- The paper presents a novel multi-agent framework that emulates the radiology workflow through resident, fellow, and attending roles to enhance CT report accuracy.
- It leverages retrieval-augmented revision and iterative consensus to mitigate clinical hallucinations and improve evidence-based decision making.
- The approach outperforms existing benchmarks on CT report datasets, yielding significant gains in clinical efficacy and auditability.
MARCH: Multi-Agent Radiology Clinical Hierarchy for CT Report Generation
Introduction and Motivation
Automated generation of diagnostic reports from 3D radiology data such as chest CT remains a key challenge in medical AI, primarily due to the propensity of conventional Vision-LLMs (VLMs) for clinical hallucinations, suboptimal grounding of findings, and the absence of multi-step verification common in human clinical workflows. MARCH (Multi-Agent Radiology Clinical Hierarchy) introduces a modular, hierarchical, multi-agent framework that explicitly models the collaborative radiology read-out process, incorporating roles analogous to Resident, Fellow, and Attending radiologists. This design leverages multi-agent negotiation and retrieval-augmented reasoning to enhance report accuracy, clinical fidelity, and interpretability compared to monolithic black-box approaches.
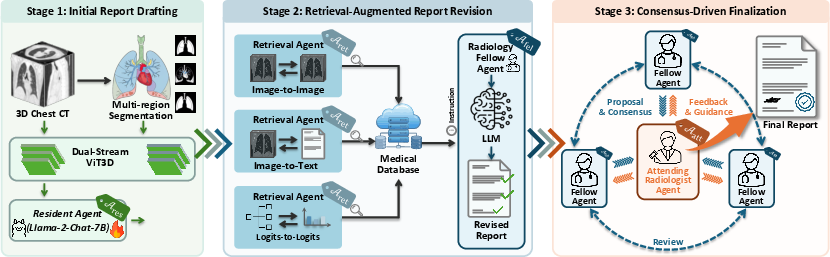
Figure 1: Schematic of the MARCH pipeline, highlighting initial drafting, retrieval-augmented revision, and consensus-driven finalization.
Methodological Framework
Multi-Agent Clinical Workflow Emulation
MARCH operationalizes three key stages:
- Initial Report Drafting: A Resident Agent equipped with a 3D ViT encoder and region-level segmentation (based on SAT) generates a preliminary report localized to ten anatomical regions. This component focuses on aligning features from volumetric CT with textual radiology descriptors, mitigating the sparsity of findings typical in chest CT imaging.
- Retrieval-Augmented Report Revision: Retrieval Agents perform multi-modal similarity search (image-image, image-text, logits-based) against a clinical database, surfacing top-k relevant scans and reports. Fellow Agents then receive this evidence, cross-examine the resident draft, and issue regionally-anchored revisions, designed for both omission correction and hallucination reduction.
- Consensus-Driven Finalization: An Attending Agent orchestrates iterative consensus meetings wherein multiple Fellows submit stances (agreement/correction/supplementation) with explicit supporting evidence and confidence ratings. Attending adjudicates, revises, and cycles until either unanimous agreement or discursive stasis is achieved.
This arrangement ensures not only staged hypothesis checking and error correction but also traceable rationales for each recommendation, thereby addressing the prevalent demand for auditability in clinical decision-support AI.
Experimental Evaluation
Dataset and Metrics
Evaluation is performed on the RadGenome-ChestCT dataset comprising 25,692 chest CT scans from 21,304 patients, with rich annotations across ten anatomical regions and 18 distinct clinical abnormalities. Report generation quality is assessed using standard metrics (BLEU, METEOR, ROUGE-L) as well as a domain-specific Clinical Efficacy (CE) score computed via RadBERT-RoBERTa-4m, capturing precision, recall, and F1 for abnormality identification.
State-of-the-art Comparison
MARCH achieves dominant performance across all conventional and clinical metrics relative to competitive baselines (e.g., R2GenPT, MedVInT, CT2Rep, M3D, RadFM, Reg2RG). Notably, MARCH posts an F1-score of 0.399 (CE-F1), substantially ahead of prior models.
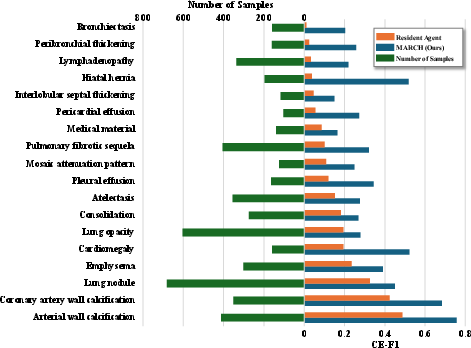
Figure 2: Clinical efficacy (F1-score) dissected by abnormality, with pronounced performance gains for subtle pathologies such as hiatal hernia and pericardial effusion.
Ablation and Sensitivity Analyses
Ablation studies confirm that each architectural innovation—retrieval augmentation, multi-agent review, and iterative consensus—contributes incrementally to report fidelity and precision. The consensus phase yields the most dramatic absolute gains, underscoring the critical importance of iterative refinement. Sensitivity to the choice of LLM (GPT-4.1, GPT-4o, GPT-5) in the fellow/attending roles is limited; all advanced LLM variants confer comparable benefits beyond the Resident-only baseline.
Case Study and Interpretability
A detailed case analysis demonstrates the breakdown of collaborative improvement: the Resident Agent's draft report is refined by Fellows leveraging database retrieval, and the Attending Agent’s synthesis incorporates and reconciles outstanding discrepancies. MARCH's final output not only recapitulates reference-grade clinical content but can be fully audited for diagnostic lineage and decision provenance.
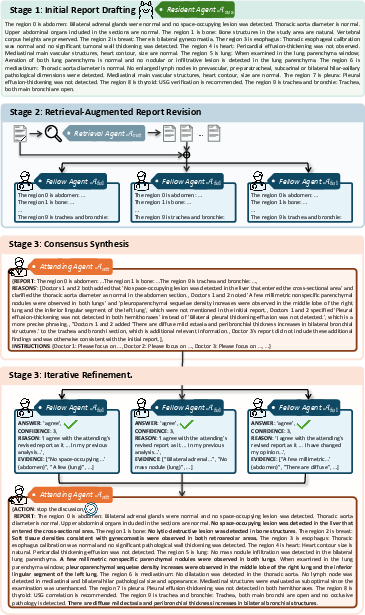
Figure 3: Case workflow showing sequential drafting, evidence-based revision, and hierarchical consensus with explicit region-wise findings.
Representative report examples reveal the systematic filtering of extraneous or uncertain statements (as found in single-agent generations) and the synthesis of concise, clinically grounded, and actionable findings.
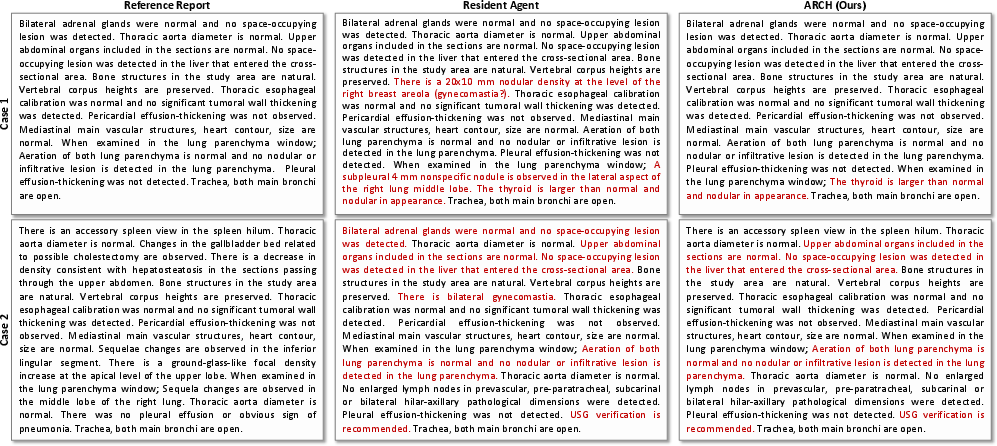
Figure 4: Representative reports produced by MARCH, exhibiting improved alignment with reference ground-truth and suppression of hallucinated details.
Clinical Efficacy Analysis
Comprehensive breakdown of clinical efficacy across abnormalities illustrates substantial improvements in the detection of diagnostically challenging findings—particularly those with low prior probability or subtle imaging presentation. MARCH maintains strong precision-recall tradeoffs, avoiding over-sensitivity at the expense of false positives.
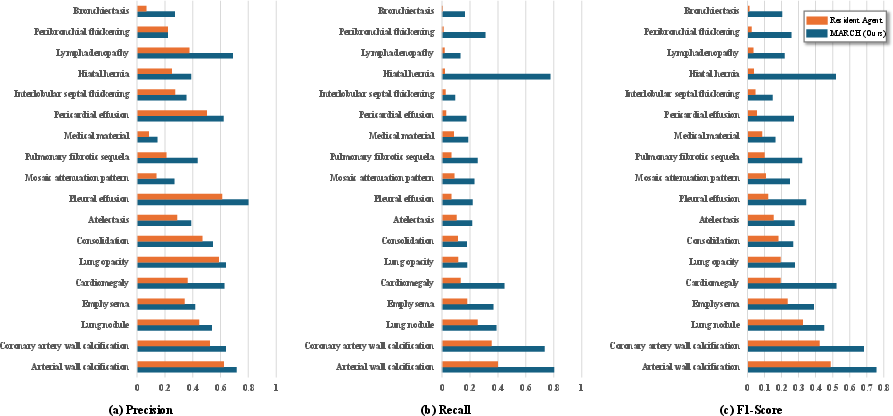
Figure 5: Per-abnormality breakdown of clinical efficacy: (a) Precision, (b) Recall, (c) F1-score.
Implications and Future Outlook
MARCH’s explicit modeling of professional clinical workflow represents an important shift towards decomposable, interpretable, and auditable medical AI. By codifying multi-agent negotiation with retrieval augmentation and providing pinpointed rationales, MARCH not only mitigates the risk of diagnostic hallucination but also builds the infrastructural foundation for future, human-in-the-loop collaborative systems. The implications are substantial for regulatory acceptance, clinical deployment, and downstream error analysis.
Future work should extend MARCH towards: (1) plug-and-play deployment with diverse generalist or domain-specific LLMs for improved generalization; (2) integration of longitudinal patient memory; and (3) hybrid, augmentation-based interfaces for real-time clinician feedback, potentially enabling continuous postdeployment improvement and audit.
Conclusion
MARCH demonstrates robust performance improvements in automated CT report generation via hierarchical, retrieval-augmented, and consensus-driven multi-agent cooperation. The work provides strong evidence that explicit workflow emulation, collaborative negotiation, and fine-grained evidence integration materially enhance the reliability and trustworthiness of high-stakes medical report generation. These findings establish a new methodological paradigm for clinical AI grounded in organizational structure, transparency, and error minimization.

