- The paper presents a trainable optical neural network architecture that leverages DMD-based programmable scattering and in situ neural architecture search to adapt its structure.
- It employs a hybrid training protocol combining optical forward inference with digital backpropagation to overcome simulation-hardware mismatches and quantization challenges.
- Demonstrated on tasks like 3D CT classification and genomics, TRON achieves competitive accuracies and significant energy efficiency improvements compared to state-of-the-art digital models.
TRON: A Trainable, Architecture-Reconfigurable Random Optical Neural Network
Introduction and Context
The computational demands of deep neural networks have prompted the search for alternative, energy-efficient machine learning substrates. Optical computing, leveraging the inherent parallelism and bandwidth of photonic systems, promises considerable advantages in speed and energy consumption for matrix-intensive inference. However, almost all previously proposed optical neural network (ONN) architectures have suffered from rigid, shallow, and fixed architectures constrained by hardware, and limited reconfigurability. This deficiency has precluded the full exploitation of the computational potential of deep architectures in optics.
The paper "TRON: Trainable, architecture-reconfigurable random optical neural networks" (2604.16228) introduces Trainable Random Optical Neural Networks (TRONs), a high-dimensional, reconfigurable optoelectronic machine learning platform. The core innovation is the combination of programmable optical scattering using a digital micromirror device (DMD) as a high-capacity, trainable, dense linear transform, hybrid digital-optical backpropagation training, and an in situ neural architecture search (NAS) loop executed entirely on the physical optical hardware. These elements enable both scalable and flexible architectural complexity, in contrast to rigid, hand-crafted architectures typical in prior ONNs.
TRON Architecture and Reconfigurability
TRON departs from conventional static optical random projections by introducing controlled, task-adaptive trainability into the high-dimensional optical mixing process. The DMD pixels are split: one group encodes input data; another is dedicated as trainable parameters. This partition allows the scattering medium to realize a tunable, high-capacity transformation, with nonlinearity imposed at the optical readout via intensity detection at the CMOS camera, functioning as a physical neural layer. The platform supports time-multiplexed reuse of this programmable optical core, enabling flexible variation of network depth, width, and connectivity—all within a single hardware setup.
This temporal feedforwarding facilitates exploration of architectural motifs analogous to deep, wide, and hybrid digital neural networks, but realized directly in optics, circumventing the need for cascading distinct physical layers. An in situ NAS procedure evaluates candidate architectures directly on the hardware by measuring validation accuracy for various configurations, and selects connectivity adapted both to the target task and properties or constraints of the optical system.
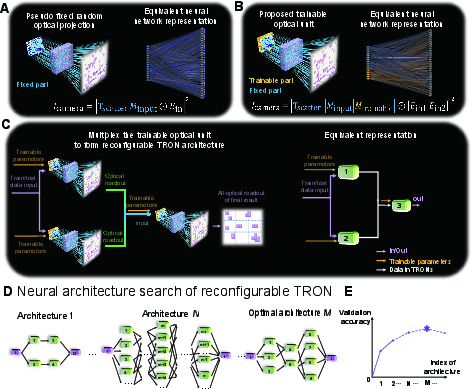
Figure 1: Conceptual overview of TRON: (A) static random optical projection; (B) trainable optical unit via DMD partitioning; (C) architecture flexibility by temporal multiplexing; (D) in situ NAS on hardware; (E) architecture selection by validation accuracy.
Hybrid Training and In Situ Optimization
A hybrid training protocol is implemented to optimize both the architectural parameters (via NAS) and the DMD-encoded trainable weights. The optical system executes forward inference, with gradient information for backpropagation computed digitally using an optics-aware transmission matrix model as a digital twin of the scattering medium. This partitioning offloads the computational workload of inference to the optical hardware, maintaining practicality for large-scale models and datasets, while retaining plasticity and error signal propagation in the digital regime during training.
In situ training is found to be necessary to bridge the considerable gap between numerical simulation and hardware reality. Models trained purely in silico exhibit marked deterioration when deployed, suffering from substantial simulation-hardware mismatch that is only resolved by additional on-hardware optimization. This is attributed to non-idealities, noise, and drift in the physical system not captured in prior, abstract models.
To validate the expressive scalability of TRON, the platform is evaluated on demanding, high-dimensional problems, including volumetric 3D medical CT classification using the MedMNIST dataset and genomics classification on RNA expression profiles (222,284 input genes, seven-class classification).
In both cases, the TRON system leverages in situ NAS to design architecture topologies tailored to the constraints and nonlinearities of the hardware. For 3D medical CT classification, the selected TRON architectures achieve a test accuracy of 79.02%, matching or exceeding state-of-the-art digital neural networks (ResNet-18/ResNet-50 2.5D variants: 78.8%/76.9%), despite the TRON working with quantized (binarized) optical inputs and operating under optics-mandated constraints. When accounting for the dominant share of computation realized in optics (∼8×10⁹ operations per sample through the fixed transmission matrix, plus 3×10⁵ trainable operations), the system matches or surpasses digital workloads in terms of information processing scale, with the forward-pass computational energy almost entirely optical.
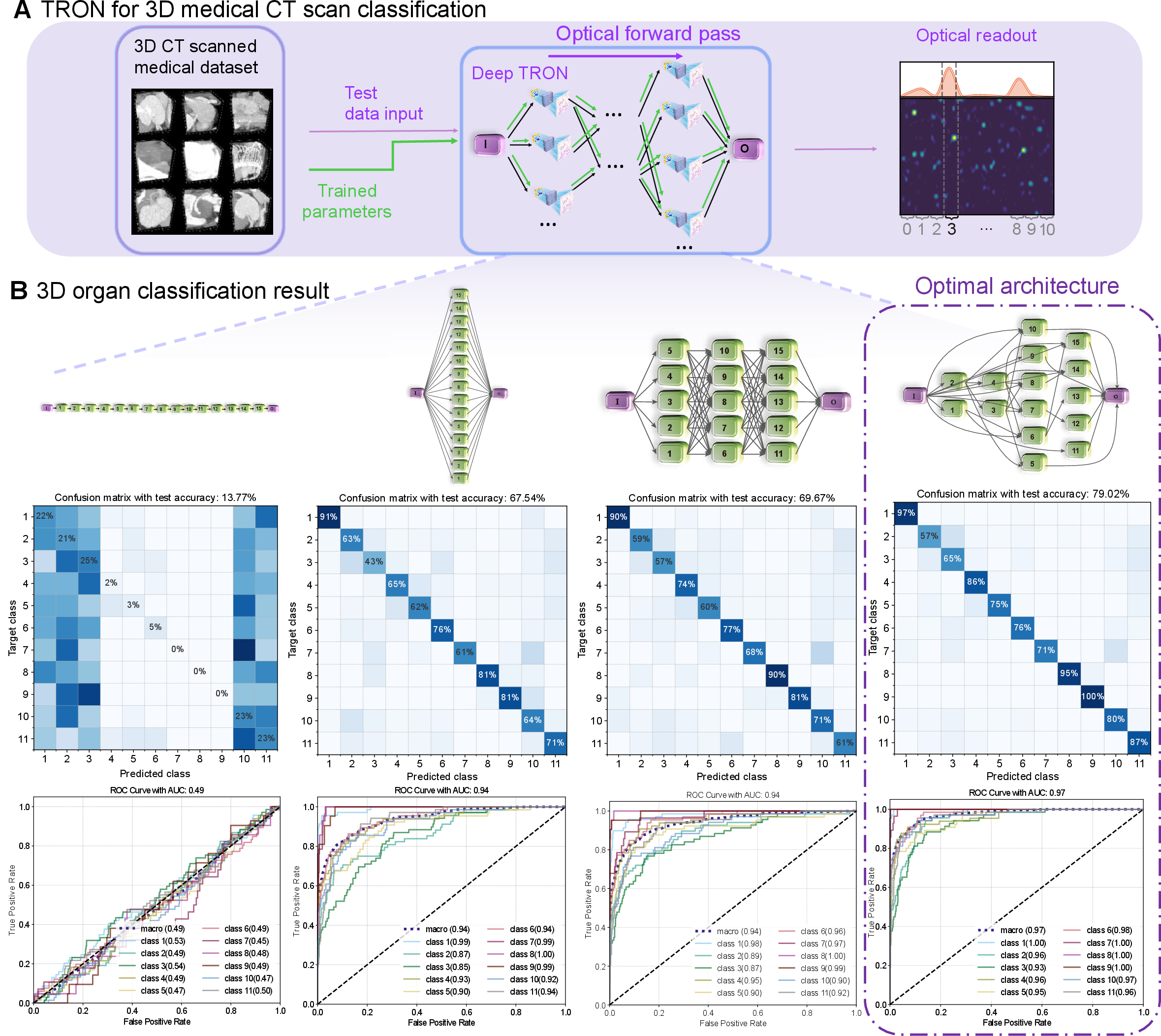
Figure 2: TRON applied to large-scale 3D medical CT organ classification: task setup, inference flow, and comparative performance of various architectures.
Beyond accuracy, this demonstrates the viability of optical hardware for real-world, high-dimensional machine learning tasks—not merely as proof-of-concept for shallow or toy datasets.
The evolution of the in situ optimization, both for weights and architecture, shows that TRON architectures favor non-trivial connectivity (e.g., skip connections) that are not intuitively discoverable via hand-design, but are favored by the hardware's need for compensation of quantization errors and noise accumulation across layers.
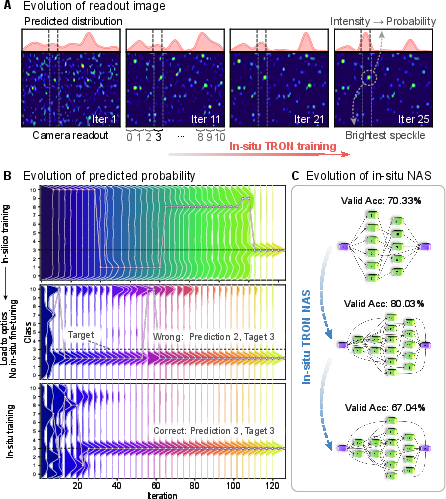
Figure 3: Top: Evolution of the optical readout during in situ training, showing energy reallocating towards correct class regions. Middle: Probability evolution highlights deployment mismatch after simulation—resolved by in situ retraining. Bottom: Architecture search trajectory exploring complex, high-performing candidates.
Practical and Theoretical Implications
The demonstration of scalable, task-adaptive ONNs reconfigurable in hardware has immediate implications for data-intensive computing where power and latency constraints are paramount. TRON suggests the feasibility of future accelerators combining optoelectronic hardware, physical nonlinearity, and architecture search loops, with prospective orders-of-magnitude improvement in energy efficiency compared to state-of-the-art digital accelerators.
From a theoretical perspective, the platform's success is shown to depend on genuine hardware–algorithm co-design: architectures optimized purely in simulation underperform due to unmodeled hardware idiosyncrasies, while TRON's in situ NAS uncovers topological motifs compensating for quantization, noise, and device nonidealities. This coupling of physical device constraints, architecture search, and statistical learning is a defining aspect distinguishing TRON from prior optical and hybrid systems.
There remain practical challenges in further scaling throughput (currently gated by optoelectronic I/O bandwidth and system stability) and in generalizing to broader classes of tasks. Anticipated advances in metasurfaces, spatial light modulators, and high-speed optical sensors are expected to alleviate some of these bottlenecks and extend the computational scalability of future TRON-like systems.
Conclusion
TRON establishes a scalable, programmable optical machine learning platform with practical, in situ architecture search and training, demonstrating parity with strong digital learners on high-dimensional medical and genomics tasks. The results underscore the practical necessity of hardware-aware optimization (NAS and in situ training) and the opportunity for algorithm–hardware co-design principles in future non-von-Neumann computation for AI workloads. As integrated photonics, optical modulation, and readout technologies mature, TRON-like architectures are poised to influence the design of next-generation, energy-efficient machine learning accelerators.

