Enhancing Mixture-of-Experts Specialization via Cluster-Aware Upcycling
Abstract: Sparse Upcycling provides an efficient way to initialize a Mixture-of-Experts (MoE) model from pretrained dense weights instead of training from scratch. However, since all experts start from identical weights and the router is randomly initialized, the model suffers from expert symmetry and limited early specialization. We propose Cluster-aware Upcycling, a strategy that incorporates semantic structure into MoE initialization. Our method first partitions the dense model's input activations into semantic clusters. Each expert is then initialized using the subspace representations of its corresponding cluster via truncated SVD, while setting the router's initial weights to the cluster centroids. This cluster-aware initialization breaks expert symmetry and encourages early specialization aligned with the data distribution. Furthermore, we introduce an expert-ensemble self-distillation loss that stabilizes training by providing reliable routing guidance using an ensemble teacher. When evaluated on CLIP ViT-B/32 and ViT-B/16, Cluster-aware Upcycling consistently outperforms existing methods across both zero-shot and few-shot benchmarks. The proposed method also produces more diverse and disentangled expert representations, reduces inter-expert similarity, and leads to more confident routing behavior. Project page: https://sanghyeokchu.github.io/cluster-aware-upcycling/

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (simple overview)
The paper shows a better way to turn a regular AI model into a Mixture‑of‑Experts (MoE) model so it works faster and smarter without needing huge extra training. Think of an MoE model like a team of specialists: only the best few specialists are asked to handle each input, saving time and energy. The authors’ new method, called Cluster‑aware Upcycling, helps each specialist start with a clear role from day one, so the team organizes itself quickly and performs better.
What questions the paper tries to answer
Here are the main questions the paper asks:
- If we convert a normal model into a specialist team (an MoE), can we give each expert a clear specialty right at the start instead of making them all identical?
- Can we use the knowledge already inside the original model to decide which experts should handle which kinds of inputs?
- Can we make the “router” (the part that assigns inputs to experts) start with good instincts instead of random guesses?
- Can we keep training stable and helpful when the router is unsure which expert to pick?
How the method works (in everyday language)
First, a quick picture of MoE:
- Think of a busy help desk with many specialists (experts). A router is like the receptionist who directs each question to the right specialist. In a normal “dense” model, every question goes to everyone (wasteful). In an MoE, only a few specialists work per question (efficient).
- The problem with older “upcycling” methods is that all specialists start with the same skills and the receptionist guesses randomly. That makes it hard for anyone to develop a unique specialty early on.
The new method has two big ideas and one helper:
- Find natural groups (clusters) in the model’s internal signals
- The authors run the original model on a small sample of data and look at its internal activations (like the patterns the model sees).
- They group similar activations into clusters (like sorting photos into piles of “animals,” “vehicles,” “food,” etc., based on similarity).
- This uses “spherical k‑means,” which is just a way to group items by how much they point in the same direction (cosine similarity). You can think of it as “which items share the same vibe.”
- Give each expert a focused skill based on a cluster
- Each expert is initialized to be good at its assigned cluster. They use a tool called truncated SVD to do this.
- Truncated SVD in simple terms: imagine compressing a complex pattern into its most important directions, like summarizing a long song into its main melody. This keeps the key information that matters for that cluster while removing less important details.
- This makes every expert start with a different focus, breaking the “everyone looks the same” problem.
- Start the router with smart instincts
- The router is initialized using the cluster centers (the “average” point of each group). This means the receptionist starts with a good idea of which expert to choose for each kind of input, instead of guessing.
Helper for stable learning: Expert‑Ensemble Self‑Distillation (EESD)
- Sometimes the router isn’t sure which expert to pick (it gives almost equal chances). To help, the authors create a “teacher” that combines the wisdom of all experts smoothly (an ensemble) and updates slowly over time (like a calm coach).
- The student (the normal MoE that picks only top‑k experts) learns to match this teacher’s output more closely when it’s unsure. This keeps training stable and nudges experts to stay specialized.
What they found and why it matters
The authors tested their method on CLIP models (ViT‑B/32 and ViT‑B/16), which connect images and text and are widely used for tasks like image search and classification. They compared against other ways to convert dense models into MoEs.
Key results:
- Better accuracy with the same or less compute: The new method consistently beats existing upcycling methods on zero‑shot (no extra training), few‑shot (very little training), and standard benchmarks like ImageNet and MSCOCO.
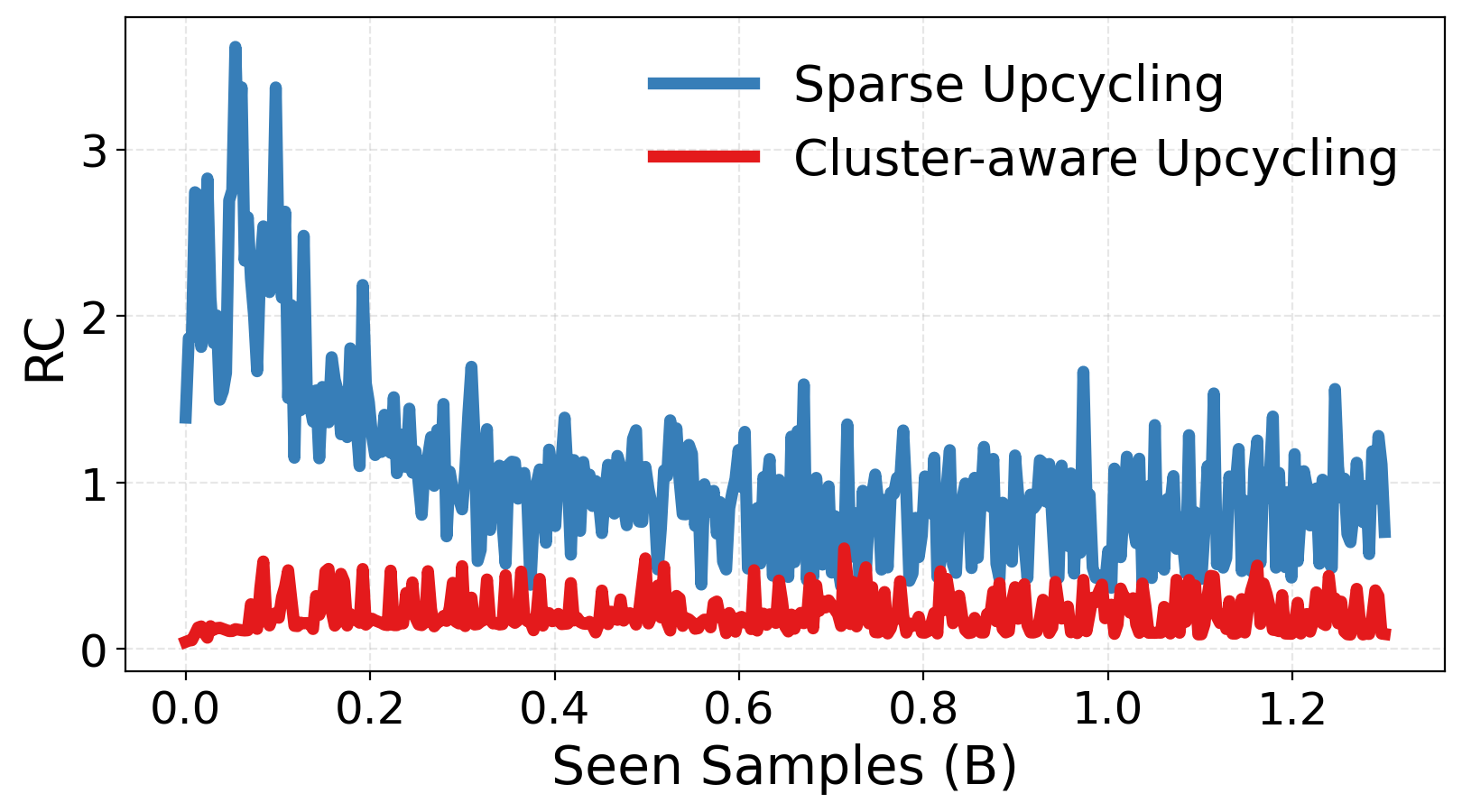
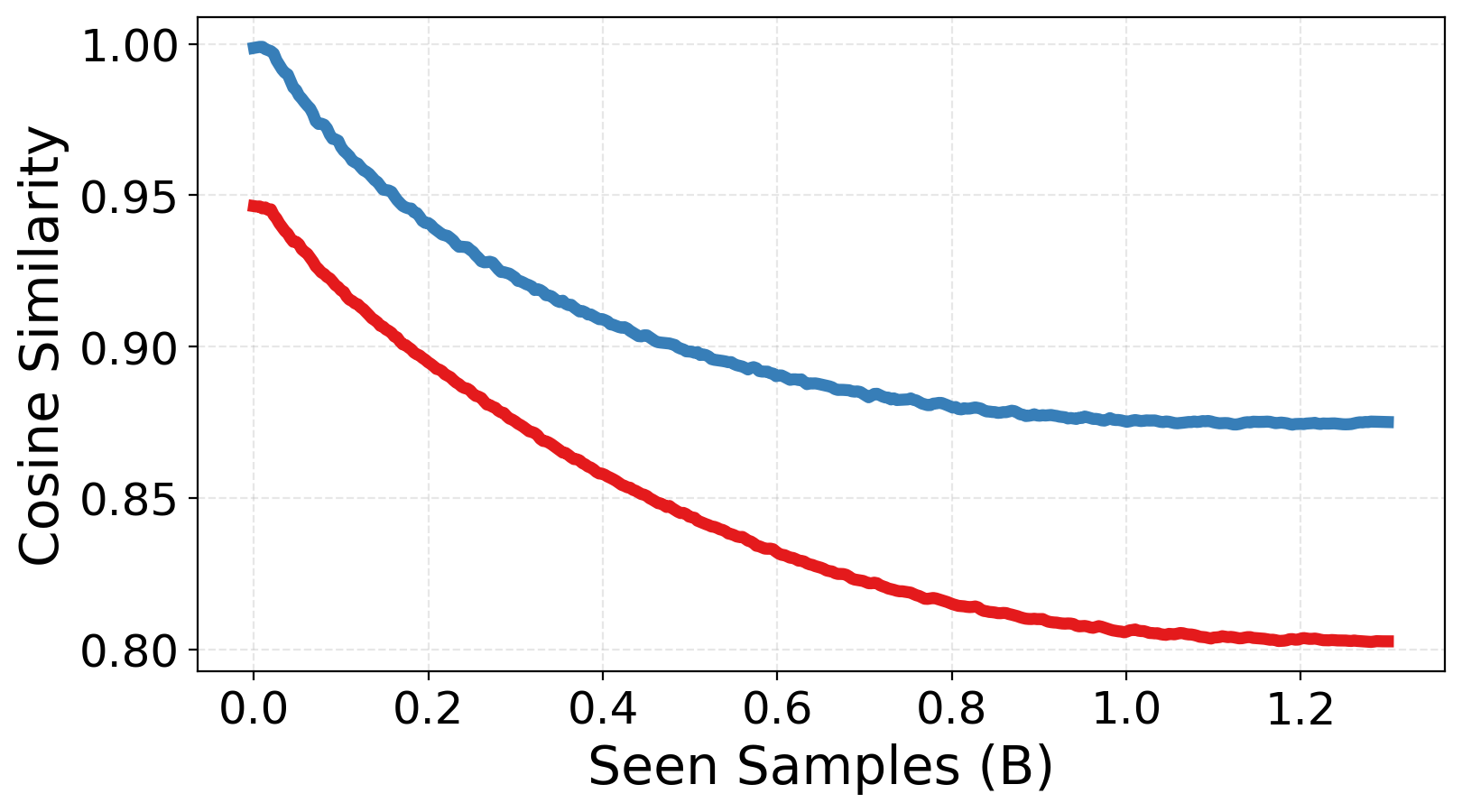
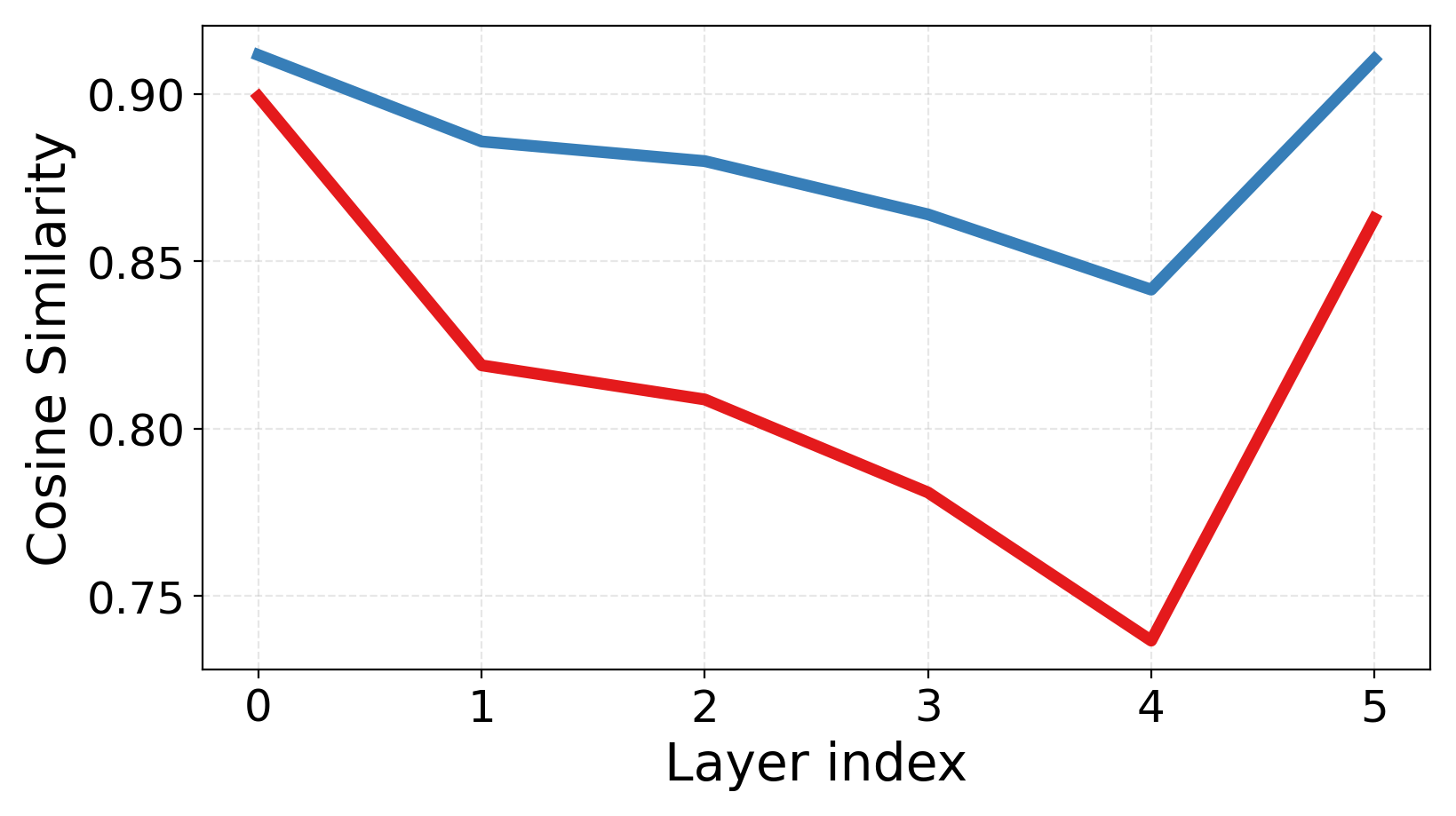
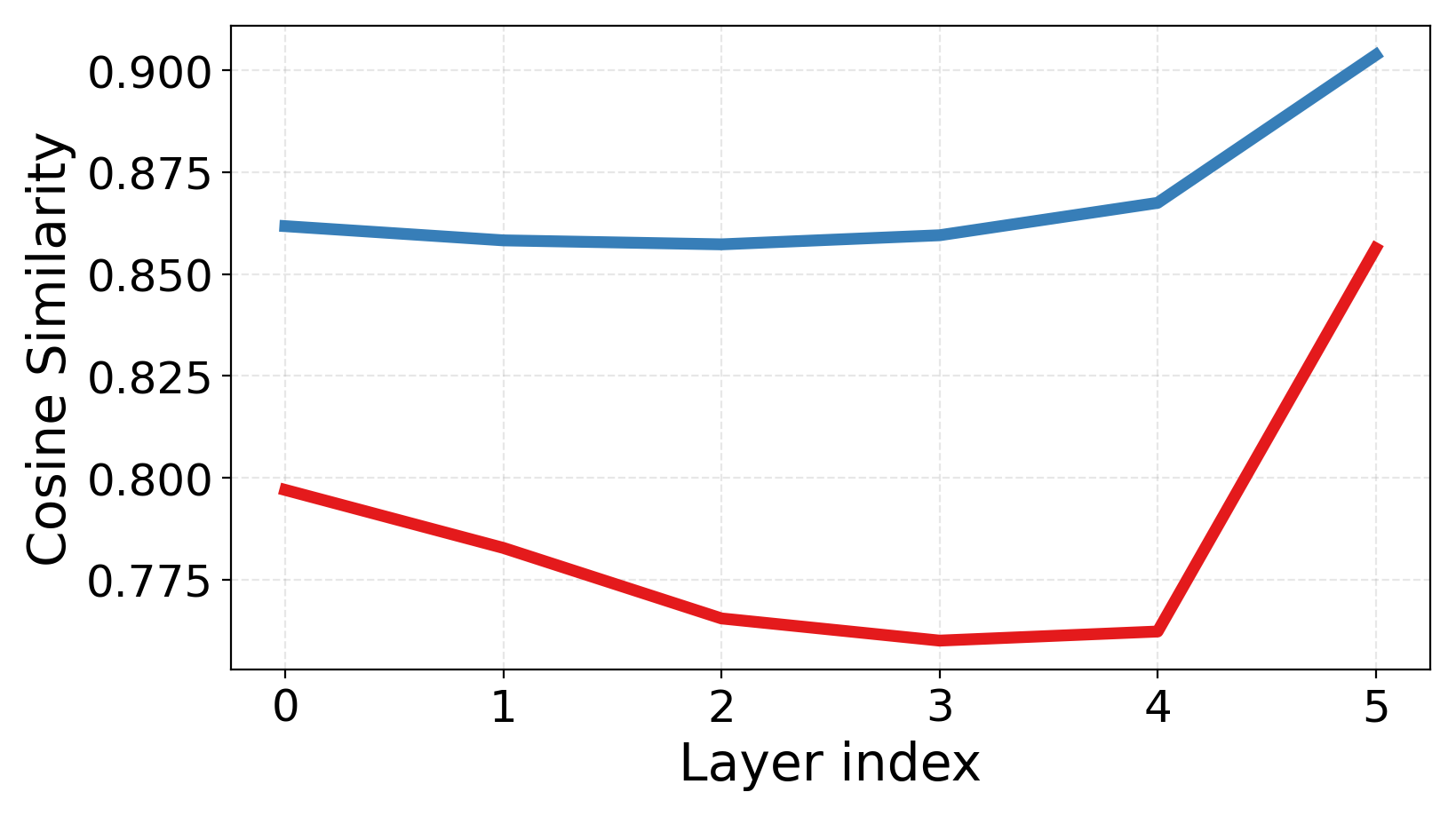
- Experts actually specialize: The experts become more different from each other (lower similarity), and their “skill spaces” overlap less. This means the team covers more ground without redundancy.
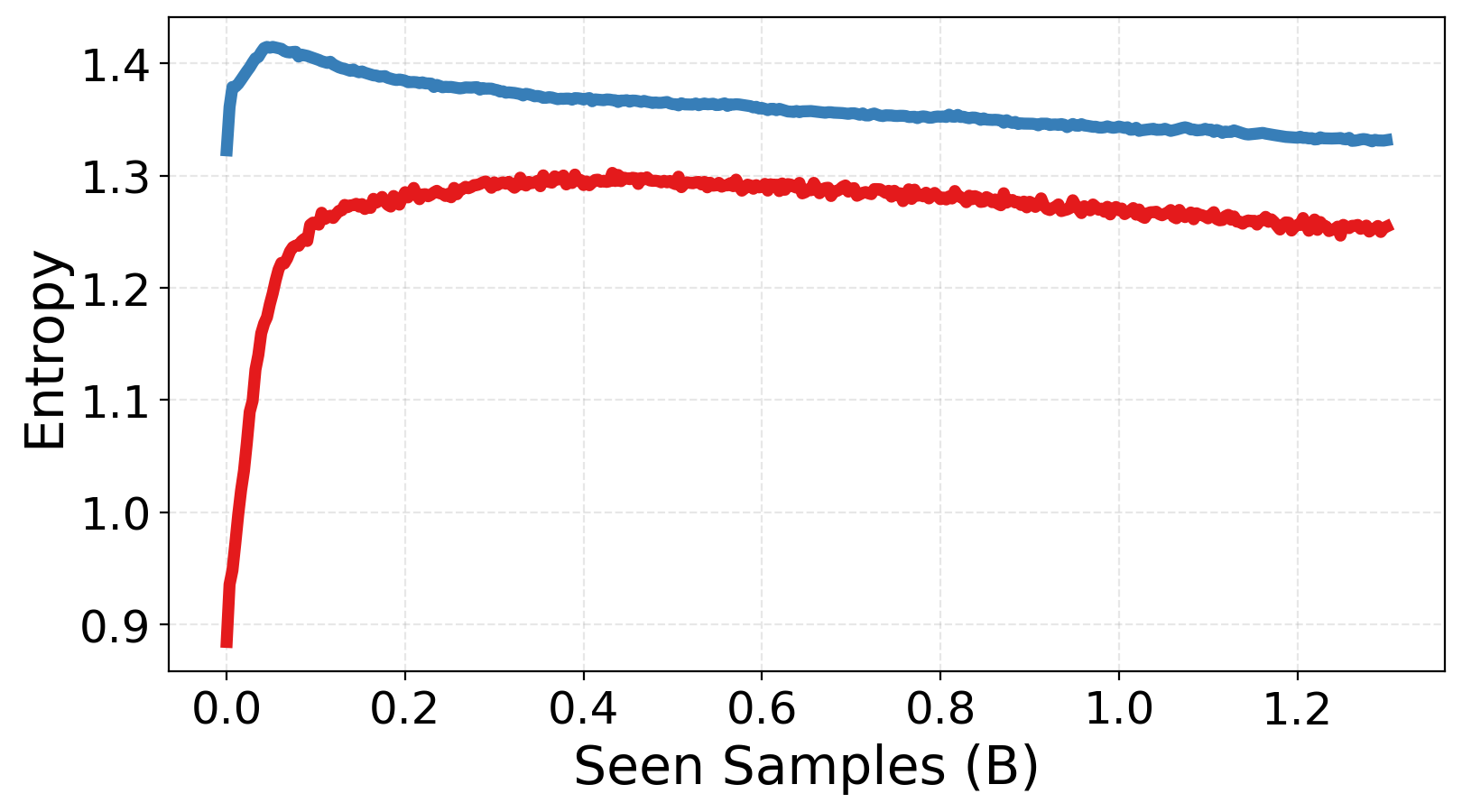
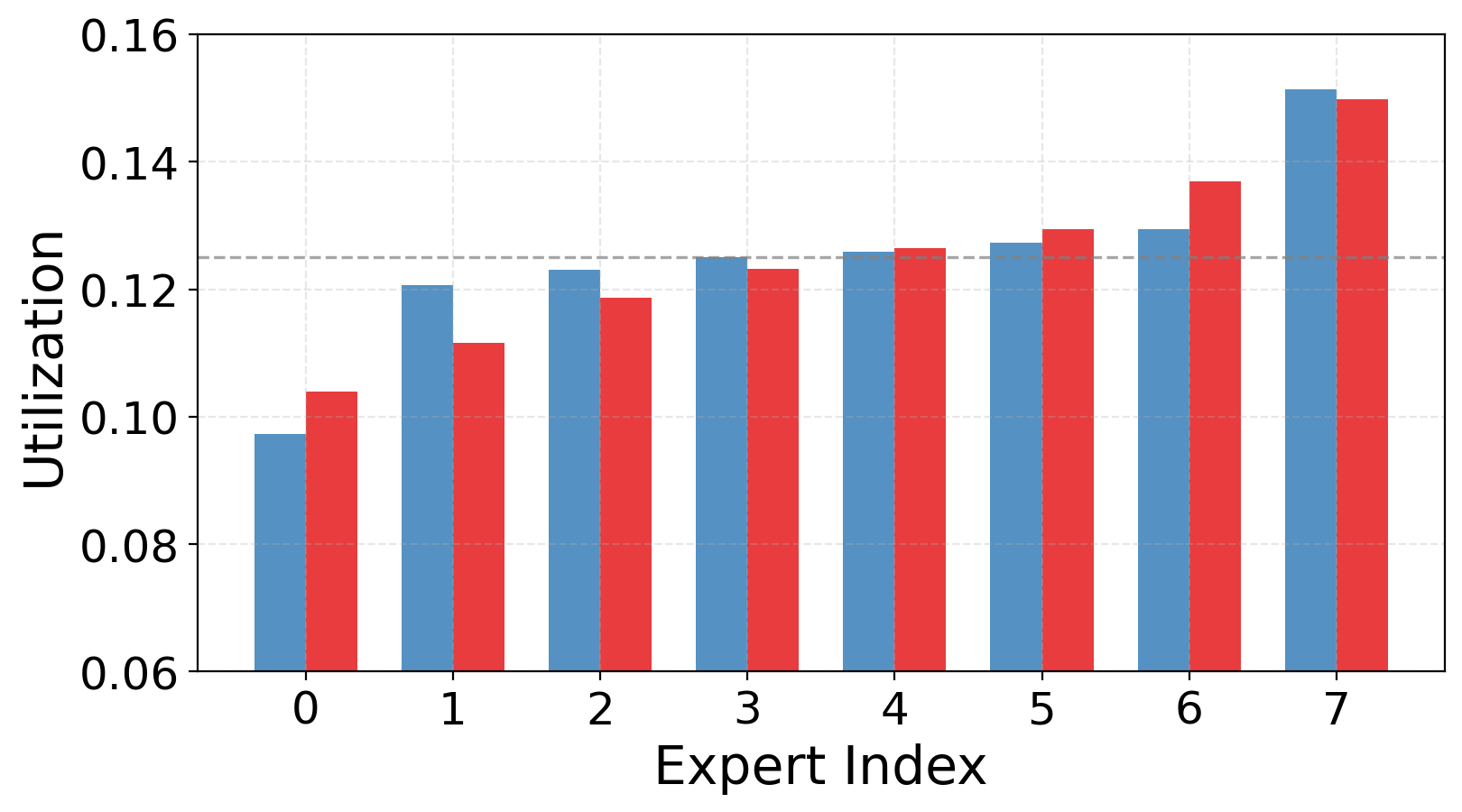
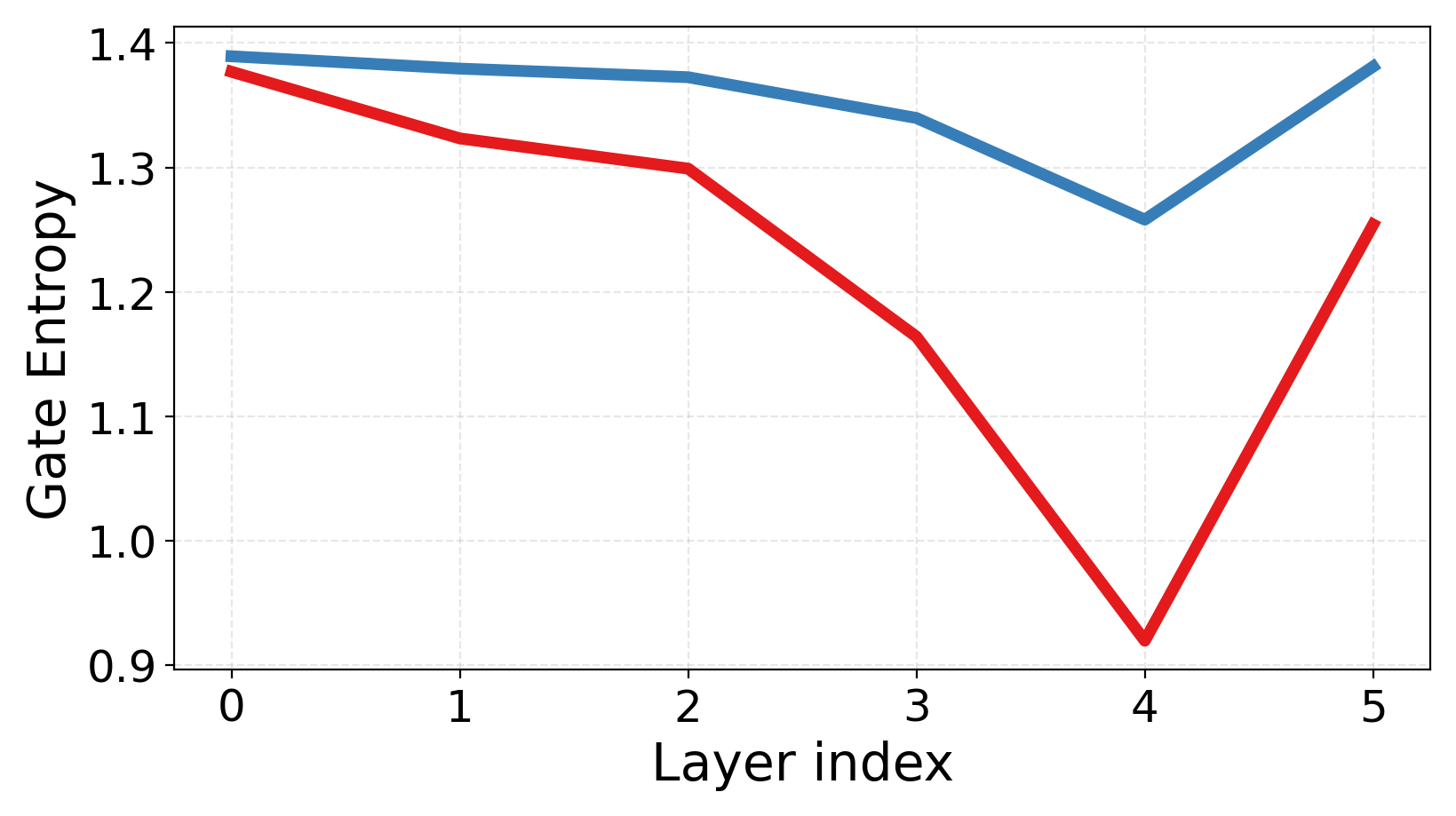
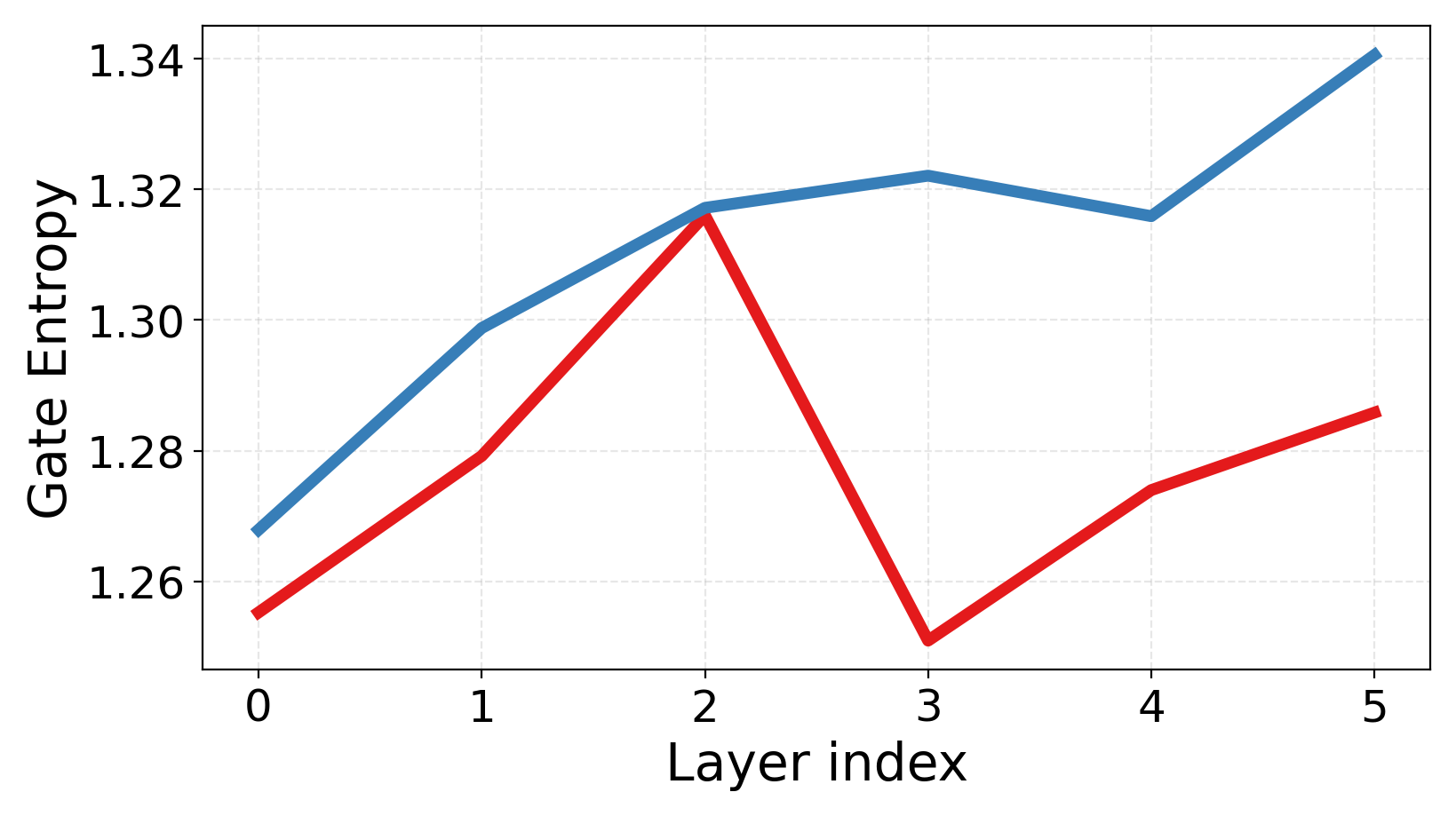
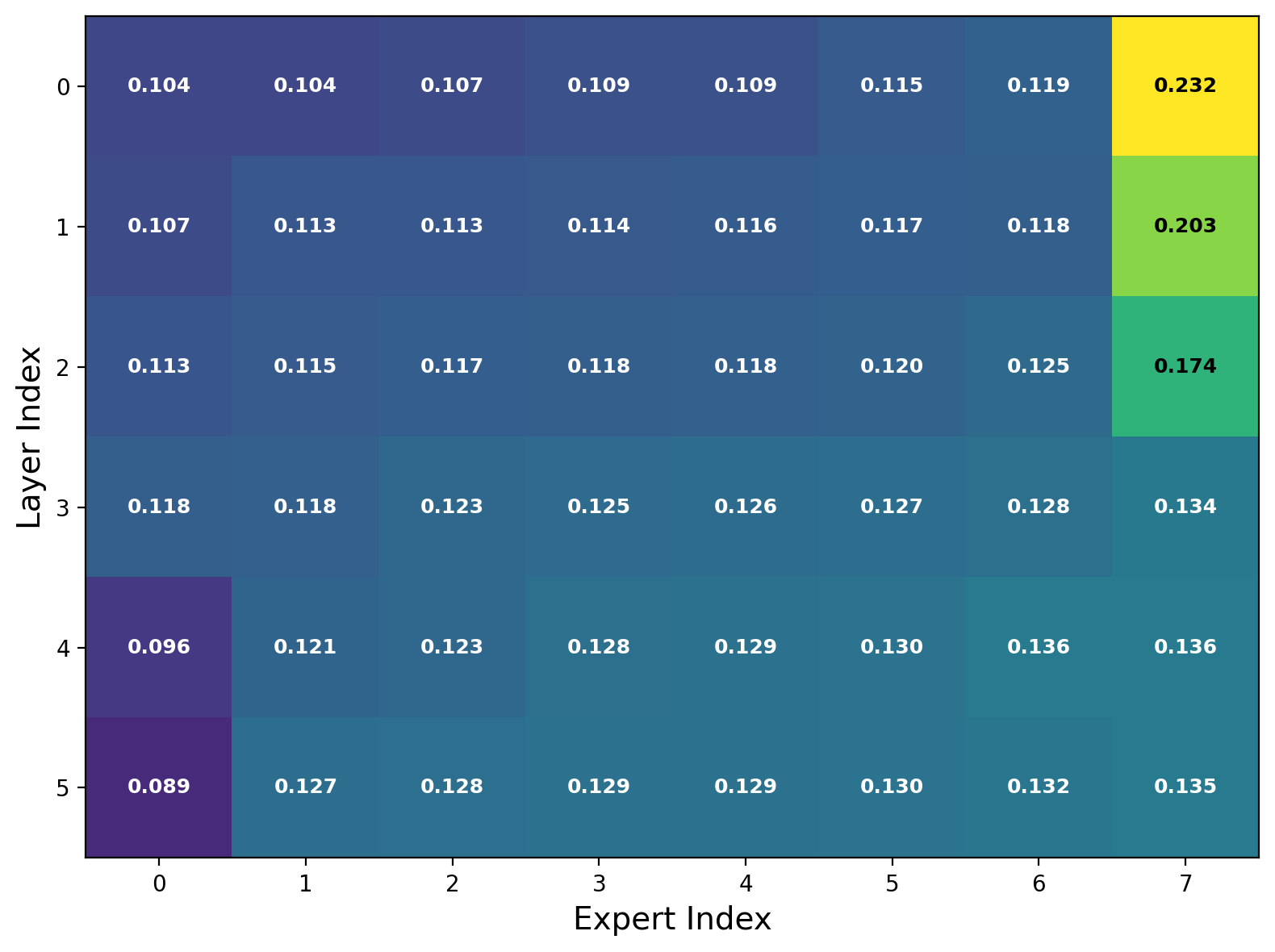
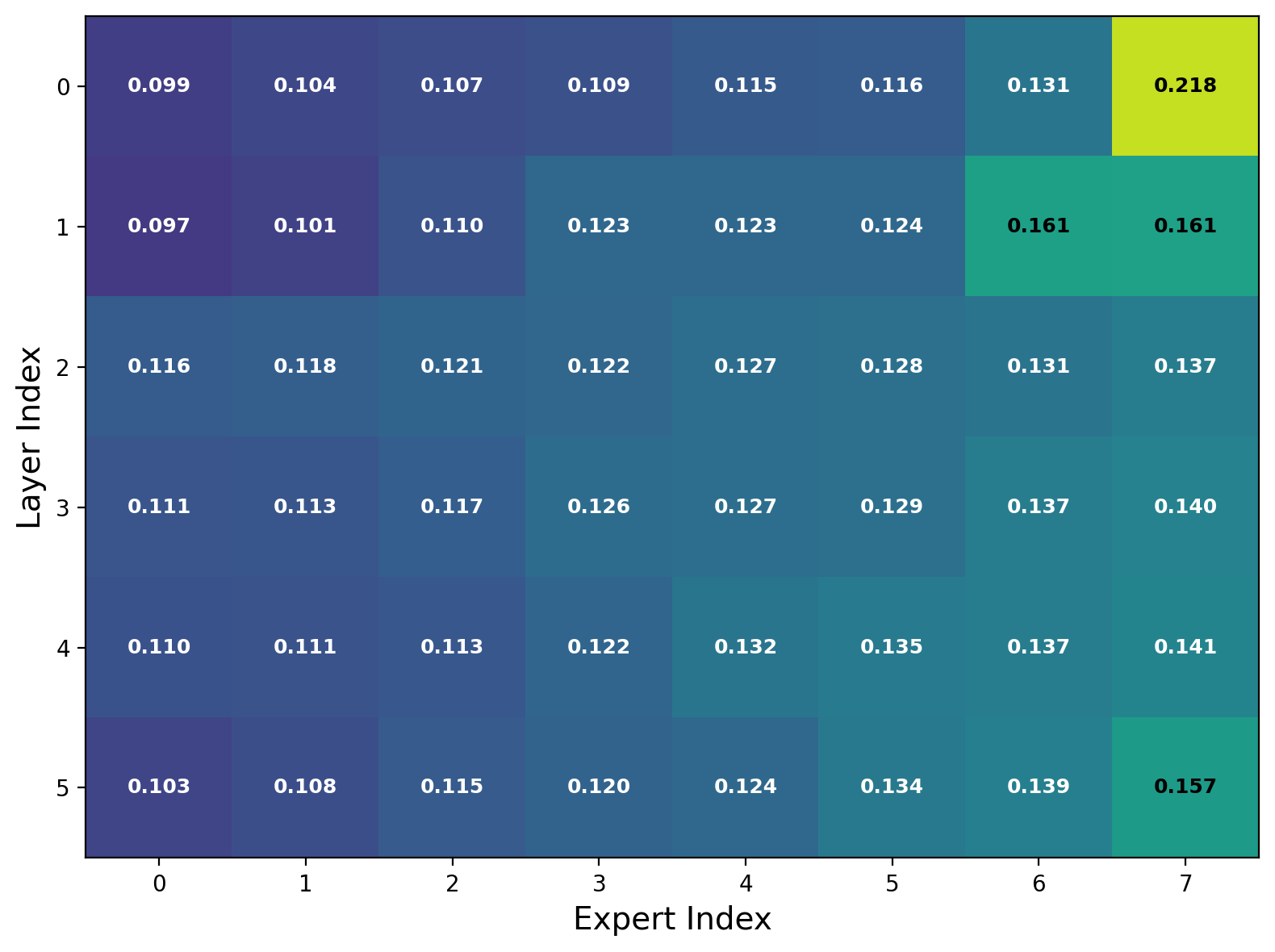
- Routing gets more confident and balanced: The router makes clearer choices (lower uncertainty) and spreads work across experts without collapsing onto just a few.
- Stronger few‑shot learning: The advantages are especially clear when you have little labeled data, which is important in real‑world settings.
Why it matters:
- You don’t need to train a giant MoE from scratch (which is very expensive). You can reuse a strong dense model, add experts smartly, and get better performance efficiently.
- This leads to better generalization (doing well on new, different data) and more stable training.
What this could mean going forward
- More efficient big models: This approach helps large AI systems scale their abilities without scaling their compute costs as much. That’s good for speed, cost, and energy use.
- Faster, safer specialization: Giving experts a clear starting role makes training smoother and avoids messy trial‑and‑error where everyone starts the same.
- Broad use beyond images and text: Although tested on CLIP (vision‑language), the idea—use the dense model’s own “semantic map” to seed experts and guide routing—could work for language‑only, vision‑only, or other multimodal models.
- Better performance with limited data: Since the method shines in zero‑shot and few‑shot settings, it can help in situations where labeled data is scarce.
In short: The paper shows a practical way to turn a regular model into a well‑organized team of specialists by using the model’s existing knowledge to assign roles and teach good routing from the start. This makes big models smarter, faster, and more efficient.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves several aspects uncertain or unexplored; the most actionable gaps for future work are:
- Sensitivity to clustering design: How performance depends on the clustering algorithm (spherical k-means vs. k-means, GMMs, spectral/DBSCAN), distance metric (cosine vs. Euclidean), PCA pre-reduction ratio, initialization, and random seed is not analyzed.
- Choice and size of calibration data: The method clusters activations from 128K in-distribution samples; the minimum sample size needed, effects of sampling bias/long-tail imbalance, and robustness under domain shift (calibration data ≠ training/deployment distribution) are not evaluated.
- Number of clusters vs. experts: The paper sets the number of clusters to the number of experts; it remains unclear how over-/under-clustering (clusters ≠ experts) affects specialization, load balancing, and routing stability.
- Layer and activation selection: Only FFN input activations are clustered; the impact of clustering other representations (e.g., attention outputs, intermediate blocks, post-FFN activations) or multi-layer joint clustering is not explored.
- Scope of expert initialization: Cluster-aware initialization is applied only to the first FFN linear layer; whether extending to the second FFN layer, both layers jointly, or additional modules (e.g., attention, router biases) improves outcomes is untested.
- Data-aware truncated SVD details: Numerical stability (e.g., low-rank XiXiᵀ, conditioning, ε-regularization), choice of τ (retained spectral energy) and its schedule, the hard lower bound on rank (≥ half of full rank), and their impact on performance and diversity are not systematically ablated.
- Computational cost of initialization: The wall-clock and memory overhead of PCA, per-layer clustering, whitening, and per-cluster SVD at scale (more layers, larger hidden sizes, more experts) is not quantified; approximate or incremental alternatives (randomized SVD, sketching) are not examined.
- Router initialization nuances: Using unit-norm centroids as rows of W_r (no bias/temperature) may yield overly sharp or under-confident routing; the effects of adding bias terms, temperature scaling, normalization schemes, or entropy-targeted schedules are not studied.
- Interaction with routing strategy: Results are shown for token-choice, top-2 routing; generality to expert-choice, top-1/top-4, Switch-style gating, entmax gating, or auxiliary-loss–free routes is not evaluated.
- Load balancing trade-offs: Only a single λ_lb is used; how load-balancing weight, capacity factor, and overflow handling interact with cluster-aware initialization (risk of dead experts or over-regularization) is untested.
- EESD design choices: The teacher is a dense EMA that activates all experts; alternatives (e.g., routing-distribution distillation, KL vs. L2 losses, confidence-weighted distillation, per-layer vs. end-to-end targets, scheduled λ_EESD) and their effects on specialization vs. convergence are not compared.
- Placement of EESD: It is not precisely specified at which representation(s) the EESD L2 loss is applied (layer outputs vs. model logits/features), nor whether applying it at multiple layers improves stability.
- EESD’s bias toward dense behavior: Whether a dense teacher nudges the student toward dense-like solutions (reducing sparsity benefits or expert diversity) and how this trade-off evolves with training is not analyzed.
- Scalability of EESD: Overhead is reported modest for ViT-B; feasibility with many more experts, deeper MoE insertions, or larger backbones (compute/memory implications of dense-teacher forward passes) is unclear.
- Convergence dynamics: Although qualitative trends are shown, there is no quantitative analysis of convergence speed, sample efficiency, or early-training instability vs. Sparse Upcycling under matched budgets.
- Robustness to weak or ambiguous cluster structure: The method assumes semantically coherent clusters; behavior when activations lack clear separation, are highly overlapping, or produce imbalanced clusters (and strategies to re-balance or merge/split) is not explored.
- Cross-layer cluster consistency: Clusters are computed per layer, but alignment of “semantics” across layers (e.g., whether the same tokens are routed consistently) and whether cross-layer cluster matching improves stability are untested.
- Expert capacity heterogeneity: All experts have identical capacity; whether allocating rank or width proportionally to cluster “energy,” size, or difficulty improves performance is an open question.
- MoE placement strategy: Only “every other FFN” is replaced; the impact of MoE insertion depth, density (all FFNs vs. subset), and per-layer expert counts on the benefits of cluster-aware initialization is not ablated.
- Generality beyond CLIP vision encoders: The approach is only demonstrated on CLIP ViT-B/32 and ViT-B/16 (vision encoders); application to text encoders, full multimodal stacks, language-only MoEs, and generative LLMs is not validated.
- Task and dataset breadth: Zero-/few-shot gains are reported on a limited set of benchmarks; behavior on long-tailed distributions, robustness tests (corruptions, adversarial), reasoning-heavy tasks, or different pretraining corpora remains unknown.
- Hyperparameter sensitivity: Sensitivity to key knobs (number of experts, top-k, τ for SVD, λ_EESD, β for EMA, λ_lb, capacity factor, centroid normalization) is not systematically characterized.
- Statistical reliability: Variance across runs, confidence intervals, and statistical significance of reported improvements are not provided.
- Interpretability and specialization validation: While diversity metrics are reported, explicit mapping between learned experts and semantic clusters/tasks (e.g., per-expert token/class distributions over time) is not shown.
- Failure mode analysis: Cases where cluster-aware initialization underperforms (e.g., noisy calibration, severe domain shift, highly imbalanced clusters, poor k-means convergence) are not identified, nor are mitigation strategies (robust clustering, outlier handling).
- Compatibility with other MoE techniques: Interactions with orthogonality constraints, expert regularizers, dynamic-k routing, hierarchical MoE, shared-base low-rank experts, or reinforcement-learning–phase distillation are not evaluated.
- Inference-time behavior: Effects on latency, memory, and cache behavior at inference (especially with lower routing entropy or different capacity factors) and any trade-offs with accuracy are not measured.
- Comparison to from-scratch MoE: While upcycling is the focus, the gap to MoEs trained from scratch at similar compute (and whether cluster-aware init closes that gap) is not reported.
Practical Applications
Immediate Applications
The following use cases can be deployed with current tooling, given access to a pretrained dense model and a representative calibration dataset for clustering.
- CLIP-based image–text retrieval upgrades
- Sector: software, media, e-commerce, search
- Use case: Upcycle existing CLIP ViT-B/16 or B/32 checkpoints to MoE using Cluster-aware Upcycling to boost zero-shot and few-shot retrieval and classification (e.g., catalog search, media library search, cross-modal recommendation).
- Potential products/workflows: “CLIP-MoE Upgrader” pipeline—(1) collect activations on a calibration set, (2) PCA + spherical k-means (Faiss), (3) data-aware truncated SVD to initialize experts, (4) initialize router with centroids, (5) short MoE fine-tuning with EESD, (6) deploy with DeepSpeed-MoE.
- Assumptions/dependencies: representative calibration data aligned with deployment distribution; access to model activations; MoE runtime (e.g., DeepSpeed-MoE) with top-k routing; ~5% extra training compute/memory for EESD; monitoring for drift.
- Cost- and energy-efficient model scaling via upcycling
- Sector: AI infrastructure, cloud platforms, enterprise MLOps
- Use case: Convert dense Transformer FFNs to MoE to increase capacity without proportional inference cost; cluster-aware initialization preserves performance while reducing training compute vs. training MoE from scratch.
- Potential tools: DeepSpeed-MoE, PyTorch/JAX, Faiss for clustering, SVD backends (cuSOLVER, PyTorch SVD).
- Assumptions/dependencies: MoE-compatible serving; capacity and batch-size tuning; load-balancing coefficients; hardware support for sparse routing and all-to-all.
- Production MoE stabilization and monitoring
- Sector: MLOps/DevOps
- Use case: Use the paper’s analysis metrics to monitor MoE health and prevent expert collapse: relative compactness (RC), inter-expert similarity, routing entropy, expert utilization.
- Potential products/workflows: dashboard for RC and routing entropy; alarms on expert similarity spikes; periodic re-clustering/refresh under drift.
- Assumptions/dependencies: access to token-level routing stats; privacy-managed sampling for monitoring.
- Domain-agnostic specialization without manual partitioning
- Sector: enterprise AI, content platforms
- Use case: Obtain early expert specialization by clustering latent activations rather than hand-defining domains; reduces operator effort and scales to many experts.
- Potential workflows: automatic cluster discovery per MoE layer, centroid-based router initialization, light fine-tuning; apply to new media/content domains with few-shot labels.
- Assumptions/dependencies: calibration data reflects latent semantic structure; periodic refresh if content shifts.
- Academic research enablement
- Sector: academia
- Use case: Reproducible initialization for studying MoE specialization; ablation-ready knobs (number of experts, clustering granularity, EESD strength); standardized metrics for geometry of expert subspaces.
- Potential tools: open-source reference implementations for cluster-aware init + EESD; benchmark on CLIP-Benchmark tasks.
- Assumptions/dependencies: availability of pretrained dense baselines and compute to run upcycling.
- Improved personal and enterprise media organization
- Sector: consumer software, productivity
- Use case: Better zero-shot tagging and search in photo-management or digital asset management apps due to stronger CLIP-like encoders after upcycling.
- Potential products: “smart album” creation, cross-modal queries (“find slides about battery safety with charts”), semantically coherent routing yields more confident results.
- Assumptions/dependencies: non-sensitive calibration data or on-device activation sampling; privacy controls.
- Low-data adaptation for specialized domains
- Sector: finance, legal, internal knowledge management
- Use case: Few-shot improvements enhance document/image–text retrieval and classification in low-label settings (e.g., slide decks, scanned reports).
- Potential workflows: upcycle general CLIP to MoE, then few-shot tune on small labeled sets; deploy internally.
- Assumptions/dependencies: domain shift must be moderate; validate bias/fairness in sensitive settings.
Long-Term Applications
These use cases require further research, engineering, or domain validation beyond the paper’s demonstrated scope.
- Language-model MoE upcycling with cluster-aware routing
- Sector: software/AI infrastructure, NLP
- Use case: Apply activation clustering to token/hidden states in LLMs to initialize experts and routers, reducing training cost while preserving capabilities.
- Potential products/workflows: LLM MoE upcycler for Megatron/DeepSpeed-MoE; hierarchical routers initialized from multi-scale clusters.
- Assumptions/dependencies: adapting spherical k-means to language token distributions; careful calibration datasets; sequence-level routing effects; evaluation on safety and factuality.
- Continual and dynamic MoE systems
- Sector: online services, recommendation, search
- Use case: Periodically re-cluster activations under distribution drift, add/swap experts, and refresh routers to maintain specialization without downtime.
- Potential tools: “live upcycling” service; drift detection feeding re-clustering and hot-swappable expert modules.
- Assumptions/dependencies: safe online updates; state consistency; A/B testing; guardrails to avoid catastrophic routing shifts.
- Edge/on-device specialization with hybrid deployment
- Sector: mobile, robotics, IoT
- Use case: Keep total capacity large but activate only local experts for low-latency inference; route to cloud experts when needed.
- Potential products: split MoE deployments (edge experts for common semantics; cloud experts for tail cases).
- Assumptions/dependencies: robust routing under bandwidth constraints; privacy-preserving activation logging for clustering; lightweight MoE runtimes.
- Domain-critical applications (e.g., healthcare, autonomous systems)
- Sector: healthcare, robotics, safety-critical
- Use case: More confident, disentangled experts may aid robustness and interpretability; could improve zero-/few-shot recognition in niche medical or industrial imagery.
- Potential workflows: rigorously validated domain-specific calibration datasets; clinical-grade evaluation; explanation interfaces showing expert assignments.
- Assumptions/dependencies: stringent validation, regulatory approval, bias assessment; model uncertainty calibration; provenance of training data.
- Policy and sustainability frameworks for efficient scaling
- Sector: public policy, ESG, sustainability
- Use case: Promote upcycling-based scaling as a lower-carbon alternative to training MoE from scratch; define reporting standards for efficiency gains and energy use.
- Potential tools: carbon accounting modules integrated into MLOps; benchmarks comparing dense-to-MoE upcycling vs. full training.
- Assumptions/dependencies: auditable telemetry; standardized energy reporting; sector buy-in.
- Tooling standardization for MoE health and initialization
- Sector: ML tooling ecosystem
- Use case: First-class support in frameworks for cluster-aware init and EESD; built-in metrics (RC, inter-expert similarity, routing entropy) and autoconfig of clustering rank thresholds.
- Potential products: library modules for PyTorch/JAX/TF; DeepSpeed/Megatron plugins; config templates.
- Assumptions/dependencies: community validation across modalities (vision, speech, language, multimodal); benchmarks for generalization.
- Automated domain-aware router/expert design
- Sector: AutoML
- Use case: AutoML systems that search number of experts, cluster granularity, and truncation thresholds to optimize for task performance and compute budget.
- Potential products: cost-aware NAS for MoE upcycling; hyperparameter services that co-optimize EESD strength and load balancing.
- Assumptions/dependencies: reliable surrogate metrics; scalable search; safeguards against overfitting cluster structure to transient data.
Notes on feasibility across applications:
- The method assumes the presence of FFN-style layers replaceable by MoE with dot-product routers; different architectures may need adaptations.
- Calibration data quality strongly influences cluster centroids; drift degrades routing alignment—plan for periodic recalibration.
- EESD adds modest training overhead (~5% wall-clock, ~3% memory reported); budget accordingly.
- Legal/ethical considerations apply when reusing pretrained weights and collecting activation statistics; ensure licensing and privacy compliance.
Glossary
- Activation manifold: The geometric structure of a model’s activation space that captures semantic relationships, used to guide initialization. "we leverage its activation manifold to initialize experts into distinct subspaces while faithfully preserving pretrained knowledge."
- Calibration dataset: A small dataset representative of the training distribution used to extract activations for initialization or analysis. "using a small calibration dataset that represents the training distribution."
- Capacity factor: A scaling parameter that sets how many tokens an expert can process relative to average load in MoE routing. "The capacity factor is set to 1.5 for MoE layers in the B/16 model and 2.0 in the B/32 model during training, and 2.0 for both at inference."
- Cholesky decomposition: A matrix factorization for symmetric positive-definite matrices, used here to compute whitening matrices from activation covariances. "obtained by Cholesky decomposition"
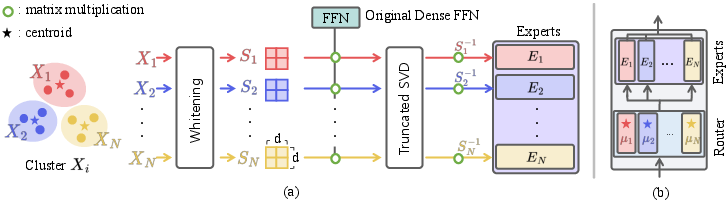
- Cluster-aware Upcycling: An MoE initialization strategy that uses clustered activations to initialize experts and the router, breaking expert symmetry. "We propose Cluster-aware Upcycling, a strategy that incorporates semantic structure into MoE initialization."
- Cluster centroid: The mean (direction) of a cluster in the activation space, used to initialize router weights for aligned routing. "The router is initialized using the cluster centroids, ensuring that early routing decisions align with the underlying semantic structure of the data."
- Conditional computation: A computation scheme where only a subset of model components are activated per input, improving efficiency. "This conditional computation enables models to scale efficiently without a proportional increase in computational cost, particularly during inference."
- Contrastive loss: A learning objective that pulls matched pairs together and pushes mismatched pairs apart in representation space. "cross-entropy or contrastive loss,"
- Data-aware truncated SVD: Truncated SVD performed on whitened weights that account for cluster-specific input statistics, preserving principal directions under the data distribution. "we initialize expert parameters using a data-aware truncated SVD"
- DeepSpeed-MoE: A system/library for efficient MoE training and routing strategies at scale. "We use the DeepSpeed-MoE~\cite{rajbhandari2022deepspeed} implementation with token-choice, top-2 routing, and 8 experts per layer."
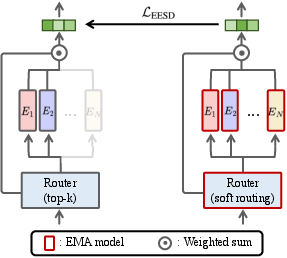
- Dense EMA ensemble: A teacher model that activates all experts using EMA parameters to provide stable supervision to the sparse MoE. "The dense EMA ensemble (right) performs soft routing over all experts and provides stable supervision for the sparse top- MoE model (left), particularly for tokens with high routing uncertainty."
- Disentangled subspaces: Expert representation subspaces that are geometrically independent with minimal overlap. "significantly lower inter-expert similarity and more disentangled subspaces---"
- Effective rank: The number of leading singular components needed to retain a chosen fraction of spectral energy. "The rank is defined as the effective rank of ,"
- EMA (exponential moving average): A parameter-averaging technique that stabilizes training by smoothing updates over time. "by applying exponential moving average (EMA) updates to the MoE parameters."
- Expert symmetry: The condition where all experts are initialized identically, hindering early specialization. "the model suffers from expert symmetry and limited early specialization."
- Expert utilization: The distribution of tokens across experts during routing, indicating how balanced or collapsed routing is. "Expert utilization patterns across experts, showing balanced routing without routing collapse."
- Expert-ensemble self-distillation (EESD): A distillation loss using a dense EMA teacher to guide sparse MoE predictions, especially under routing uncertainty. "we introduce an expert-ensemble self-distillation (EESD) loss"
- Faiss: A library for efficient similarity search and clustering at scale, used to implement spherical k-means. "spherical k-means clustering using Faiss~\cite{johnson2019billion}"
- Few-shot: Evaluation or training regimes with only a few labeled examples per class. "zero-shot and few-shot benchmarks."
- Inter-expert similarity: A measure of similarity between different experts’ parameters or representations, with lower values indicating better specialization. "reduces inter-expert similarity"
- Load-balancing loss: An auxiliary loss that encourages uniform expert usage and prevents dead experts. "The load-balancing loss coefficient $\lambda_{\text{lb}$ is set to 0.001."
- Mixture-of-Experts (MoE): An architecture that routes each input to a small subset of expert networks for computation. "Mixture-of-Experts (MoE) architectures offer a sparse alternative by activating only a subset of parameters for each input token"
- Patch dropout: A regularization technique for vision transformers that randomly drops image patches during training. "with patch dropout 0.5"
- PCA (Principal Component Analysis): A dimensionality reduction method used here to reduce activation dimensionality before clustering. "we reduce the activation dimensionality by a factor of eight using PCA,"
- Relative Compactness: A metric comparing within- and between-expert variance alignment; lower values imply more disentangled expert subspaces. "Relative Compactness measures the overlap between intra- and inter-expert variance, where lower values indicate more disentangled subspaces."
- Router: The gating network in MoE that produces routing probabilities over experts for each token. "A router, parameterized by , produces routing probabilities that dispatch each token across experts:"
- Routing entropy: A measure of uncertainty in the router’s probability distribution over experts. "Routing entropy captures routing uncertainty, with our model achieving lower entropy and more stable expert assignments."
- Sparse Upcycling: A warm-start approach that converts a dense model into an MoE by copying weights to all experts and training further. "Sparse Upcycling provides an efficient way to initialize a Mixture-of-Experts (MoE) model from pretrained dense weights"
- Spherical k-means: A clustering method on the unit sphere using cosine similarity, aligning with routing logits. "We utilize spherical -means clustering to partition the activation space based on cosine similarity,"
- Subspace representations: Low-dimensional linear structures associated with each cluster, used to initialize expert weights. "subspace representations of its corresponding cluster via truncated SVD,"
- Token-choice: A routing policy/configuration in MoE implementations that controls how tokens are assigned to experts. "with token-choice, top-2 routing, and 8 experts per layer."
- Top-2 routing: A routing strategy where each token is dispatched to the two experts with highest routing probabilities. "with token-choice, top-2 routing, and 8 experts per layer."
- Truncated SVD: A low-rank approximation retaining only the largest singular components to reduce dimensionality while preserving key structure. "Truncated SVD provides a principled low-rank approximation that preserves the leading singular components of a weight matrix."
- Whitening matrix: A linear transform that normalizes input statistics; here constructed from activation covariances for data-aware SVD. "a whitening matrix satisfying "
- Zero-shot: Evaluation without any task-specific fine-tuning, relying on pretrained knowledge. "zero-shot retrieval and classification benchmarks"
Collections
Sign up for free to add this paper to one or more collections.