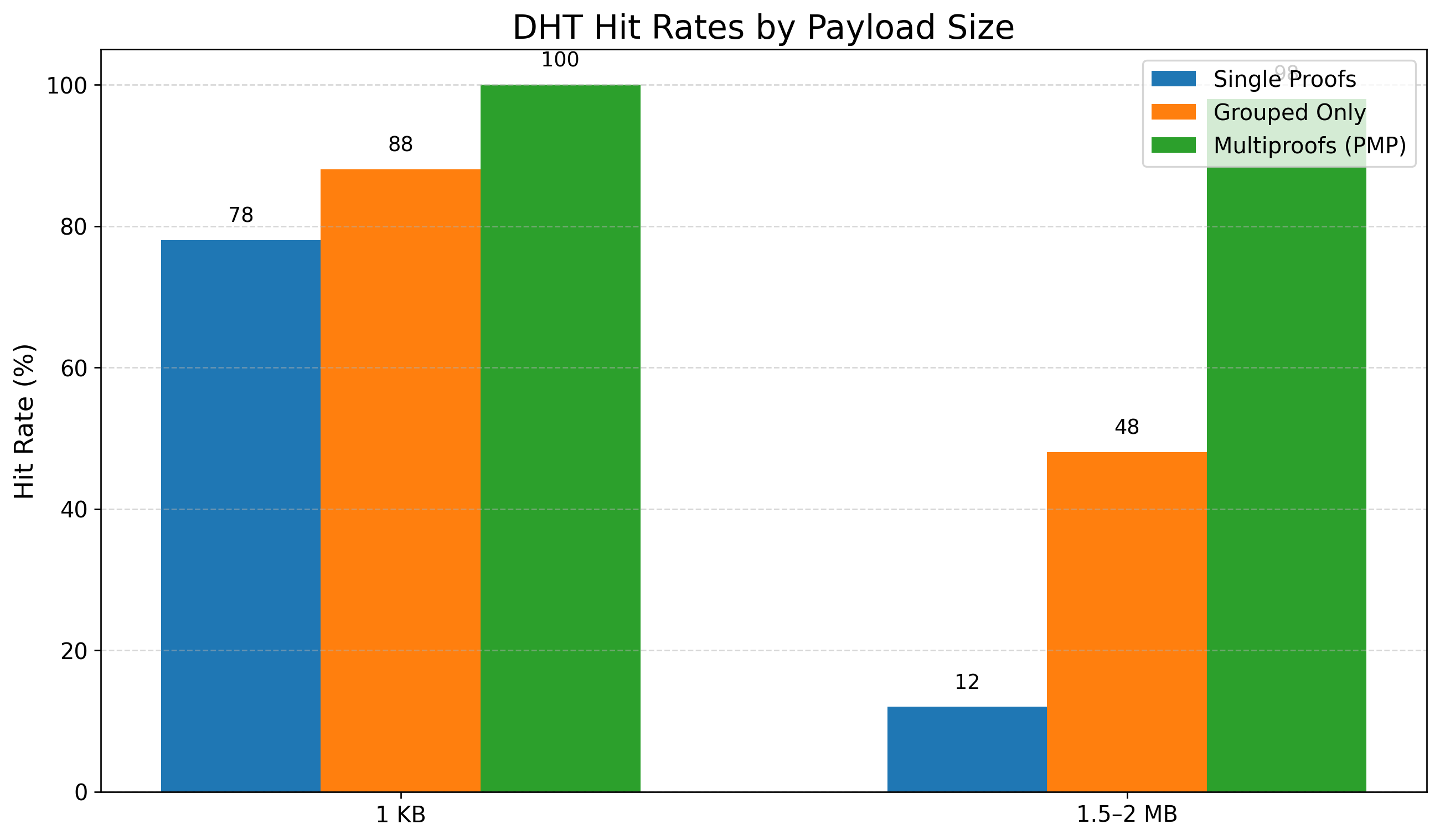
Figure 5: DHT hit rates benefit significantly from PMP and grouping, especially at large block sizes.
Service Capacity and Infrastructure Reduction
PMP reduces the number of required fat clients and servers to meet latency targets. Under a 1 KB scenario, serving fat clients required drop from 40 (baseline) to 10 (PMP), and per-fat capacity at 2 MB block sizes increases fivefold.
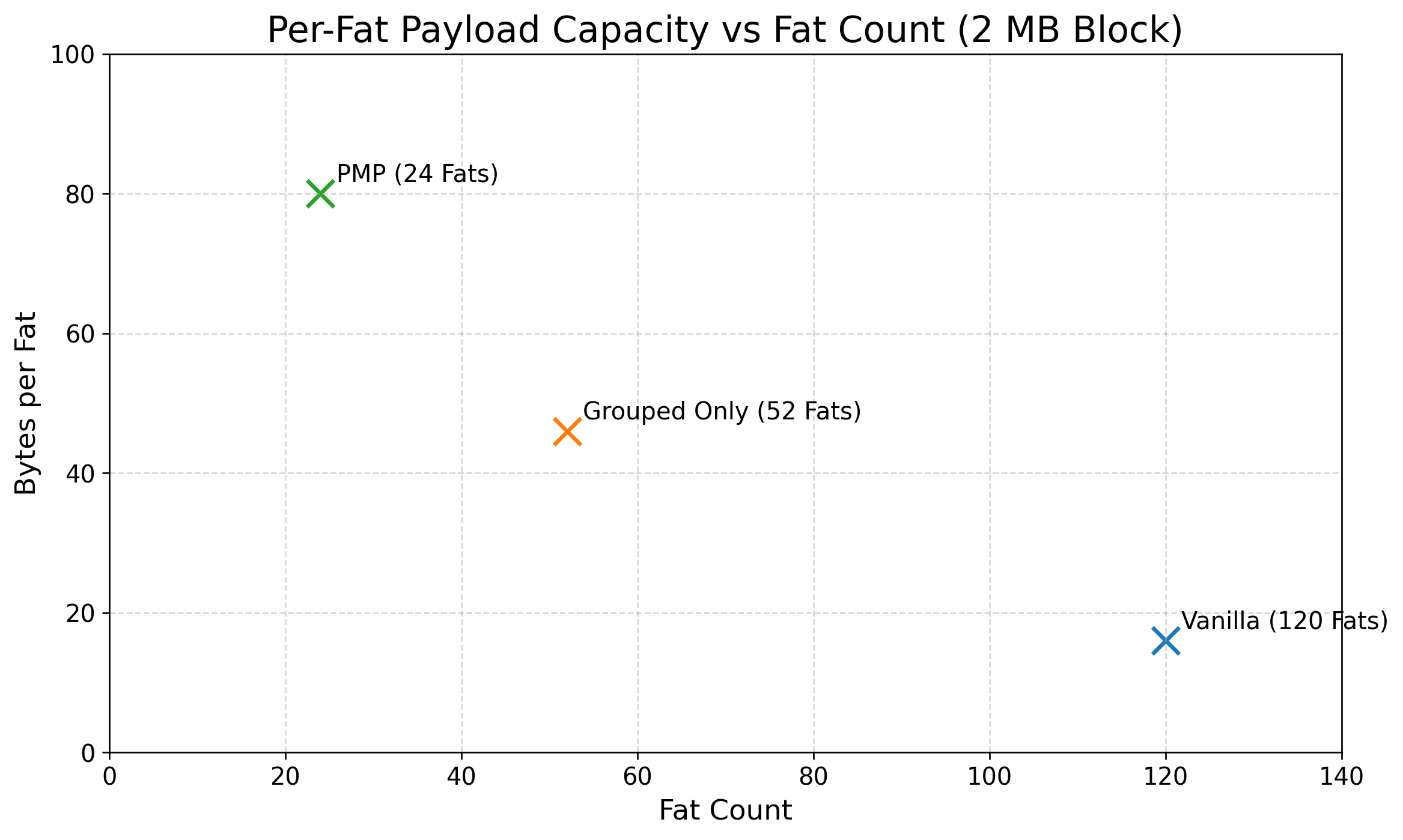
Figure 6: PMP boosts per-fat payload capacity at 2 MB block size, reducing infrastructure demand.
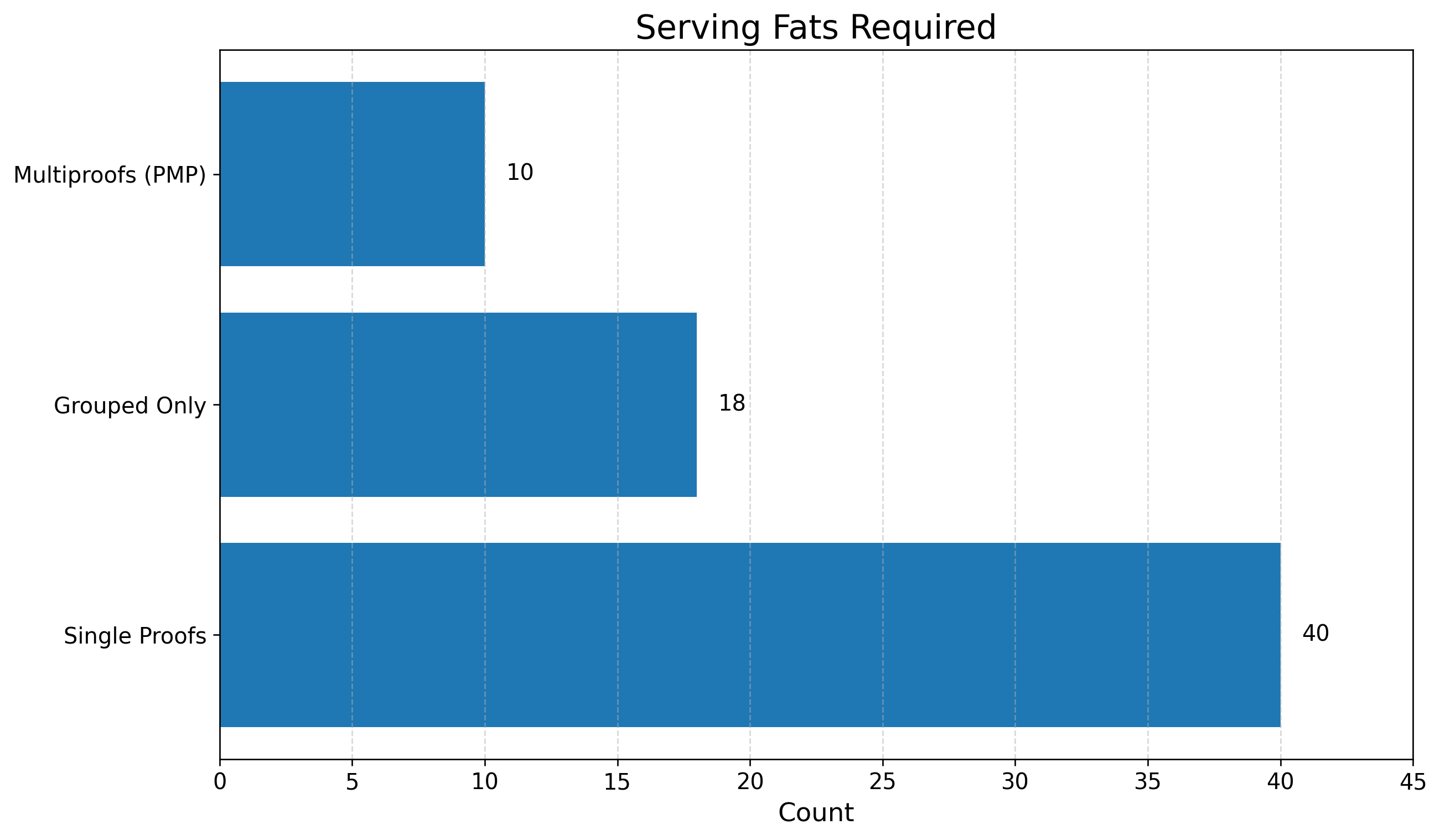
Figure 7: The number of fat clients required for the same service level is lower across PMP and grouping configurations.
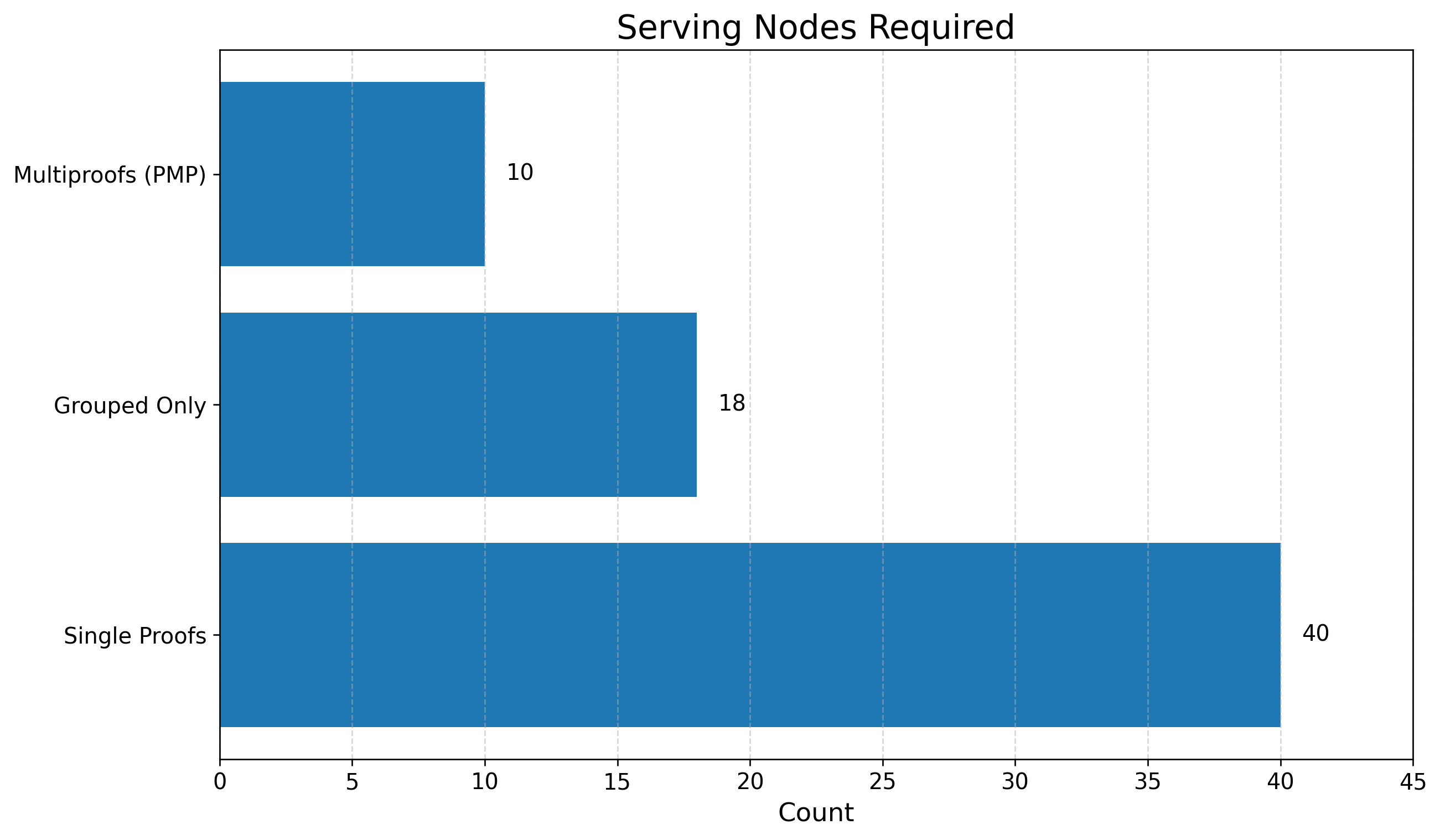
Figure 8: PMP reduces server requirements for the same latency and throughput objectives.
PMP maintains robust hit rates under moderate DHT churn, sustaining performance where the baseline fails.
Implications and Future Directions
Polynomial multiproofs systematically optimize proof transport and verifier computation in DAS workflows for blockchain light clients. By binding proofs to micro-domains and embedding deterministic grouping metadata, the approach preserves security semantics while improving locality and infrastructure efficiency. The explicit analysis of trade-offs—privacy, correlation, soundness—allows practitioners to rationally tune parameters.
Practically, the design enables significant reductions in computational and infrastructural costs for modular data availability layers. Theoretically, the results inform future protocol designs regarding aggregation semantics, transcript integrity, and adversarial routing models. The PMP pattern can complement dissemination optimizations (e.g., PANDAS), and may extend to protocols with similar proof amortization requirements, such as sharded or rollup-centric networks.
For future research, deeper adversarial modeling in routing, formally quantifying privacy risks, and integrating multiproof aggregation with advanced dissemination substrates are priorities. The design’s modularity suggests adaptability in heterogeneous blockchain contexts and potential for further cryptographic aggregation protocols.
Conclusion
The paper demonstrates that polynomial multiproofs confer substantial systems-level advantages to light-client DAS architectures, yielding up to 45% reductions in verifier overhead and infrastructure footprint. The engineered implementation in Avail provides empirical validation, highlighting the practical viability of multiproof-enabled grouping for scalable peer-to-peer data availability sampling.