- The paper introduces LGF, which integrates discrete grammar-based latent representations with flow-based sampling to directly discover both explicit and implicit ODEs.
- The paper employs a Grammar Quantisation Autoencoder and behavioral latent distance to enhance sample efficiency and accurately capture system dynamics.
- The paper validates the LGF approach on multiple benchmarks, demonstrating competitive error metrics and robust recovery in noisy, complex dynamical systems.
Neuro-Symbolic ODE Discovery with Latent Grammar Flow: Technical Summary
Introduction and Motivation
The paper "Neuro-Symbolic ODE Discovery with Latent Grammar Flow" (2604.16232) addresses the longstanding challenge of inferring interpretable ordinary differential equations (ODEs) from empirical data. The authors highlight that while deep neural approaches for dynamical system identification have exhibited strong predictive accuracy, their black-box nature limits transferability and interpretability. State-of-the-art symbolic regression offers some interpretability by expressing models as mathematical equations; however, existing grammar-based and generative models often struggle with poor sample efficiency, restriction to explicit ODEs, and the inability to effectively embed semantic behaviors. The key contribution is the Latent Grammar Flow (LGF) framework, which introduces a discrete, grammar-driven latent space coupled with flow-based generative sampling, enabling the direct discovery of both explicit and implicit ODEs.
LGF Methodology
Grammar-Based Representations
LGF encodes mathematical expressions using context-free grammars, mapping equations to sequences of production rules. This structured approach inherently enforces syntactic constraints, facilitating nested or composite representations without the need for explicit expression trees or transformer-based sequential token models.
Grammar Quantisation Autoencoder (GQAE)
The GQAE is a core architectural innovation, embedding rule sequences into a discrete latent space via finite scalar quantisation (FSQ-AE). Compared to continuous embeddings (e.g., grammar VAE), this quantisation reduces the dimensionality of the latent space, improving sample efficiency and drastically lowering the computational cost associated with rejection sampling in continuous relaxations. Training combines reconstruction loss with a semantically informed behavioral distance, discussed below.
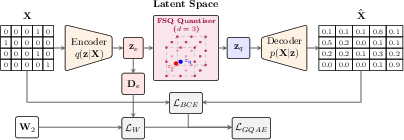
Figure 1: Overview of the GQAE training pipeline with semantic loss based on the Wasserstein distance between behavioral distributions.
Behavioral Latent Distance
A behavioral loss component, based on the logarithm of the mean squared Wasserstein distance, is introduced to structure the discrete latent space such that semantically similar equations (i.e., those with similar dynamical behaviors under variation of constants) are mapped to proximal latent points. This distinguishes LGF from methods that only enforce syntactic similarity, improving the alignment of latent representations with observed system dynamics.
Discrete Flow Models and Conditional Guidance
A discrete flow matching framework is deployed over the GQAE latent space, where sampling is guided via learned predictors and Markov-rate process updates. Integration of domain knowledge is realized in two forms:
- Grammar constraints: Defining the class of admissible equations.
- Conditional predictors: Encapsulating properties like system order and stability, enabling guidance of the generative process towards physically plausible and domain-adherent solutions.
Conditional guidance is extended to handle multiple predictors, not only enforcing static (e.g., order) but also dynamic (e.g., stability) constraints through joint conditional probability modeling.
Scalar Optimization and Discovery Process
LGF employs a nested optimization structure: the outer loop samples symbolic "skeletons" from the discrete latent space, and the inner loop uses a derivative-free Nelder-Mead procedure to optimize associated scalar constants. Stability is assessed via Lyapunov’s indirect method (for autonomous regimes) or by numerical evaluation otherwise, guiding the search toward stable, meaningful dynamics. The total loss balances equation accuracy (by residuals or solution error) and parsimony (model complexity), with explicit termination and simplification heuristics for efficient discovery.
Experimental Results
The authors evaluate LGF on three ODE benchmarks, comparing its performance with transformer-based (ODEFormer), evolutionary (PySR), and grammar-based (ProGED, GODE) baselines. All evaluation metrics use relative ℓ2 error and model complexity.
Benchmark 1: First-order Explicit ODEs
LGF achieves similar accuracy to ProGED, outperforming ODEFormer and GODE. PySR, due to exhaustive search, exhibits the lowest error but at the cost of increased expression simplicity, whereas LGF aligns closer to ground-truth complexity. The distribution of errors demonstrates competitive sample efficiency and reliability.
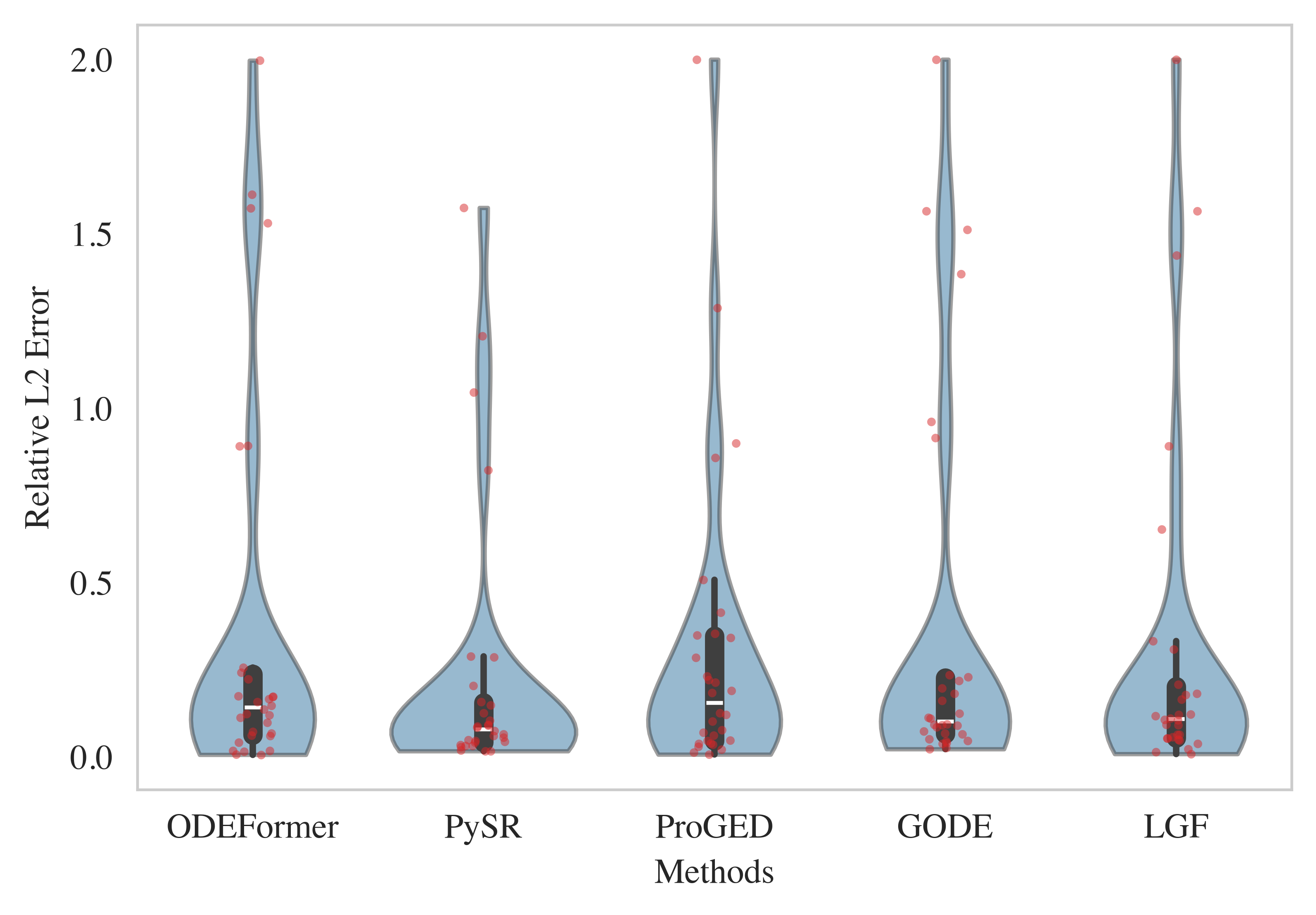
Figure 2: Distribution of relative ℓ2 errors in Benchmark 1, indicating LGF’s competitive performance.
Benchmark 2: Linear and Nonlinear ODEs
On both linear and nonlinear second-order ODEs, LGF consistently yields the minimum or second-best average errors across variables, with competitive complexity. Notably, it demonstrates higher sampling efficiency than GODE due to the discrete latent space and guided exploration.
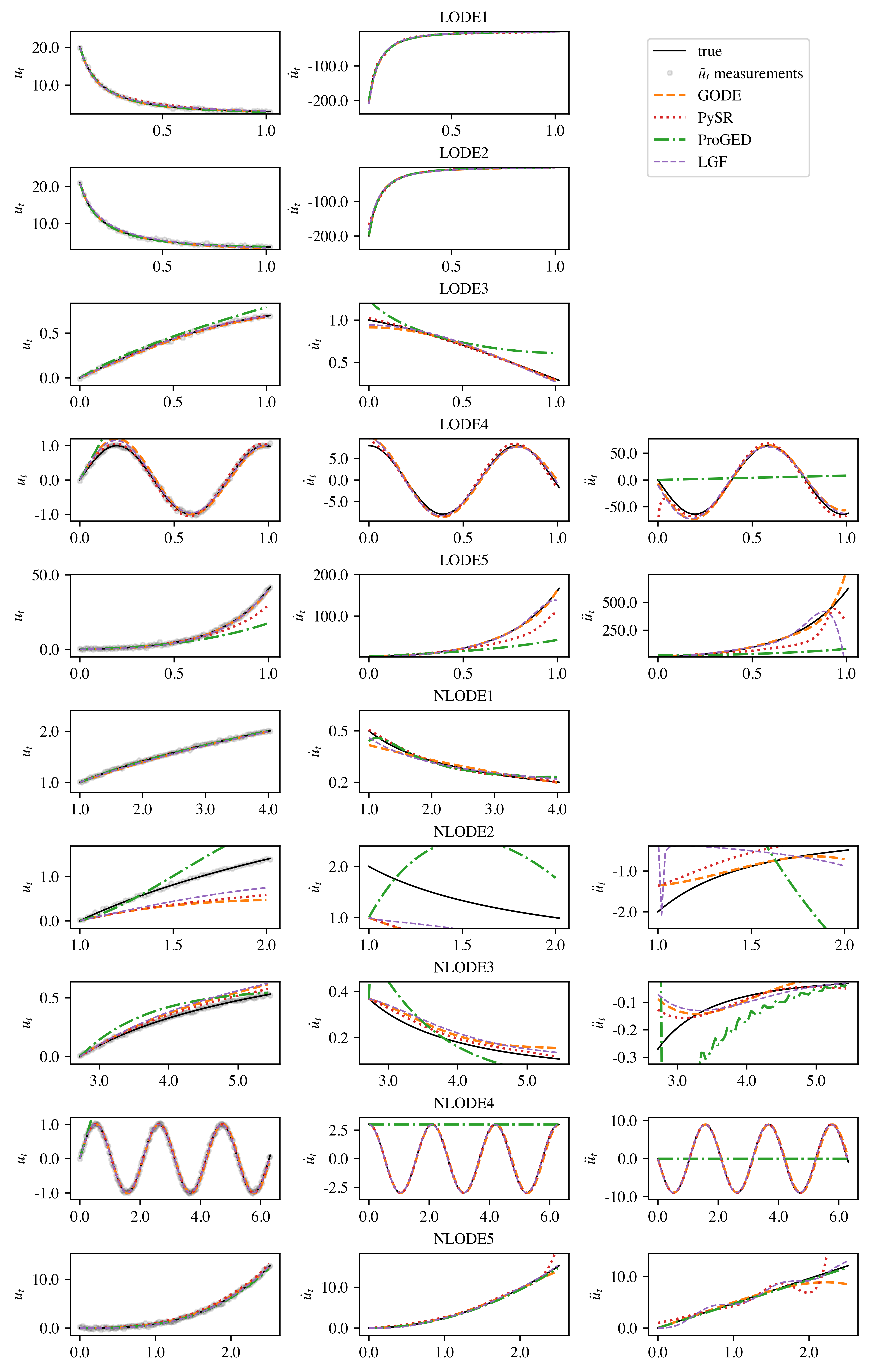
Figure 3: Comparison of ground truth and predicted ODE trajectories by LGF and baselines in Benchmark 2, highlighting superior fidelity.
Benchmark 3: Partially Observable and Noisy Dynamical Systems
In higher-order, partially observable, and noisy settings (including systems such as the Duffing oscillator and van der Pol oscillator), LGF substantially outperforms PySR in both error metrics and qualitative behavior recovery, particularly when accurate solution trajectories are required. LGF's structural priors prevent trivial or misleading regressions that arise in baseline approaches which only minimize ODE residuals.
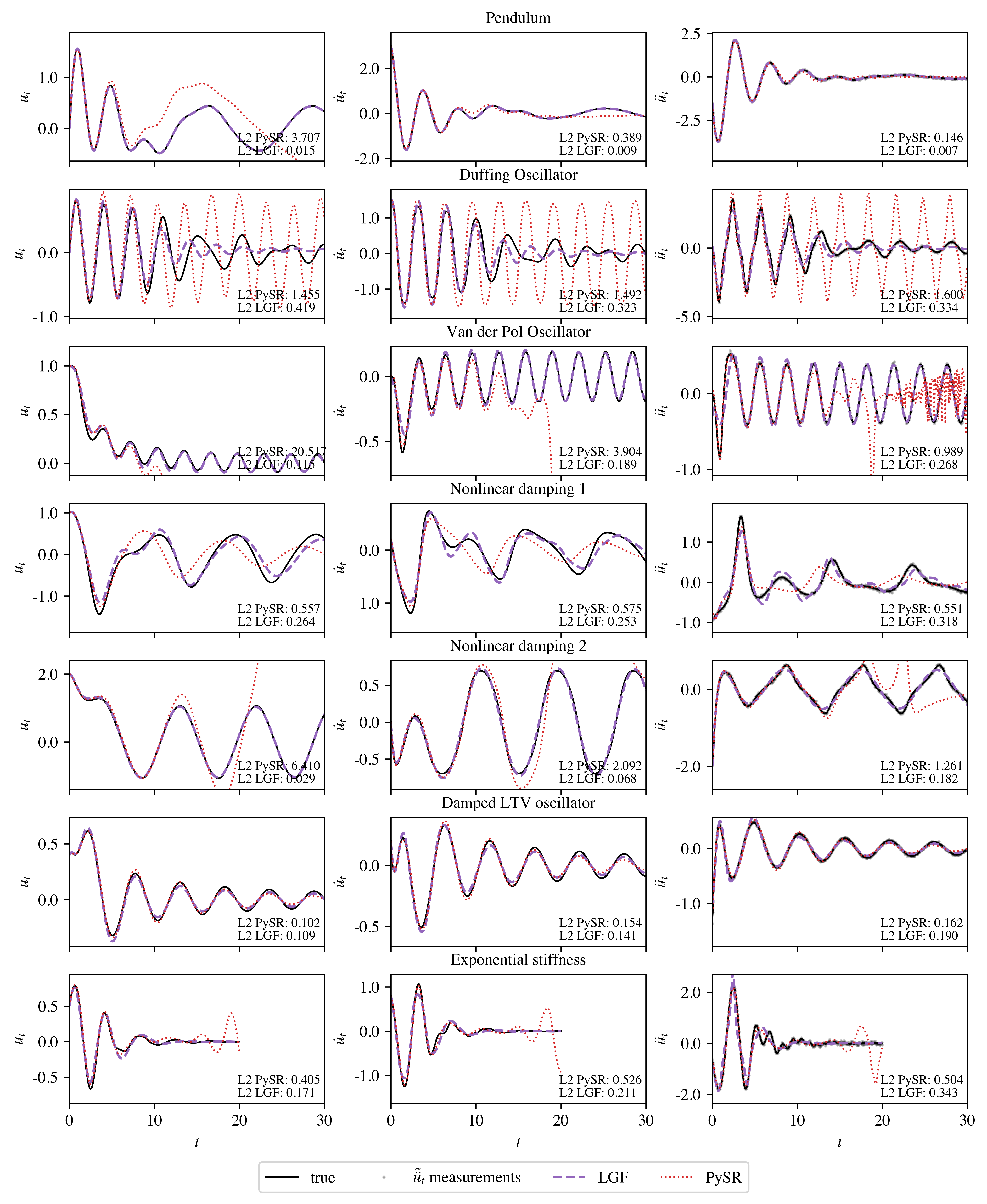
Figure 4: Solution trajectory comparison for complex systems in Benchmark 3, showing LGF’s alignment with ground truth.
Implications and Future Directions
The LGF framework demonstrates how structured discrete latent spaces, informed by behavioral distances and guided generative sampling, can significantly improve the efficacy and physical plausibility of data-driven ODE discovery. The ability to integrate domain knowledge during sampling and optimization allows for the embedding of expert priors (such as stability or system order) while remaining fundamentally data-driven. The discrete quantized latent structure prevents the relaxation errors characteristic of continuous VAE-style methods and achieves improved sample efficiency over Monte Carlo approaches.
Practically, this method is especially suited for scenarios requiring interpretable models, reliable extrapolation, and transferability—such as scientific system identification, engineering diagnostics, and control. Theoretically, LGF introduces new possibilities for multi-modal and multi-domain equation discovery, including extension to larger, higher-dimensional systems or those with more sophisticated physical or statistical invariants.
Future developments could include expanding the class of systems (e.g., partial differential equations, stochastic dynamics), refining behavioral metrics, incorporating autonomy and additional semantic constraints, or integrating LGF with LLMs/transformers for grammar generation while leveraging the sample efficiency and guidance of discrete flow-driven latent spaces.
Conclusion
Latent Grammar Flow provides a rigorous neuro-symbolic ODE discovery pipeline that fuses structured grammar representations, discrete semantic latent embeddings, and guided generative flow models. Empirical evaluation substantiates its performance and sample efficiency across diverse benchmarks, achieving strong equation accuracy and maintaining interpretable complexity. LGF represents a substantial advancement towards interpretable, domain-knowledge-integrated data-driven equation discovery, with meaningful implications for ongoing work in symbolic regression and automated scientific modeling.