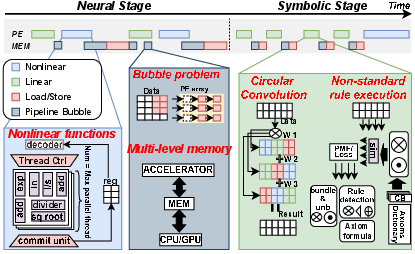
- The paper introduces a unified hardware architecture that integrates neuro-symbolic processing with in-array Padé approximations for nonlinear functions.
- It overcomes conventional hardware bottlenecks by employing preemptive memory bypass and dynamic resource reconfiguration to optimize throughput and energy efficiency.
- Experimental results demonstrate significant performance gains, including higher throughput and reduced SRAM usage compared to conventional CPU and GPU solutions.
Overmind NSA: Unified Neuro-Symbolic Acceleration via Approximate Nonlinear Computation and Memory Optimizations
Neuro-Symbolic AI: Computational and Architectural Context
Neuro-symbolic AI (NSA) frameworks seek to unify data-driven neural inference with formal symbolic reasoning, yielding both high accuracy and transparent, traceable inference. Their architectures combine connectionist modules (deep neural networks for perception) with symbolic engines (logic or vector-symbolic representations for rule-based decision-making). This integration extends model capabilities but results in heterogeneous and memory-intensive workloads with unique operator mixes: significant fractions of nonlinear activation evaluations, symbolic binding (e.g., circular convolution), and memory-bound reasoning steps.
Recent workload characterizations of NSA models, such as NVSA, LTN, and NLM, reveal that symbolic components can match or exceed neural layers in resource consumption and exhibit large-stride and irregular access patterns detrimental to efficient execution on conventional DNN accelerators (e.g., NPUs, GPUs).
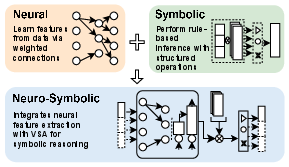
Figure 1: Integration of neural and symbolic components, enabling both data-driven learning and rule-based inference.
Comprehensive profiling confirms that nonlinear operations dominate compute costs in NSA workloads and exacerbate pipeline stalls due to frequent memory hierarchy transitions between neural and symbolic layers.
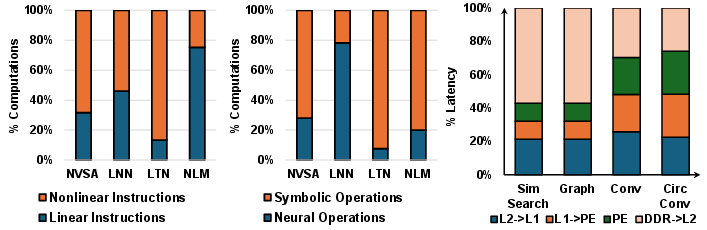
Figure 2: NSA workload profiling on (a) linear vs. nonlinear computations, (b) neural vs. symbolic operations, and (c) latency breakdown.
Key Bottlenecks in Conventional Hardware for NSA
General-purpose PE arrays and memory-centric accelerators incur significant underutilization and latency costs for NSA. The main bottlenecks are as follows:
Overmind NSA: Architectural Innovations
Overmind NSA introduces a unified architecture specifically tailored to the diverse requirements of neuro-symbolic computation, integrating four primary subsystems:
- Reconfigurable PE arrays
- Divider arrays for efficient rational function evaluation
- Preemptive dual-window memory bypass
- Streamlined memory subsystem without L2 caching
This architecture supports both conventional neural primitives and the specific symbolic ops required for NSA, with cross-layer hardware–software co-optimization for model deployment.
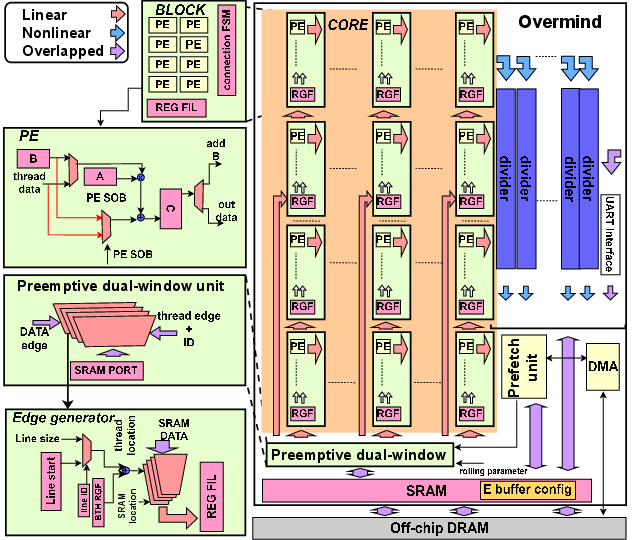
Figure 4: The Overmind NSA hardware architecture.
Padé-Based Nonlinear Approximation: In-Array Execution
Overmind leverages Padé approximants to express arbitrary nonlinear functions required by NSA as ratios of polynomials. Both numerator and denominator are computed via chained MACs within the PE array, with dedicated per-row dividers implementing the final rational computation—eliminating the need for post-processing units or large LUTs. This approach enables deterministic, fully parallel, and pipelined evaluation of nonlinearities directly adjacent to standard neural operations.
The architecture supports runtime reconfiguration: higher Padé order yields improved functional fidelity at the expense of PE subscription, while lower order increases throughput for minimal accuracy loss.
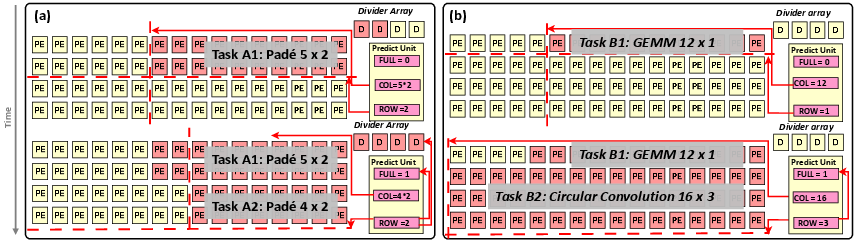
Figure 5: Reconfigurability of Overmind PE array across neural and symbolic operations. Divider arrays are enabled for approximate computations (a), but otherwise deactivated (b). Red and yellow denote active and idle units respectively.
Preemptive Memory Bypass: Eliminating Cache Overhead
For symbolic logic and vector reasoning operations, Overmind replaces L2-L1 speculation with a compile-time policy that configures data flows using tensor metadata (shape, stride, kernel size). Data is streamed from SRAM and broadcast across the PE array; dual-window comparators in each row select relevant elements using programmable filters, enabling both large-stride access and modulo-indexed (circular) retrieval for convolution. This design eliminates cache-related area and power penalties, maintains constant throughput for symbolic ops, and scales efficiently with increasing vector dimensions.
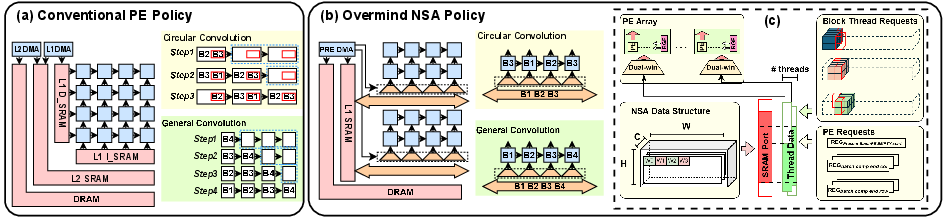
Figure 6: (a) Conventional PE policy and memory hierarchy with L2→L1 transfers. (b) Overmind's preemptive memory bypass and broadcast-based bypass design. (c) Dual-window filter logic for 2D address range filtering.
Hardware–Software Co-Optimization Stack
The complete software stack integrates compiler passes to extract and annotate operator requirements, guide hardware parameter selection (e.g., Padé order per layer), and generate execution instructions that encode both operation sequence and hardware configuration. Runtime scheduling dynamically adapts memory policies, PE utilization, and power states to the per-operation signature, supporting multi-model and online deployment without hardware rewrites.
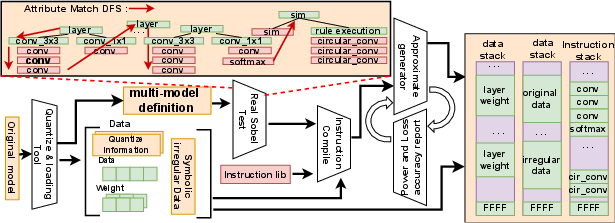
Figure 7: Software stack with hardware co-optimization.
Experimental Evaluation and Results
Nonlinear Approximation Fidelity
Padé-based approximation of nonlinearities (including sigmoid, tanh, sqrt) yields low maximum absolute error across the input domain, with error decreasing as Padé order increases. End-to-end reasoning accuracy on RAVEN/I-RAVEN benchmarks using INT8 quantized NSA models exhibits minimal degradation compared to baseline as long as Padé-4 or higher is selected; accuracy loss can be traded for throughput via compiler directive.
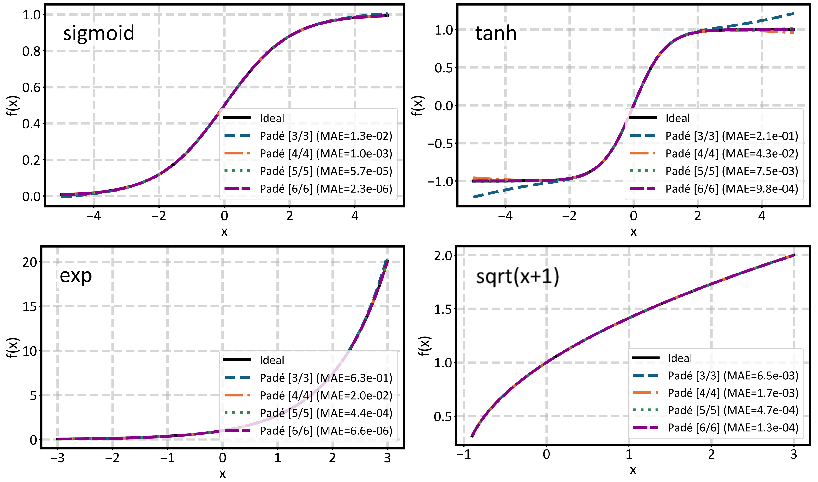
Figure 8: Comparison between ideal nonlinear functions and Padé-approximated versions.
A 32×16 Overmind implementation achieves 410 GOPS@800MHz with average energy efficiency of 8.1 TOPS/W, a marked improvement over both Xeon CPU (40.5×) and RTX GPU (8×) baselines. The architecture's area and power are dominated by the PE array and memory bypass logic, with the nonlinear approximation logic incurring modest (<6%) overheads. Removing the on-chip L2 cache saves ∼0.84 mm2 SRAM and further improves scalability.
Scalability experiments confirm that as the number of PEs increases, Overmind requires substantially less SRAM per thread than systolic or broadcast-centric PE designs, and can maintain higher PE activation rates under the same bandwidth constraints.
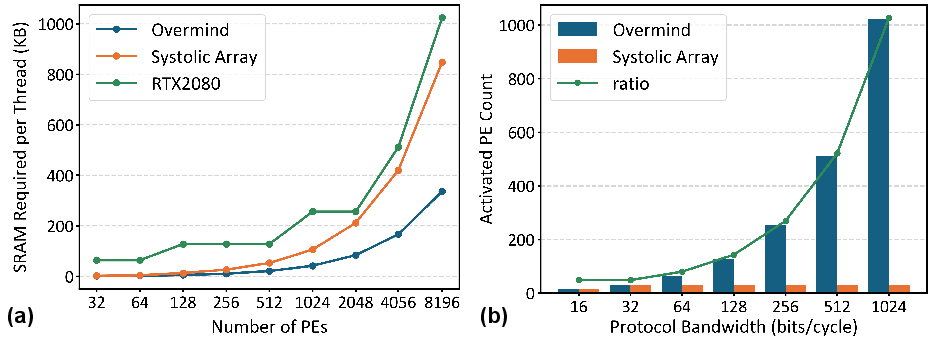
Figure 9: Scalability analyses: (a) Overmind requires fewer SRAM as number of PEs increases and (b) Overmind can activate more PEs given the same bandwidth.
On FPGA, Overmind reduces on-device memory usage by over 57× compared to NSFlow while achieving 1.5× higher throughput, validating benefits of the memory bypass and Padé-divided computation in a resource-constrained setting.
Implications and Prospects
Overmind NSA demonstrates that cross-layer hardware-software co-design targeting NSA workload characteristics yields significant gains in throughput, energy efficiency, and area scaling without compromising symbolic reasoning accuracy. The Padé-augmented PE array architecture offers an extensible, hardware-efficient substrate for universal nonlinear function evaluation, likely beneficial for future models incorporating more complex, bespoke nonlinearity. Elimination of hierarchical caching in favor of metadata-directed preemptive bypass points toward new accelerator topologies optimized for algorithm-structured access patterns. Compiler-guided hardware reconfiguration and accuracy–throughput trade-off will be applicable to a spectrum of edge and cloud-scale AI deployments as neuro-symbolic paradigms proliferate.
Conclusion
Overmind NSA establishes a unified, efficient hardware platform tailored for the execution of modern neuro-symbolic AI workloads, emphasizing deterministic, in-situ nonlinear computation, memory-optimized symbolic processing, and a programmable stack that enables seamless integration of diverse NSA models. The demonstrated throughput, energy efficiency, and resource savings indicate its suitability for both research prototyping and deployment in resource-constrained or large-scale environments, with broad relevance as AI hardware shifts to support increasingly hybrid inference frameworks.