- The paper introduces a novel feedback-driven NL2SQL system that enhances clinical query accuracy via schema-guided predicate decomposition and expert exemplar retrieval.
- It leverages large language models, dense sentence embeddings, and interactive clinician feedback to generate reproducible, auditable SQL queries.
- Experimental results show significant improvements in execution accuracy and structural fidelity over conventional prompting methods for oncology databases.
FD-NL2SQL: Feedback-Driven Clinical NL2SQL that Improves with Use
Overview and Motivation
FD-NL2SQL addresses a persistent bottleneck in querying oncology clinical trial repositories by introducing a schema-aware, feedback-driven NL2SQL system. The core problem is that clinicians require ad-hoc, multi-constraint exploration of complex databases, but manual SQL construction is prohibitively technical given intricate schema layouts. Standard NL2SQL systems, mainly optimized for open-domain benchmarks, lack domain-specific decomposition, reliable exemplar grounding, and interactive feedback mechanisms—features essential for clinical settings where query fidelity and reproducibility are paramount.
FD-NL2SQL integrates LLM based schema-guided decomposition, dense embedding retrieval of expert-verified exemplars, retrieval-guided query synthesis, and a continual feedback loop. This architecture aims to bridge the gap between domain expertise and database accessibility, reducing reliance on technical intermediaries and ensuring robust, transparent clinical evidence review.
System Architecture
The system operates as an interactive assistant, coupling LLM-driven reasoning with retrieval from an evolving exemplar bank and lightweight programmatic checks.
Schema Grounding and Predicate Decomposition: The workflow starts with schema introspection, using metadata to guide prompt context and validation. Upon receiving a natural-language question, an LLM decomposes it into atomic predicates aligned with database columns and operators, facilitating granular constraint extraction.
Exemplar Retrieval via Sentence Embeddings: For each predicate, the system calculates sentence embeddings using Sentence-BERT to retrieve top-k semantically similar, expert-verified question-SQL exemplars. This retrieval grounds the synthesis in proven patterns and mitigates schema drift, particularly in domains with unconventional field names and complex eligibility structures.
Retrieval-Guided SQL Synthesis: Conditioned on the question, predicate decomposition, and retrieved exemplar bundles, a second LLM synthesizes the SQL query. Controlled decoding ensures structural adherence and constraint satisfaction, with programmatic guards to enforce read-only policies and schema validity.
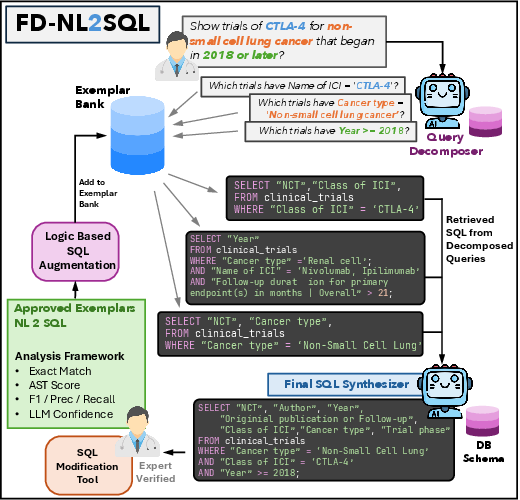
Figure 1: End-to-end workflow of query decomposition, exemplar retrieval, SQL synthesis, and interactive feedback-driven expansion of the exemplar bank.
Feedback-Driven Bank Expansion: The UI lets clinicians preview, edit, and approve generated queries. Approved SQL pairs are appended to the exemplar bank after embedding. To minimize annotation, single atomic mutations (e.g., operator, column, or value changes) are applied to approved queries; only variants that execute successfully and yield non-empty results are retained. These mutated SQLs are back-translated to natural-language questions and decompositions, auto-expanding the bank and supporting continual improvement.
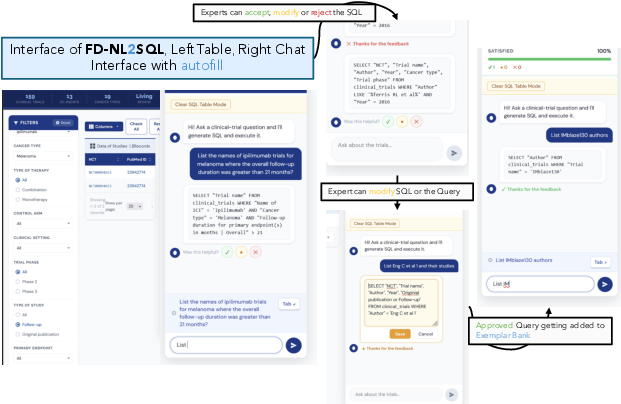
Figure 2: Demo UI showcasing the interactive chat interface for NL queries, SQL previews, feedback controls, and result visualization.
Experimental Methodology
Seed Set and Benchmark Expansion: The evaluation begins with 500 expert-authored seed questions, each paired with validated SQL, targeting the IOTOX oncology table. Programmatic expansion creates 1500 total samples by atomic transformation—projection edits, predicate drops, and value relaxations—filtered for read-only policies, execution success, and non-empty outputs. Natural language variants are generated using Gemma3-27B-it, ensuring consistent NL-SQL correctness.
Baselines: Comparisons include zero-shot, few-shot, and chain-of-thought (CoT) prompting on both open and closed LLMs (Gemma3-27B-it, Qwen3-30B-A3B-Instruct-2507, gpt-5-nano/mini), as well as SQL-R1-14B, a finetuned reasoning model trained via RL.
Evaluation Metrics: The system is benchmarked using execution-based correctness (eEM), partial correctness F1 (eF1), chrF (character n-gram F-score), structural AST similarity, and LLM generation confidence. Diagnostic flags for unsafe SQL behavior are logged.
Results and Analysis
FD-NL2SQL exhibits substantial gains across all metrics relative to conventional prompting. On the most comprehensive metrics, Qwen3 paired with FD-NL2SQL achieves eEM of 40.93%, eF1 of 55.57%, AST of 86.36%, confidence of 66.30%, and harmonic mean (HM) of 66.06%. These values surpass all baselines for execution and structure.
Reliability and Robustness: All backbone models benefit from decomposition and exemplar grounding, with smaller models (gpt-5-nano, Gemma3) achieving near parity with larger ones. The feedback mechanism further stabilizes results, enabling the system to adapt to schema evolution and domain-specific patterns. Prompting-only baselines fail to consistently extract predicates or produce syntactically/semantically viable SQL, especially under complex multi-constraint queries.
Practical Utility: Clinicians gain executable, auditable traces for evidence review—decomposition, retrieval influence, synthesis, execution—facilitating rapid refinement or adaptation. With transparent feedback and expert-in-the-loop editing, FD-NL2SQL meets reproducibility and safety needs in medical data workflows.
Bank Expansion: Automatic SQL augmentation and LLM back-translation enable rapid coverage growth with minimal annotation overhead, supporting scalable adaption to new domains and evolving schemas.
Implications and Future Directions
FD-NL2SQL reifies interactive clinical NL2SQL as a "living" assistant rather than a static parser. Its architecture supports continual learning and domain adaptation, enabling practical deployment where schema change or data evolution are routine. The approach exemplifies how domain-aware NL2SQL systems can pair LLM semantic parsing with retrieval grounding and feedback loops for robust, transparent querying in sensitive biomedical settings.
Future developments could expand toward more complex joins, nested queries, aggregation patterns, and broader linguistic variation. Prospective studies measuring real clinician engagement and workflow integration are warranted, as is adaptation to additional medical domains and institutions. Improvements in automatic augmentation logic and NL-synthesis accuracy would further increase coverage and usability.
Conclusion
FD-NL2SQL provides a schema-aligned, feedback-driven NL2SQL system that reliably translates clinical questions into executable SQL. Through predicate decomposition, exemplar retrieval, and continual feedback-driven expansion, it outperforms baseline prompting methods on execution and structure metrics, enabling practical, auditable evidence-review workflows for oncology trial databases. As a self-evolving assistant, FD-NL2SQL lowers technical barriers, supports transparency, and adapts continuously to domain needs, establishing a viable template for future intelligent querying systems in medical and other high-stakes settings.

